resubPredict
Classify observations in multiclass error-correcting output codes (ECOC) model
Syntax
Description
label = resubPredict(Mdl)label) for the trained
multiclass error-correcting output codes (ECOC) model Mdl using the
predictor data stored in Mdl.X.
The software predicts the classification of an observation by assigning the observation to the class yielding the largest negated average binary loss (or, equivalently, the smallest average binary loss).
label = resubPredict(Mdl,Name,Value)
[
uses any of the input argument combinations in the previous syntaxes and additionally
returns the negated average binary loss per class
(label,NegLoss,PBScore]
= resubPredict(___)NegLoss) for observations, and the positive-class scores
(PBScore) for the observations classified by each binary
learner.
[
additionally returns posterior class probability estimates for observations
(label,NegLoss,PBScore,Posterior]
= resubPredict(___)Posterior).
To obtain posterior class probabilities, you must set
'FitPosterior',true when training the ECOC model using fitcecoc. Otherwise, resubPredict throws an error.
Examples
Load Fisher's iris data set. Specify the predictor data X, the response data Y, and the order of the classes in Y.
load fisheriris
X = meas;
Y = categorical(species);
classOrder = unique(Y);Train an ECOC model using SVM binary classifiers. Standardize the predictors using an SVM template, and specify the class order.
t = templateSVM('Standardize',true); Mdl = fitcecoc(X,Y,'Learners',t,'ClassNames',classOrder);
t is an SVM template object. During training, the software uses default values for empty properties in t. Mdl is a ClassificationECOC model.
Predict the labels of the training data. Print a random subset of true and predicted labels.
labels = resubPredict(Mdl); rng(1); % For reproducibility n = numel(Y); % Sample size idx = randsample(n,10); table(Y(idx),labels(idx),'VariableNames',{'TrueLabels','PredictedLabels'})
ans=10×2 table
TrueLabels PredictedLabels
__________ _______________
setosa setosa
versicolor versicolor
virginica virginica
setosa setosa
versicolor versicolor
setosa setosa
versicolor versicolor
versicolor versicolor
setosa setosa
setosa setosa
Mdl correctly labels the observations with indices idx.
Load Fisher's iris data set. Specify the predictor data X, the response data Y, and the order of the classes in Y.
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); % Class order
Train an ECOC model using SVM binary classifiers. Standardize the predictors using an SVM template, and specify the class order.
t = templateSVM('Standardize',true); Mdl = fitcecoc(X,Y,'Learners',t,'ClassNames',classOrder);
t is an SVM template object. During training, the software uses default values for empty properties in t. Mdl is a ClassificationECOC model.
SVM scores are signed distances from the observation to the decision boundary. Therefore, the domain is . Create a custom binary loss function that does the following:
Map the coding design matrix (M) and positive-class classification scores (s) for each learner to the binary loss for each observation.
Use linear loss.
Aggregate the binary learner loss using the median.
You can create a separate function for the binary loss function, and then save it on the MATLAB® path. Or, you can specify an anonymous binary loss function. In this case, create a function handle (customBL) to an anonymous binary loss function.
customBL = @(M,s)median(1 - (M.*s),2,'omitnan')/2;Predict labels for the training data and estimate the median binary loss per class. Print the median negative binary losses per class for a random set of 10 observations.
[label,NegLoss] = resubPredict(Mdl,'BinaryLoss',customBL); rng(1); % For reproducibility n = numel(Y); % Sample size idx = randsample(n,10); classOrder
classOrder = 3×1 categorical
setosa
versicolor
virginica
table(Y(idx),label(idx),NegLoss(idx,:),'VariableNames',... {'TrueLabel','PredictedLabel','NegLoss'})
ans=10×3 table
TrueLabel PredictedLabel NegLoss
__________ ______________ _______________________________
setosa versicolor 0.1236 1.9565 -3.5801
versicolor versicolor -1.0169 0.629 -1.1121
virginica virginica -1.9079 -0.21788 0.62583
setosa versicolor 0.43825 2.2437 -4.182
versicolor versicolor -1.0732 0.396 -0.82276
setosa versicolor 0.26653 2.1999 -3.9664
versicolor versicolor -1.1233 0.6988 -1.0755
versicolor versicolor -1.2708 0.51782 -0.747
setosa versicolor 0.35168 2.0674 -3.9191
setosa versicolor 0.2334 2.1882 -3.9216
The order of the columns corresponds to the elements of classOrder. The software predicts the label based on the maximum negated loss. The results indicate that the median of the linear losses might not perform as well as other losses.
Train an ECOC classifier using SVM binary learners. First predict the training-sample labels and class posterior probabilities. Then predict the maximum class posterior probability at each point in a grid. Visualize the results.
Load Fisher's iris data set. Specify the petal dimensions as the predictors and the species names as the response.
load fisheriris X = meas(:,3:4); Y = species; rng(1); % For reproducibility
Create an SVM template. Standardize the predictors, and specify the Gaussian kernel.
t = templateSVM('Standardize',true,'KernelFunction','gaussian');
t is an SVM template. Most of its properties are empty. When the software trains the ECOC classifier, it sets the applicable properties to their default values.
Train the ECOC classifier using the SVM template. Transform classification scores to class posterior probabilities (which are returned by predict or resubPredict) using the 'FitPosterior' name-value pair argument. Specify the class order using the 'ClassNames' name-value pair argument. Display diagnostic messages during training by using the 'Verbose' name-value pair argument.
Mdl = fitcecoc(X,Y,'Learners',t,'FitPosterior',true,... 'ClassNames',{'setosa','versicolor','virginica'},... 'Verbose',2);
Training binary learner 1 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 2 Positive class indices: 1 Fitting posterior probabilities for learner 1 (SVM). Training binary learner 2 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 1 Fitting posterior probabilities for learner 2 (SVM). Training binary learner 3 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 2 Fitting posterior probabilities for learner 3 (SVM).
