Cluster Analysis and Anomaly Detection
Cluster analysis, also called segmentation analysis or taxonomy analysis, partitions sample data into groups, or clusters. Clusters are formed such that objects in the same cluster are similar, and objects in different clusters are distinct. Statistics and Machine Learning Toolbox™ provides several clustering techniques and measures of similarity (also called distance metrics) to create the clusters. Additionally, cluster evaluation determines the optimal number of clusters for the data using different evaluation criteria. Cluster visualization options include dendrograms and silhouette plots.
Anomaly detection is a branch of machine learning that identifies observations that deviate from an expected pattern or distribution in sample data. Statistics and Machine Learning Toolbox provides several techniques for outlier and novelty detection (see Unsupervised Anomaly Detection), and additional methods for detecting anomalies in streaming data (see Incremental Anomaly Detection Overview).
Cluster Analysis Basics
Categories
- Hierarchical Clustering
Produce nested sets of clusters
- k-Means and k-Medoids Clustering
Cluster by minimizing mean or medoid distance, and calculate Mahalanobis distance
- Density-Based Spatial Clustering of Applications with Noise
Find clusters and outliers by using the DBSCAN algorithm
- Spectral Clustering
Find clusters by using graph-based algorithm
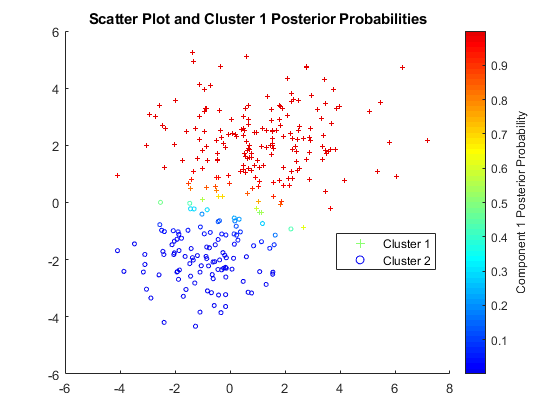
- Gaussian Mixture Models
Cluster based on Gaussian mixture models using the Expectation-Maximization algorithm
- Nearest Neighbors
Find nearest neighbors using exhaustive search or Kd-tree search
- Hidden Markov Models
Markov models for data generation
- Anomaly Detection
Detect outliers and novelties
- Cluster Visualization and Evaluation
Plot clusters of data and evaluate optimal number of clusters
- Python Model Coexecution
Load and coexecute Python machine learning models for prediction in Simulink
Featured Examples
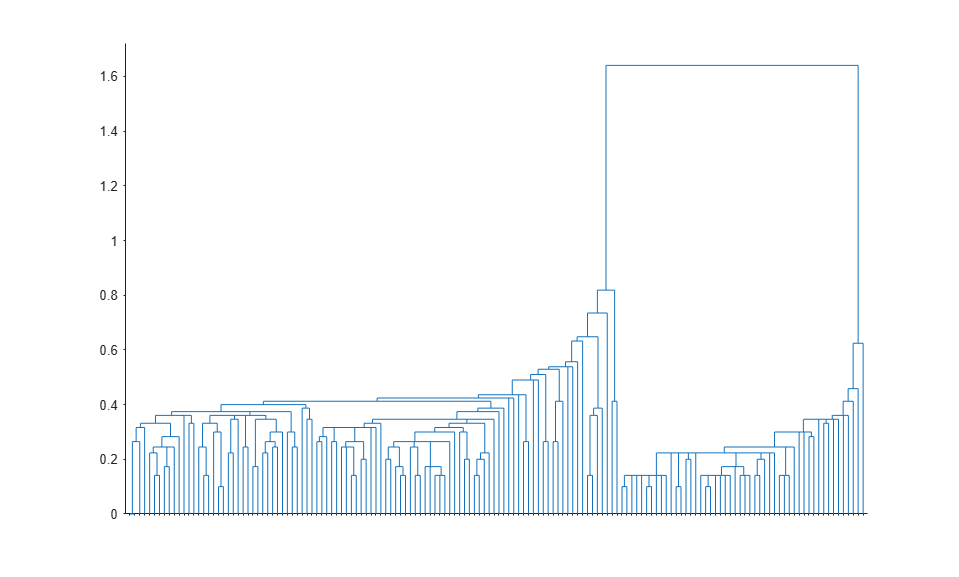
Cluster Analysis
Examine similarities and dissimilarities of observations or objects using cluster analysis in Statistics and Machine Learning Toolbox™. Data often fall naturally into groups (or clusters) of observations, where the characteristics of objects in the same cluster are similar and the characteristics of objects in different clusters are dissimilar.
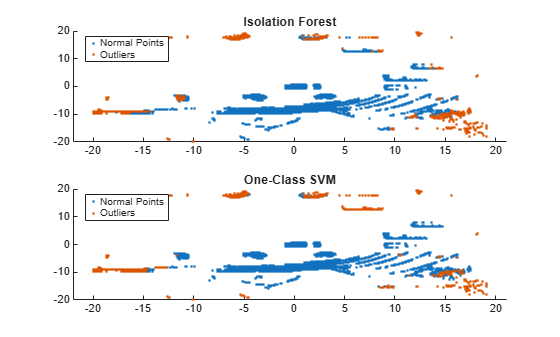
Code Generation for Anomaly Detection
Generate single-precision code that detects anomalies in data using a trained isolation forest model or one-class SVM.
Teaching Resources

Machine Learning Methods: Clustering
Learn the concepts of distance-based, density-based, and probabilistic algorithms for clustering data.