dlquantizer
Quantize a deep neural network to 8-bit scaled integer data types
Description
Add-On Required: This feature requires the Deep Learning Toolbox Model Compression Library add-on.
Use the dlquantizer object to reduce the memory requirement of a
deep neural network by quantizing weights, biases, and activations to 8-bit scaled integer
data types. You can create and verify the behavior of a quantized network for GPU, FPGA, CPU
deployment, or explore the quantized network in MATLAB® and Simulink®.
For CPU and GPU deployment using third-party deep learning libraries, provide the
calibration result file produced by the calibrate function
to the codegen (MATLAB Coder) command to generate code for the
quantized network. Note that code generation in MATLAB does not support quantized deep neural networks produced by the quantize
function.
For FPGA deployment, input the calibrated dlquantizer object to the
dlhdl.Workflow (Deep Learning HDL Toolbox) class
to deploy the quantized network.
For target-agnostic C/C++ code generation, quantize the network using the MATLAB execution environment, export the network to Simulink, and generate code for the quantized network using Simulink Coder™ or Embedded Coder®.
To learn about the products required to quantize a deep neural network, see Quantization Workflow System Requirements.
Creation
Syntax
Description
Input Arguments
Output Arguments
Properties
Object Functions
prepareNetwork | Prepare deep neural network for quantization |
calibrate | Simulate and collect ranges of a deep neural network |
quantize | Quantize deep neural network |
validate | Quantize and validate a deep neural network |
Examples
This example shows how to quantize learnable parameters in the convolution layers of a neural network for GPU and explore the behavior of the quantized network. In this example, you quantize the squeezenet neural network after retraining the network to classify new images. In this example, the memory required for the network is reduced approximately 75% through quantization while the accuracy of the network is not affected.
Load the pretrained network. net is the output network of the Train Deep Learning Network to Classify New Images example.
load squeezedlnetmerch
netnet =
dlnetwork with properties:
Layers: [67×1 nnet.cnn.layer.Layer]
Connections: [74×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
Define calibration and validation data to use for quantization.
The calibration data is used to collect the dynamic ranges of the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network. For the best quantization results, the calibration data must be representative of inputs to the network.
The validation data is used to test the network after quantization to understand the effects of the limited range and precision of the quantized convolution layers in the network.
In this example, use the images in the MerchData data set. Define an augmentedImageDatastore object to resize the data for the network. Then, split the data into calibration and validation data sets.
unzip('MerchData.zip'); imds = imageDatastore('MerchData', ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); classes = categories(imds.Labels); [calData, valData] = splitEachLabel(imds, 0.7, 'randomized'); aug_calData = augmentedImageDatastore([227 227], calData); aug_valData = augmentedImageDatastore([227 227], valData);
Create a dlquantizer object and specify the network to quantize.
dlquantObj = dlquantizer(net);
Specify the GPU target.
quantOpts = dlquantizationOptions(Target='gpu');
quantOpts.MetricFcn = {@(x)hAccuracy(x,net,aug_valData,classes)}quantOpts =
dlquantizationOptions with properties:
Validation Metric Info
MetricFcn: {[@(x)hAccuracy(x,net,aug_valData,classes)]}
Validation Environment Info
Target: 'gpu'
Bitstream: ''
Use the calibrate function to exercise the network with sample inputs and collect range information. The calibrate function exercises the network and collects the dynamic ranges of the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network. The function returns a table. Each row of the table contains range information for a learnable parameter of the optimized network.