Mdl is a ClassificationECOC model. The same SVM template applies to each binary learner, but you can adjust options for each binary learner by passing in a cell vector of templates.
Predict the training-sample labels and class posterior probabilities. Display diagnostic messages during the computation of labels and class posterior probabilities by using the 'Verbose' name-value pair argument.
[label,~,~,Posterior] = resubPredict(Mdl,'Verbose',1);Predictions from all learners have been computed. Loss for all observations has been computed. Computing posterior probabilities...
Mdl.BinaryLoss
ans = 'quadratic'
The software assigns an observation to the class that yields the smallest average binary loss. Because all binary learners are computing posterior probabilities, the binary loss function is quadratic.
Display a random set of results.
idx = randsample(size(X,1),10,1); Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
table(Y(idx),label(idx),Posterior(idx,:),... 'VariableNames',{'TrueLabel','PredLabel','Posterior'})
ans=10×3 table
TrueLabel PredLabel Posterior
______________ ______________ ______________________________________
{'virginica' } {'virginica' } 0.0039319 0.0039866 0.99208
{'virginica' } {'virginica' } 0.017066 0.018262 0.96467
{'virginica' } {'virginica' } 0.014947 0.015855 0.9692
{'versicolor'} {'versicolor'} 2.2197e-14 0.87318 0.12682
{'setosa' } {'setosa' } 0.999 0.00025091 0.00074639
{'versicolor'} {'virginica' } 2.2195e-14 0.059427 0.94057
{'versicolor'} {'versicolor'} 2.2194e-14 0.97002 0.029984
{'setosa' } {'setosa' } 0.999 0.0002499 0.00074741
{'versicolor'} {'versicolor'} 0.0085638 0.98259 0.0088482
{'setosa' } {'setosa' } 0.999 0.00025013 0.00074718
The columns of Posterior correspond to the class order of Mdl.ClassNames.
Define a grid of values in the observed predictor space. Predict the posterior probabilities for each instance in the grid.
xMax = max(X); xMin = min(X); x1Pts = linspace(xMin(1),xMax(1)); x2Pts = linspace(xMin(2),xMax(2)); [x1Grid,x2Grid] = meshgrid(x1Pts,x2Pts); [~,~,~,PosteriorRegion] = predict(Mdl,[x1Grid(:),x2Grid(:)]);
For each coordinate on the grid, plot the maximum class posterior probability among all classes.
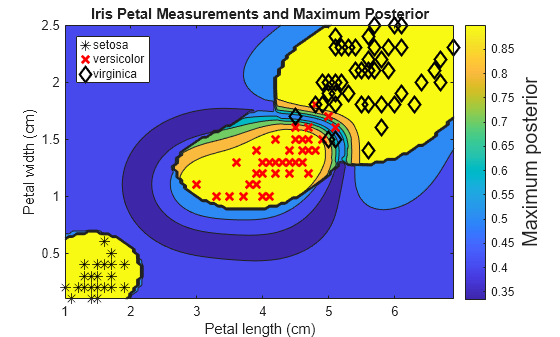
contourf(x1Grid,x2Grid,... reshape(max(PosteriorRegion,[],2),size(x1Grid,1),size(x1Grid,2))); h = colorbar; h.YLabel.String = 'Maximum posterior'; h.YLabel.FontSize = 15; hold on gh = gscatter(X(:,1),X(:,2),Y,'krk','*xd',8); gh(2).LineWidth = 2; gh(3).LineWidth = 2; title('Iris Petal Measurements and Maximum Posterior') xlabel('Petal length (cm)') ylabel('Petal width (cm)') axis tight legend(gh,'Location','NorthWest') hold off
Train a multiclass ECOC model and estimate the posterior probabilities using parallel computing.
Load the arrhythmia data set. Examine the response data Y, and determine the number of classes.
load arrhythmia
Y = categorical(Y);
tabulate(Y) Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
K = numel(unique(Y));
Several classes are not represented in the data, and many other classes have low relative frequencies.
Specify an ensemble learning template that uses the GentleBoost method and 50 weak classification tree learners.
t = templateEnsemble('GentleBoost',50,'Tree');
t is a template object. Most of its properties are empty ([]). The software uses default values for all empty properties during training.
Because the response variable contains many classes, specify a sparse random coding design.
rng(1); % For reproducibility Coding = designecoc(K,'sparserandom');
Train an ECOC model using parallel computing. Specify to fit posterior probabilities.
pool = parpool; % Invokes workersStarting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
options = statset('UseParallel',true); Mdl = fitcecoc(X,Y,'Learner',t,'Options',options,'Coding',Coding,... 'FitPosterior',true);
Mdl is a ClassificationECOC model. You can access its properties using dot notation.
The pool invokes six workers, although the number of workers might vary among systems.
Estimate posterior probabilities, and display the posterior probability of being classified as not having arrhythmia (class 1) given a random subset of the training data.
[~,~,~,posterior] = resubPredict(Mdl); n = numel(Y); idx = randsample(n,10,1); table(idx,Y(idx),posterior(idx,1),... 'VariableNames',{'ObservationIndex','TrueLabel','PosteriorNoArrythmia'})
ans=10×3 table
ObservationIndex TrueLabel PosteriorNoArrythmia
________________ _________ ____________________
79 1 0.93436
248 1 0.95574
398 10 0.032378
207 1 0.97965
340 1 0.93656
206 1 0.97795
345 10 0.015642
296 2 0.13433
391 1 0.9648
406 1 0.94861
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
Extended Capabilities
Version History
Introduced in R2014b