Reidentify People Throughout a Video Sequence Using ReID Network
This example shows how to track people throughout a video sequence using re-identification with a residual network.
Re-identification (ReID) is a critical component in visual object tracking that aims to solve the problem of temporary object occlusion in videos. In real-world scenarios, an object being tracked can be temporarily occluded by other objects or leave the field of view of the camera, making it difficult to track consistently. These objects can also differ frame-to-frame in pose, orientation, and lighting conditions. In these complicated scenarios, the tracker often fails to reidentify the object when it reappears in a new video frame. The tracker then starts tracking the object as a new object. This misidentification leads to errors and inconsistencies in object tracking.
ReID aims to solve this problem by identifying the same object in the new frame by matching its features to the previously tracked object features, even if it appears in a different location or orientation, or has dissimilar lighting compared to the previous frame. This approach ensures that the tracker can maintain consistent tracking information for a given object.
ReID is typically used in tracking applications such as surveillance, automated driving systems, robot vision, and sports analytics, where accurate and consistent tracking of objects is essential.
This example first shows how to perform re-identification in a video sequence with a pretrained ReID network. The second part of the example shows how to train a ReID network as a traditional classification network with cross-entropy loss. After training is complete, the output layers of the network will have an appearance feature vector with a length of 2048.
Load Pretrained Re-Identification Network
Load the pretrained ReID network trained on the pedestrian data set. To train the network, see the Train ReID Network section of this example.
pretrainedNet = helperDownloadReIDNetwork;
Reidentify Pedestrian in Video Sequence
Download the pedestrian tracking test video file.
videoURL = "https://ssd.mathworks.com/supportfiles/vision/data/PedestrianTrackingVideo.avi"; if ~exist("PedestrianTrackingVideo.avi","file") disp("Downloading Pedestrian Tracking Video (35 MB)") websave("PedestrianTrackingVideo.avi",videoURL); end
Downloading Pedestrian Tracking Video (35 MB)
Load a pretrained object detector.
detector = yolov4ObjectDetector("csp-darknet53-coco");Read the pedestrian tracking video.
pedestrianVideo = VideoReader("PedestrianTrackingVideo.avi");To detect all objects in each frame, iterate through the video sequence. Compute the output of the pretrained ReID network by passing pretrainedNet and the cropped pedestrian objects as inputs to the extractReidentificationFeatures (Computer Vision Toolbox) method function of the reidentificationNetwork (Computer Vision Toolbox) object. The output is an appearance feature vector with a length of 2048.
To identify the same individual throughout the video sequence, compare the appearance feature vector of the first pedestrian and each distinct subsequently detected pedestrian using the pdist2 (Statistics and Machine Learning Toolbox) function with the cosine similarity distance. The values of cosine similarity range from -1 to 1, where 1 indicates that the pedestrian images are identical, 0 indicates that the images are not very alike, and -1 indicates that the images are vastly different. To match only images that are closely related to one another, set the similarity threshold similarityThreshold to 0.7.
pedestrianFeature = [];
pedestrianMontage = {};
while hasFrame(pedestrianVideo)
% Read the current frame.
vidFrame = readFrame(pedestrianVideo);
% Run the detector, crop all bounding boxes to the frame, and round the
% bounding box to integer values.
[bboxes, scores, labels] = detect(detector,vidFrame,Threshold=0.5);
bboxes = bboxcrop(bboxes,[1 1 size(vidFrame,2) size(vidFrame,1)]);
bboxes = round(bboxes);
% Count the number of each object detected in the frame and find the
% number of people detected.
numLabels = countcats(labels);
numPedestrians = numLabels(1);
% Crop each detected person and pass the cropped pedestrian through the
% pretrained ReID network to obtain appearance feature vectors.
appearanceData = zeros(2048,numPedestrians);
croppedPerson = cell(numPedestrians);
pedestrian = 1;
for i = 1:size(bboxes,1)
% Pass only detected pedestrian objects through the pretrained network.