calResults = calibrate(dlquantObj, aug_calData)
calResults=120×5 table
'conv1_Weights' 'conv1' "Weights" -0.9198 0.8849
'conv1_Bias' 'conv1' "Bias" -0.0793 0.2634
'fire2-squeeze1x1_Weights' 'fire2-squeeze1x1' "Weights" -1.3800 1.2477
'fire2-squeeze1x1_Bias' 'fire2-squeeze1x1' "Bias" -0.1164 0.2427
'fire2-expand1x1_Weights' 'fire2-expand1x1' "Weights" -0.7406 0.9098
'fire2-expand1x1_Bias' 'fire2-expand1x1' "Bias" -0.0601 0.1460
'fire2-expand3x3_Weights' 'fire2-expand3x3' "Weights" -0.7440 0.6691
'fire2-expand3x3_Bias' 'fire2-expand3x3' "Bias" -0.0518 0.0742
'fire3-squeeze1x1_Weights' 'fire3-squeeze1x1' "Weights" -0.7712 0.6892
'fire3-squeeze1x1_Bias' 'fire3-squeeze1x1' "Bias" -0.1014 0.3267
'fire3-expand1x1_Weights' 'fire3-expand1x1' "Weights" -0.7204 0.9743
'fire3-expand1x1_Bias' 'fire3-expand1x1' "Bias" -0.0670 0.3043
'fire3-expand3x3_Weights' 'fire3-expand3x3' "Weights" -0.6144 0.7741
'fire3-expand3x3_Bias' 'fire3-expand3x3' "Bias" -0.0536 0.1033
⋮
Use the validate function to quantize the learnable parameters in the convolution layers of the network and exercise the network. The function uses the metric function defined in the dlquantizationOptions object to compare the results of the network before and after quantization.
valResults = validate(dlquantObj, aug_valData, quantOpts)
valResults = struct with fields:
NumSamples: 20
MetricResults: [1×1 struct]
Statistics: [2×2 table]
Examine the validation output to see the performance of the quantized network.
valResults.MetricResults.Result
ans=2×2 table
'Floating-Point' 1
'Quantized' 1
valResults.Statistics
ans=2×2 table
'Floating-Point' 2900268
'Quantized' 733932
In this example, the memory required for the network was reduced approximately 75% through quantization. The accuracy of the network is not affected.
The weights, biases, and activations of the convolution layers of the network specified in the dlquantizer object now use scaled 8-bit integer data types.
This example shows how to quantize and validate a neural network for a CPU target. This workflow is similar to other execution environments, but before validating you must establish a raspi connection and specify it as target using dlquantizationOptions.
First, load your network. This example uses the pretrained network squeezenet.
load squeezedlnetmerch
netnet =
dlnetwork with properties:
Layers: [67×1 nnet.cnn.layer.Layer]
Connections: [74×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
Then define your calibration and validation data, calDS and valDS respectively.
unzip('MerchData.zip'); imds = imageDatastore('MerchData', ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); classes = categories(imds.Labels); [calData, valData] = splitEachLabel(imds, 0.7, 'randomized'); aug_calData = augmentedImageDatastore([227 227],calData); aug_valData = augmentedImageDatastore([227 227],valData);
Create the dlquantizer object and specify a CPU execution environment.
dq = dlquantizer(net,'ExecutionEnvironment','CPU')
dq =
dlquantizer with properties:
NetworkObject: [1×1 dlnetwork]
ExecutionEnvironment: 'CPU'
Calibrate the network.
calResults = calibrate(dq,aug_calData,'UseGPU','off')
calResults=120×5 table
"conv1_Weights" 'conv1' "Weights" -0.9198 0.8849
"conv1_Bias" 'conv1' "Bias" -0.0793 0.2634
"fire2-squeeze1x1_Weights" 'fire2-squeeze1x1' "Weights" -1.3800 1.2477
"fire2-squeeze1x1_Bias" 'fire2-squeeze1x1' "Bias" -0.1164 0.2427
"fire2-expand1x1_Weights" 'fire2-expand1x1' "Weights" -0.7406 0.9098
"fire2-expand1x1_Bias" 'fire2-expand1x1' "Bias" -0.0601 0.1460
"fire2-expand3x3_Weights" 'fire2-expand3x3' "Weights" -0.7440 0.6691
"fire2-expand3x3_Bias" 'fire2-expand3x3' "Bias" -0.0518 0.0742
"fire3-squeeze1x1_Weights" 'fire3-squeeze1x1' "Weights" -0.7712 0.6892
"fire3-squeeze1x1_Bias" 'fire3-squeeze1x1' "Bias" -0.1014 0.3267
"fire3-expand1x1_Weights" 'fire3-expand1x1' "Weights" -0.7204 0.9743
"fire3-expand1x1_Bias" 'fire3-expand1x1' "Bias" -0.0670 0.3043
"fire3-expand3x3_Weights" 'fire3-expand3x3' "Weights" -0.6144 0.7741
"fire3-expand3x3_Bias" 'fire3-expand3x3' "Bias" -0.0536 0.1033
⋮
Use the Raspberry Pi® Blockset function, raspi, to create a connection to the Raspberry Pi. In the following code, replace:
raspinamewith the name or address of your Raspberry Piusernamewith your user namepasswordwith your password
% r = raspi('raspiname','username','password')For example,
r = raspi('gpucoder-raspberrypi-8','pi','matlab')
r =
raspi with properties:
DeviceAddress: 'gpucoder-raspberrypi-8'
Port: 18734
BoardName: 'Raspberry Pi 3 Model B+'
AvailableLEDs: {'led0'}
AvailableDigitalPins: [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27]
AvailableSPIChannels: {}
AvailableI2CBuses: {}
AvailableWebcams: {}
I2CBusSpeed:
AvailableCANInterfaces: {}
Supported peripherals
Specify raspi object as the target for the quantized network.
