Deep Learning for Audio Applications
Developing audio applications with deep learning typically includes creating and accessing data sets, preprocessing and exploring data, developing predictive models, and deploying and sharing applications. MATLAB® provides toolboxes to support each stage of the development.

While Audio Toolbox™ supports each stage of the deep learning workflow, its principal contributions are to Access and Create Data and Preprocess and Explore Data.
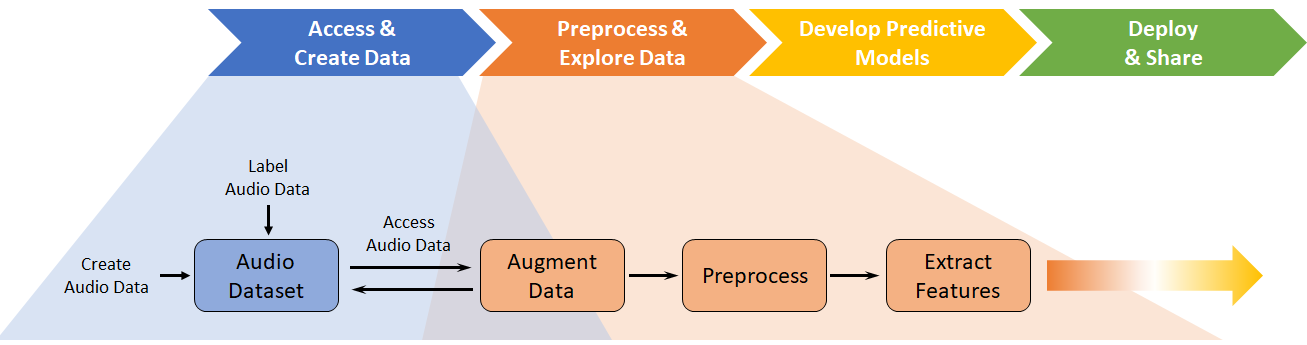
Access and Create Data
Deep learning networks perform best when you have access to large training data sets. However, the diversity of audio, speech, and acoustic signals, and a lack of large well-labeled data sets, makes accessing large training sets difficult. When using deep learning methods on audio files, you may need to develop new data sets or expand on existing ones. You can use the Signal Labeler app to help you enlarge or create new labeled data sets.
Once you have an initial data set, you can enlarge it by applying augmentation
techniques such as pitch shifting, time shifting, volume control, and noise
addition. The type of augmentation you want to apply depends on the relevant
characteristics for your audio, speech, or acoustic application. For example, pitch
shifting (or vocal tract perturbation) and time stretching are
typical augmentation techniques for automatic speech recognition (ASR). For
far-field ASR, augmenting the training data by using artificial reverberation is
common. Audio Toolbox provides audioDataAugmenter to help you apply augmentations deterministically
or probabilistically.
The training data used in deep learning workflows is typically too large to fit in
memory. Accessing data efficiently and performing common deep learning tasks (such
as splitting a data set into train, validation, and test sets) can quickly become
unmanageable. Audio Toolbox provides audioDatastore to help you manage and load large data sets.
Preprocess and Explore Data
Preprocessing audio data includes tasks like resampling audio files to a
consistent sample rate, removing regions of silence, and trimming audio to a
consistent duration. You can accomplish these tasks by using MATLAB, Signal Processing Toolbox™, and DSP System Toolbox™. Audio Toolbox provides additional audio-specific tools to help you perform
preprocessing, such as detectSpeech and voiceActivityDetector.
Audio is highly dimensional and contains redundant and often unnecessary
information. Historically, mel-frequency cepstral coefficients (mfcc) and low-level
features, such as the zero-crossing rate and spectral shape descriptors, have been
the dominant features derived from audio signals for use in machine learning
systems. Machine learning systems trained on these features are computationally
efficient and typically require less training data. Audio Toolbox provides audioFeatureExtractor so that you can efficiently extract audio
features.
Advances in deep learning architectures, increased access to computing power, and
large and well-labeled data sets have decreased the reliance on hand-designed
features. State-of-the-art results are often achieved using mel spectrograms
(melSpectrogram), linear spectrograms, or raw audio waveforms.
Audio Toolbox provides audioFeatureExtractor so that you can extract multiple auditory
spectrograms, such as the mel spectrogram, gammatone spectrogram, or Bark
spectrogram, and pair them with low-level descriptors. Using
audioFeatureExtractor enables you to systematically determine
audio features for your deep learning model. Alternatively, you can use the
melSpectrogram function to quickly extract just the mel spectrogram.
Audio Toolbox also provides the modified discrete cosine transform (mdct),
which returns a compact spectral representation without any loss of
information.
Example Applications and Workflows
Choosing features, deciding what kind of augmentations and preprocessing to apply, and designing a deep learning model all depend on the nature of the training data and the problem you want to solve. Audio Toolbox provides examples that illustrate deep learning workflows adapted to different data sets and audio applications. The table lists audio deep learning examples by network type (convolutional neural network, fully connected neural network, or recurrent neural network) and problem category (classification, regression, or sequence-to-sequence).
CNN or FC | LSTM, BiLSTM, or GRU | |||||||||||||||||||||||||
Classification |
|
| ||||||||||||||||||||||||
Regression or Sequence-to-Sequence |
|
|
References
[1] Purwins, H., B. Li, T. Virtanen, J. Schülter, S. Y. Chang, and T. Sainath. "Deep Learning for Audio Signal Processing." Journal of Selected Topics of Signal Processing. Vol. 13, Issue 2, 2019, pp. 206–219.
See Also
audioFeatureExtractor | audioDataAugmenter | audioDatastore | Signal
Labeler
Topics
- Classify Sound Using Deep Learning
- Get Started with Deep Network Designer (Deep Learning Toolbox)