if labels(i) == "person"
bbox = bboxes(i,:);
croppedImg = imcrop(vidFrame,bbox);
croppedPerson{pedestrian} = imresize(croppedImg,[128 64]);
appearanceData(:,pedestrian) = extractReidentificationFeatures(pretrainedNet,croppedImg);
pedestrian = pedestrian + 1;
end
end
% Obtain the first pedestrian feature vector and use the best
% matching feature vector in each frame to continuously track the pedestrian through
% the video sequence.
if isempty(pedestrianFeature)
pedestrianFeature = appearanceData(:,1);
pedestrianMontage{end+1} = croppedPerson{1};
else
% Use the cosine similarity metric to find the closest matching
% pedestrian in the current frame.
cosineSimilarity = 1-pdist2(pedestrianFeature',appearanceData',"cosine");
[cosSim,matchIdx] = max(cosineSimilarity);
% Update the pedestrian feature vector to the latest frame data.
% Here, filter out the best matching feature vector if it is not
% close enough to the last known feature vector. This approach helps handle
% the case where the person is no longer in the video frame.
similarityThreshold = 0.7;
if cosSim > similarityThreshold
pedestrianFeature = appearanceData(:,matchIdx);
pedestrianMontage{end+1} = croppedPerson{matchIdx};
end
end
endFor illustration purposes, highlight the mismatched pedestrian.
mismatchIdx = 25;
mismatchImg = pedestrianMontage{mismatchIdx};
pedestrianMontage{mismatchIdx} = insertShape(mismatchImg,"rectangle",[1 1 size(mismatchImg,[2 1])],LineWidth=5,ShapeColor="red");Display the pedestrian identified throughout the video sequence.
montage(pedestrianMontage)

The network reidentifies the individual approximately 93% of the time throughout the video, missing only 5 instances of the individual in 73 distinct video frames. The tracking logic, where you use a simple cosine similarity threshold to filter and match appearance feature vectors, can lead to imperfect performance. For example, in the cropped video frames pictured above, the network misidentifies the pedestrian (red outline). However, because the pedestrian in this frame is an outlier with similar features to the pedestrian of interest, the model is able to recover. This simple tracking logic will not perform well in more complicated scenarios and for multiple pedestrians in each frame.
To significantly improve the network tracking performance, implement the robust tracking logic in the Multi-Object Tracking with DeepSORT (Sensor Fusion and Tracking Toolbox) example.
Load Training Data
To train the ReID network, first label the video sequence data with a labeling tool such as Image Labeler (Computer Vision Toolbox) or Ground Truth Labeler (Automated Driving Toolbox). Each detected object identity must be tracked through every frame for each video, ensuring the identity label is consistent across video sequences. To ensure that the object is consistently labeled in each frame, assign different labels for each identity or use a string attribute. For videos that have minimal variation per object, use Create Automation Algorithm Function for Labeling (Computer Vision Toolbox) to help with manual labeling tasks.
Once the data has been fully labeled and exported from a labeler, use gatherLabelData (Computer Vision Toolbox) to obtain all ROI data and the writeFrames groundTruth (Computer Vision Toolbox) method to export all video frames. Then, create imageDatastore and boxLabelDatastore (Computer Vision Toolbox) objects from the extracted data and combine them using combine. To train the classifier that you convert into a ReID network, process the data further so that only the object of interest is in the bounding box. Resize these cropped images immediately or during the preprocessing stage of training the classifier.
In this example, the pedestrianDataset.zip file contains a folder that has 30 subfolders with cropped training images. Each object identity is organized into its own subfolder, for a total of 30 identities. See the Load Test Data section of this example for the entire pre-processing workflow to use with your own labeled data.