opts = dlquantizationOptions('Target',r);
opts.MetricFcn = {@(x)hAccuracy(x,net,aug_valData,classes)}opts =
dlquantizationOptions with properties:
Validation Metric Info
MetricFcn: {[@(x)hAccuracy(x,net,aug_valData,classes)]}
Validation Environment Info
Target: [1×1 raspi]
Bitstream: ''
Validate the quantized network with the validate function.
valResults = validate(dq,aug_valData,opts)
### Starting application: 'codegen/lib/validate_predict_int8/pil/validate_predict_int8.elf'
To terminate execution: clear validate_predict_int8_pil
### Launching application validate_predict_int8.elf...
### Host application produced the following standard output (stdout) and standard error (stderr) messages:
valResults = struct with fields:
NumSamples: 20
MetricResults: [1×1 struct]
Statistics: []
Examine the validation output to see the performance of the quantized network.
valResults.MetricResults.Result
ans=2×2 table
'Floating-Point' 1
'Quantized' 1
Reduce the memory footprint of a deep neural network by quantizing the weights, biases, and activations of convolution layers to 8-bit scaled integer data types. This example shows how to use Deep Learning Toolbox Model Compression Library and Deep Learning HDL Toolbox to deploy the int8 network to a target FPGA board.
Load Pretrained Network
Load the pretrained LogoNet network and analyze the network architecture.
snet = getLogoNetwork; deepNetworkDesigner(snet);
Set random number generator for reproducibility.
rng(0);
Load Data
This example uses the logos_dataset data set. The data set consists of 320 images. Each image is 227-by-227 in size and has three color channels (RGB). Create an augmentedImageDatastore object for calibration and validation.
curDir = pwd; unzip("logos_dataset.zip"); imageData = imageDatastore(fullfile(curDir,'logos_dataset'),... 'IncludeSubfolders',true,'FileExtensions','.JPG','LabelSource','foldernames'); [calibrationData, validationData] = splitEachLabel(imageData, 0.5,'randomized');
Generate Calibration Result File for the Network
Create a dlquantizer (Deep Learning HDL Toolbox) object and specify the network to quantize. Specify the execution environment as FPGA.
dlQuantObj = dlquantizer(snet,'ExecutionEnvironment',"FPGA");
Use the calibrate (Deep Learning HDL Toolbox) function to exercise the network with sample inputs and collect the range information. The calibrate function collects the dynamic ranges of the weights and biases. The calibrate function returns a table. Each row of the table contains range information for a learnable parameter of the quantized network.
calibrate(dlQuantObj,calibrationData)
ans=35×5 table
'conv_1_Weights' 'conv_1' "Weights" -0.0490 0.0394
'conv_1_Bias' 'conv_1' "Bias" 1 1.0028
'conv_2_Weights' 'conv_2' "Weights" -0.0555 0.0619
'conv_2_Bias' 'conv_2' "Bias" -0.0006 0.0023
'conv_3_Weights' 'conv_3' "Weights" -0.0459 0.0469
'conv_3_Bias' 'conv_3' "Bias" -0.0014 0.0015
'conv_4_Weights' 'conv_4' "Weights" -0.0460 0.0510
'conv_4_Bias' 'conv_4' "Bias" -0.0016 0.0038
'fc_1_Weights' 'fc_1' "Weights" -0.0514 0.0543
'fc_1_Bias' 'fc_1' "Bias" -0.0005 0.0008
'fc_2_Weights' 'fc_2' "Weights" -0.0502 0.0516
'fc_2_Bias' 'fc_2' "Bias" -0.0018 0.0019
'fc_3_Weights' 'fc_3' "Weights" -0.0507 0.0468
'fc_3_Bias' 'fc_3' "Bias" -0.0295 0.0249
⋮
Create Target Object
Create a target object with a custom name for your target device and an interface to connect your target device to the host computer. Interface options are JTAG and Ethernet. Interface options are JTAG and Ethernet. To use JTAG, install Xilinx Vivado® Design Suite 2022.1. To set the Xilinx Vivado toolpath, enter:
hdlsetuptoolpath('ToolName', 'Xilinx Vivado', 'ToolPath', 'C:\Xilinx\Vivado\2022.1\bin\vivado.bat');
To create the target object, enter:
hTarget = dlhdl.Target('Xilinx','Interface','Ethernet','IPAddress','10.10.10.15');
Alternatively, you can also use the JTAG interface.
