Detecting Oversteering in BMW Automobiles with Machine Learning
By Tobias Freudling, BMW Group
Oversteering is an unsafe condition in which a vehicle’s rear tires lose their grip while navigating a turn (Figure 1). It can be caused by worn tires, slippery road conditions, taking a turn too fast, braking abruptly while turning, or a combination of these factors.

Figure 1. Oversteering a BMW M4 on a test track.
Modern stability control systems are designed to automatically take corrective action when oversteer is detected. In theory, such systems can identify an oversteering condition by using mathematical models based on first principles. For example, when measurements from onboard sensors exceed established threshold values for parameters in the model, the system determines that the car is oversteering. In practice, however, this approach has proven difficult to implement because of the interplay of the many factors involved. A car with underinflated tires on an icy road might need vastly different threshold values than the same car operating with properly inflated tires on a dry surface.
At BMW, we are exploring a machine learning approach to detecting oversteering. Working in MATLAB®, we developed a supervised machine learning model as a proof of concept. Despite having little previous experience with machine learning, in just three weeks we completed a working ECU prototype capable of detecting oversteering with over 98% accuracy.
Collecting Data and Extracting Features
We began by gathering real-world data from a vehicle before, during, and after oversteering. With the help of a professional driver, we conducted live driving tests in a BMW M4 at the BMW proving grounds in Miramas, France (Figure 2).

Figure 2. The BMW proving grounds in Miramas, France.
During the tests, we captured signals commonly used in oversteer detection algorithms: the vehicle’s forward acceleration, lateral acceleration, steering angle, and yaw rate. In addition, we logged the driver’s perception of oversteering: When the driver indicated the car was oversteering, my colleague, riding in the car as a passenger, pressed a button on her laptop. She released the button when the driver indicated the car had returned to handling normally. These button presses created the ground-truth labels we need to train a supervised learning model. Altogether, we captured about 259,000 data points in 43 minutes of recorded data.
Back in our Munich office, we loaded the data that we had collected into MATLAB and used the Classification Learner app in Statistics and Machine Learning Toolbox™ to train machine learning models using a variety of classifiers. The results produced by models trained on this raw data were not outstanding—the accuracy was between 75% and 80%. To achieve more accurate results, we cleaned and reduced the raw data. First, we applied filters to reduce noise on the signal data (Figure 3).
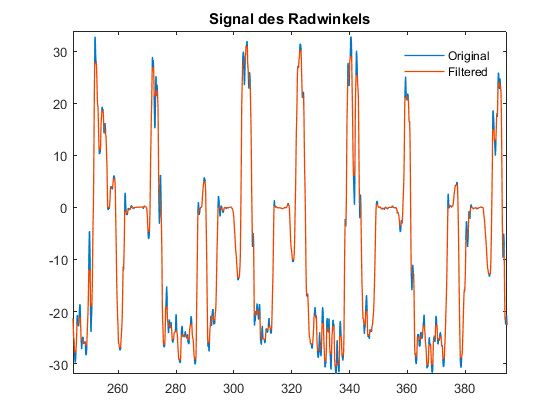
Figure 3. The original steering angle signal (blue) and the same signal after filtering (orange).
Next, we used peak analysis to identify the peaks (local maxima) on our filtered input signals (Figure 4).

Figure 4. The steering angle signal with peaks identified.
Evaluating Machine Learning Approaches
After filtering and reducing the collected data, we were in a better position to evaluate supervised machine learning approaches. Using the Classification Learner app, we tried k-nearest neighbor (KNN) classifiers, support vector machines (SVMs), quadratic discriminant analysis, and decision trees. We also used the app to see the effect of transforming features through principal component analysis (PCA), which helps prevent overfitting.
The results produced by the classifiers that we evaluated are summarized in Table 1. All the classifiers performed well in identifying oversteer, with three producing true positive rates above 98%. The deciding factor was the true negative rates: how accurately the classifier was able to determine when the vehicle was not oversteering. Here, decision trees outperformed the other classifiers, with a true negative rate of almost 96%.
| True Positive (%) | True Negative (%) | False Positive (%) | False Negative (%) | |
| K-Nearest Neighbor with PCA |
94.74 | 90.35 | 5.26 | 9.65 |
| Support Vector Machine | 98.92 | 73.07 | 1.08 | 26.93 |
| Quadratic Discriminant Analysis | 98.83 | 82.73 | 1.17 | 17.27 |
| Decision Trees | 98.16 | 95.86 | 1.84 | 4.14 |
Generating Code for In-Vehicle Tests
The results produced by the decision tree were promising, but the true test would be how well the classifier performed on an ECU in a real car. We generated code from the model with MATLAB Coder™ and compiled the code for our target ECU, installed in a BMW 5 Series sedan. This time, we conducted the tests ourselves at a BMW facility near Aschheim, close to our office. As I drove, my colleague collected data, recording the precise times when I indicated that the car was oversteering.
Running in real time on the ECU, the classifier performed surprisingly well, with an accuracy rate of about 95%. Going into the tests, we had not known what to expect because we were using a different vehicle (a BMW 5 Series instead of an M4), a different driver, and a different track. A closer look at the data revealed that most of the mismatches between the model and the driver’s perceived oversteering occurred near the beginning and end of the oversteering condition. This mismatch is understandable; it can be difficult even for a driver to determine exactly when oversteer has started and stopped.
Having successfully developed a machine learning model for oversteering detection and deployed it on a prototype ECU, we are now envisioning numerous other potential applications for machine learning at BMW. Vast amounts of data collected over decades are available to us, and today, a single vehicle can generate a terabyte of measured data in a day. Machine learning provides an opportunity to develop software that uses the available data to learn about a driver’s behavior and improve the driving experience.
Published 2018