% hTarget = dlhdl.Target('Xilinx', 'Interface', 'JTAG');Create dlQuantizationOptions Object
Create a dlquantizationOptions object. Specify the target bitstream and target board interface. The default metric function is a Top-1 accuracy metric function.
options_FPGA = dlquantizationOptions('Bitstream','zcu102_int8','Target',hTarget); options_emulation = dlquantizationOptions('Target','host');
To use a custom metric function, specify the metric function in the dlquantizationOptions object.
options_FPGA = dlquantizationOptions('MetricFcn',{@(x)hComputeAccuracy(x,snet,validationData)},'Bitstream','zcu102_int8','Target',hTarget); options_emulation = dlquantizationOptions('MetricFcn',{@(x)hComputeAccuracy(x,snet,validationData)})
Validate Quantized Network
Use the validate function to quantize the learnable parameters in the convolution layers of the network. The validate function simulates the quantized network in MATLAB. The validate function uses the metric function defined in the dlquantizationOptions object to compare the results of the single-data-type network object to the results of the quantized network object.
prediction_emulation = dlQuantObj.validate(validationData,options_emulation)
prediction_emulation = struct with fields:
NumSamples: 160
MetricResults: [1×1 struct]
Statistics: []
For validation on an FPGA, the validate function:
Programs the FPGA board by using the output of the
compilemethod and the programming fileDownloads the network weights and biases
Compares the performance of the network before and after quantization
prediction_FPGA = dlQuantObj.validate(validationData,options_FPGA)
### Compiling network for Deep Learning FPGA prototyping ...
### Targeting FPGA bitstream zcu102_int8.
### The network includes the following layers:
1 'imageinput' Image Input 227×227×3 images with 'zerocenter' normalization and 'randfliplr' augmentations (SW Layer)
2 'conv_1' 2-D Convolution 96 5×5×3 convolutions with stride [1 1] and padding [0 0 0 0] (HW Layer)
3 'relu_1' ReLU ReLU (HW Layer)
4 'maxpool_1' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
5 'conv_2' 2-D Convolution 128 3×3×96 convolutions with stride [1 1] and padding [0 0 0 0] (HW Layer)
6 'relu_2' ReLU ReLU (HW Layer)
7 'maxpool_2' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
8 'conv_3' 2-D Convolution 384 3×3×128 convolutions with stride [1 1] and padding [0 0 0 0] (HW Layer)
9 'relu_3' ReLU ReLU (HW Layer)
10 'maxpool_3' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
11 'conv_4' 2-D Convolution 128 3×3×384 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
12 'relu_4' ReLU ReLU (HW Layer)
13 'maxpool_4' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
14 'fc_1' Fully Connected 2048 fully connected layer (HW Layer)
15 'relu_5' ReLU ReLU (HW Layer)
16 'fc_2' Fully Connected 2048 fully connected layer (HW Layer)
17 'relu_6' ReLU ReLU (HW Layer)
18 'fc_3' Fully Connected 32 fully connected layer (HW Layer)
19 'softmax' Softmax softmax (SW Layer)
20 'classoutput' Classification Output crossentropyex with 'adidas' and 31 other classes (SW Layer)
### Notice: The layer 'imageinput' with type 'nnet.cnn.layer.ImageInputLayer' is implemented in software.
### Notice: The layer 'softmax' with type 'nnet.cnn.layer.SoftmaxLayer' is implemented in software.
### Notice: The layer 'classoutput' with type 'nnet.cnn.layer.ClassificationOutputLayer' is implemented in software.
### Compiling layer group: conv_1>>relu_4 ...
### Compiling layer group: conv_1>>relu_4 ... complete.
### Compiling layer group: maxpool_4 ...
### Compiling layer group: maxpool_4 ... complete.
### Compiling layer group: fc_1>>fc_3 ...
### Compiling layer group: fc_1>>fc_3 ... complete.
### Allocating external memory buffers:
offset_name offset_address allocated_space
_______________________ ______________ ________________
"InputDataOffset" "0x00000000" "11.9 MB"
"OutputResultOffset" "0x00be0000" "128.0 kB"
"SchedulerDataOffset" "0x00c00000" "128.0 kB"
"SystemBufferOffset" "0x00c20000" "9.9 MB"
"InstructionDataOffset" "0x01600000" "4.6 MB"
"ConvWeightDataOffset" "0x01aa0000" "8.2 MB"
"FCWeightDataOffset" "0x022e0000" "10.4 MB"
"EndOffset" "0x02d40000" "Total: 45.2 MB"
### Network compilation complete.
### FPGA bitstream programming has been skipped as the same bitstream is already loaded on the target FPGA.
### Deep learning network programming has been skipped as the same network is already loaded on the target FPGA.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Finished writing input activations.
### Running single input activation.
### Notice: The layer 'imageinput' of type 'ImageInputLayer' is split into an image input layer 'imageinput' and an addition layer 'imageinput_norm' for normalization on hardware.
### The network includes the following layers:
1 'imageinput' Image Input 227×227×3 images with 'zerocenter' normalization and 'randfliplr' augmentations (SW Layer)
2 'conv_1' 2-D Convolution 96 5×5×3 convolutions with stride [1 1] and padding [0 0 0 0] (HW Layer)
3 'relu_1' ReLU ReLU (HW Layer)
4 'maxpool_1' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
5 'conv_2' 2-D Convolution 128 3×3×96 convolutions with stride [1 1] and padding [0 0 0 0] (HW Layer)
6 'relu_2' ReLU ReLU (HW Layer)
7 'maxpool_2' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
8 'conv_3' 2-D Convolution 384 3×3×128 convolutions with stride [1 1] and padding [0 0 0 0] (HW Layer)
9 'relu_3' ReLU ReLU (HW Layer)
10 'maxpool_3' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
11 'conv_4' 2-D Convolution 128 3×3×384 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
12 'relu_4' ReLU ReLU (HW Layer)
13 'maxpool_4' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0] (HW Layer)
14 'fc_1' Fully Connected 2048 fully connected layer (HW Layer)
15 'relu_5' ReLU ReLU (HW Layer)
16 'fc_2' Fully Connected 2048 fully connected layer (HW Layer)
17 'relu_6' ReLU ReLU (HW Layer)
18 'fc_3' Fully Connected 32 fully connected layer (HW Layer)
19 'softmax' Softmax softmax (SW Layer)
20 'classoutput' Classification Output crossentropyex with 'adidas' and 31 other classes (SW Layer)
### Notice: The layer 'softmax' with type 'nnet.cnn.layer.SoftmaxLayer' is implemented in software.
### Notice: The layer 'classoutput' with type 'nnet.cnn.layer.ClassificationOutputLayer' is implemented in software.
Deep Learning Processor Estimator Performance Results
LastFrameLatency(cycles) LastFrameLatency(seconds) FramesNum Total Latency Frames/s
------------- ------------- --------- --------- ---------
Network 39136574 0.17789 1 39136574 5.6
imageinput_norm 216472 0.00098
conv_1 6832680 0.03106
maxpool_1 3705912 0.01685
conv_2 10454501 0.04752
maxpool_2 1173810 0.00534
conv_3 9364533 0.04257
maxpool_3 1229970 0.00559
conv_4 1759348 0.00800
maxpool_4 24450 0.00011
fc_1 2651288 0.01205
fc_2 1696632 0.00771
fc_3 26978 0.00012
* The clock frequency of the DL processor is: 220MHz
### Finished writing input activations.
### Running single input activation.
prediction_FPGA = struct with fields:
NumSamples: 160
MetricResults: [1×1 struct]
Statistics: [2×7 table]
View Performance of Quantized Neural Network
Display the accuracy of the quantized network.
prediction_emulation.MetricResults.Result
ans=2×2 table
'Floating-Point' 0.9875
'Quantized' 0.9875
prediction_FPGA.MetricResults.Result
ans=2×2 table
'Floating-Point' 0.9875
'Quantized' 0.9875
Display the performance of the quantized network in frames per second.
prediction_FPGA.Statistics
ans=2×7 table
'Floating-Point' 5.6213 16 4 93.1976 63.9254 15.5952
'Quantized' 19.4335 64 16 62.3099 50.1096 32.1032
Import a dlquantizer object from the base workspace into the
Deep Network Quantizer app to begin quantization of a deep neural network
using either the command line or the app, and resume your work later in the app.
Open the Deep Network Quantizer app.
deepNetworkQuantizer
In the app, click New and select Import
dlquantizer object.
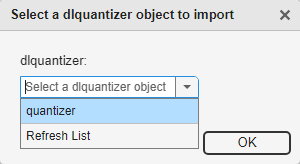
In the dialog, select a dlquantizer object to import from the
base workspace. For this example, use the dlquantizer object
quantizer from the above example Quantize a Neural Network
for GPU Target. You can create the quantizer object by selecting
Export Quantizer from the Export
drop-down list after quantizing the network.
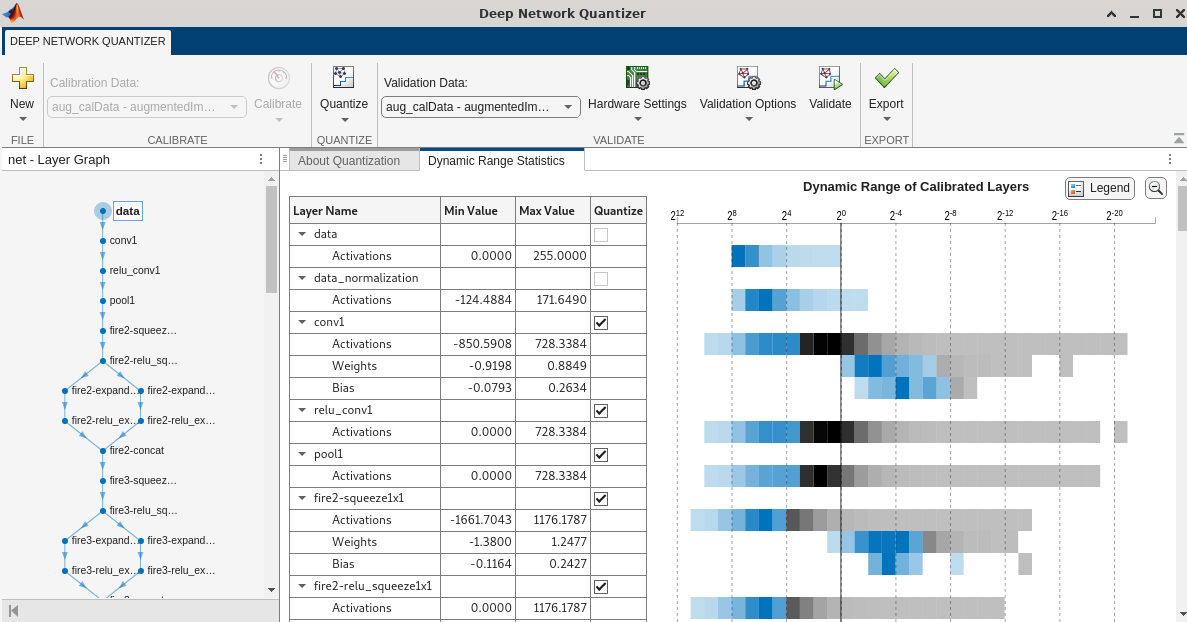
The app imports any data contained in the dlquantizer object that
was collected at the command line, including the quantized network, calibration
data, validation data, and calibration statistics.
The app displays a table containing the quantization data contained in the
imported dlquantizer object, quantizer. To the
right of the table, the app displays histograms of the dynamic ranges of the
parameters. The gray regions of the histograms indicate data that cannot be
represented by the quantized representation. For more information on how to
interpret these histograms, see Quantization of Deep Neural Networks.
This example shows how to create a target agnostic, simulatable quantized deep neural network in MATLAB.
Target agnostic quantization allows you to see the effect quantization has on your neural network without target hardware or target-specific quantization schemes. Creating a target agnostic quantized network is useful if you:
Do not have access to your target hardware.
Want to preview whether or not your network is suitable for quantization.
Want to find layers that are sensitive to quantization.
Quantized networks emulate quantized behavior for quantization-compatible layers. Network architecture like layers and connections are the same as the original network, but inference behavior uses limited precision types. Once you have quantized your network, you can use the quantizationDetails function to retrieve details on what was quantized.
Load the pretrained network. net is a SqueezeNet network that has been retrained using transfer learning to classify images in the MerchData data set.
load squeezedlnetmerch
netnet =
dlnetwork with properties:
Layers: [67×1 nnet.cnn.layer.Layer]
Connections: [74×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
You can use the quantizationDetails function to see that the network is not quantized.
qDetailsOriginal = quantizationDetails(net)
qDetailsOriginal = struct with fields:
IsQuantized: 0
TargetLibrary: ""
QuantizedLayerNames: [0×0 string]
QuantizedLearnables: [0×3 table]
Unzip and load the MerchData images as an image datastore and extract the classes from the datastore.
unzip('MerchData.zip') imds = imageDatastore('MerchData', ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); classes = categories(imds.Labels);
Define calibration and validation data to use for quantization. The output size of the images are changed for both calibration and validation data according to network requirements.
[calData,valData] = splitEachLabel(imds,0.7,'randomized');
augCalData = augmentedImageDatastore([227 227],calData);
augValData = augmentedImageDatastore([227 227],valData);Create dlquantizer object and specify the network to quantize. Set the execution environment to MATLAB. How the network is quantized depends on the execution environment. The MATLAB execution environment is agnostic to the target hardware and allows you to prototype quantized behavior. When you use the MATLAB execution environment, quantization is performed using the fi fixed-point data type which requires a Fixed-Point Designer™ license.
quantObj = dlquantizer(net,'ExecutionEnvironment','MATLAB');
Use the calibrate function to exercise the network with sample inputs and collect range information. The calibrate function exercises the network and collects the dynamic ranges of the weights and biases in the convolution and fully connected layers of the network and the dynamic ranges of the activations in all layers of the network. The function returns a table. Each row of the table contains range information for a learnable parameter of the optimized network.
calResults = calibrate(quantObj,augCalData);
Use the quantize method to quantize the network object and return a simulatable quantized network.
qNet = quantize(quantObj)
qNet =
Quantized dlnetwork with properties:
Layers: [67×1 nnet.cnn.layer.Layer]
Connections: [74×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
Use the quantizationDetails function to extract quantization details.
You can use the quantizationDetails function to see that the network is now quantized.
qDetailsQuantized = quantizationDetails(qNet)
qDetailsQuantized = struct with fields:
IsQuantized: 1
TargetLibrary: "none"
QuantizedLayerNames: [53×1 string]
QuantizedLearnables: [52×3 table]
Make predictions using the original, single-precision floating-point network, and the quantized INT8 network.
origScores = minibatchpredict(net,augValData); predOriginal = scores2label(origScores,classes); % Predictions for the non-quantized network qScores = minibatchpredict(qNet,augValData); predQuantized = scores2label(qScores,classes); % Predictions for the quantized network
Compute the relative accuracy of the quantized network as compared to the original network.
ccrQuantized = mean(squeeze(predQuantized) == valData.Labels)*100
ccrQuantized = 100
ccrOriginal = mean(squeeze(predOriginal) == valData.Labels)*100
ccrOriginal = 100
For this validation data set, the quantized network gives the same predictions as the floating-point network.
Version History
Introduced in R2020aSee Also
Apps
Functions
prepareNetwork|calibrate|quantize|validate|dlquantizationOptions|quantizationDetails|estimateNetworkMetrics
Topics
- Quantization of Deep Neural Networks
- Reduce Memory Footprint of Deep Neural Networks
- Train and Compress AI Model for Road Damage Detection
- Quantize Residual Network Trained for Image Classification and Generate CUDA Code
- Quantize Layers in Object Detectors and Generate CUDA Code
- Quantize Network for FPGA Deployment (Deep Learning HDL Toolbox)
- Generate INT8 Code for Deep Learning Network on Raspberry Pi (MATLAB Coder)
- Parameter Pruning and Quantization of Image Classification Network