Unzip the pedestrian training data using the helperUnzipData helper function.
unzipDirectory = pwd; helperUnzipData(unzipDirectory)
Load the cropped and organized training data into an ImageDatastore object. Set the IncludeSubfolders argument to true to use the all of the data in trainingDataFolder. Set the LabelSource argument to "foldernames" to use the corresponding folders as the training data labels.
datasetFolder = "pedestrianDataset"; dataFolder = fullfile(unzipDirectory,datasetFolder); imds = imageDatastore(dataFolder,IncludeSubfolders=true,LabelSource="foldernames");
Prepare Data for Training
To ensure that the training and validation sets include a mix of individuals, shuffle the datastore prior to splitting it into training and validation sets.
rng(0) ds = shuffle(imds);
Split the data to into 90% training and 10% validation images. If your data set has more images, split your data into 80% training and 20% validation images. To ensure that the validation data contains unique images that do not overlap with training images, perform this step prior to generating any synthetic data.
numTraining = round(size(imds.Files,1)*0.9); dsOcclude = subset(ds,1:numTraining); dsVal = subset(ds,numTraining+1:size(imds.Files,1));
Generate Training Data with Synthetic Object Occlusions
One of the main challenges with re-identification is identifying an object when it is partially occluded from view. In the pedestrian case, other pedestrians can mostly block the individual of interest from view. Because training data does not often contain such images, generating synthetic training data that includes occlusion improves the network robustness to partial occlusion.
Generate synthetic training data using the helperGenerateOcclusionData helper function. Store the occlusion training data, including the original images, in occlusionDatasetDirectory.
occlusionDatasetDirectory = fullfile("pedestrianOcclusionDataset"); if ~exist("generateOcclusionData","var") generateOcclusionData = true; end if generateOcclusionData && ~exist(occlusionDatasetDirectory,"dir") writeall(dsOcclude,occlusionDatasetDirectory,WriteFcn=@(img,writeInfo,outputFormat) ... helperGenerateOcclusionData(img,writeInfo,outputFormat,datasetFolder)); generateOcclusionData = false; end
The helperGenerateOcclusionData helper function inserts occlusions into each image by removing three randomly generated rectangular regions of interest using the imerase function. The regions of interest are then filled with random noise to ensure no pattern is learned in the ReID network, and instead, the contents outside of this occlusions are focused on.
Load Generated Training Data into Datastore
The synthetic training data has been saved in the occlusionDatasetDirectory folder. Load the occlusion data to use as training data for the re-identification network.
dsTrain = imageDatastore(fullfile(occlusionDatasetDirectory,datasetFolder),IncludeSubfolders=true,LabelSource="foldernames");Preview the training data, which includes the inserted occlusions.
previewImages = cell(1,4); for i = 1:4 previewImages{i} = readimage(dsTrain,randi(numel(dsTrain.Files))); end montage(previewImages,Size=[1 4])

Reset the training imageDatastore to its initial state.
reset(dsTrain)
Define ReID Network Architecture
Use the reidentificationNetwork (Computer Vision Toolbox) object to create a ReID network that can be trained using the trainReidentificationNetwork (Computer Vision Toolbox) function. Specify the backbone network and the class names of the ReID network using the reidentificationNetwork (Computer Vision Toolbox) object.
Create a pretrained dlnetwork object that uses the ResNet-50 architecture using the imagePretrainedNetwork function.
resbackbone = imagePretrainedNetwork("resnet50");Obtain the class names from the complete training data set, imds.
classes = unique(imds.Labels);
Specify the image input size and the feature vector length. To learn more identifying details per individual, increase the featureLength at the expense of slower training and inference time.
inputSize = [128 64 3]; featureLength = 2048;
Create a reidentificationNetwork object.
net = reidentificationNetwork(resbackbone,classes,InputSize=inputSize,FeatureLength=featureLength);
Specify Training Options
Specify the training options. Train the network using the SGDM solver for a maximum of 120 epochs using a mini-batch size of 64.
numEpochs = 120; miniBatchSize = 64; options = trainingOptions("sgdm", ... MaxEpochs=numEpochs, ... ValidationData=dsVal, ... InitialLearnRate=0.01, ... LearnRateDropFactor=0.1, ... LearnRateDropPeriod=round(numEpochs/2), ... LearnRateSchedule="piecewise", ... MiniBatchSize=miniBatchSize, ... OutputNetwork="best-validation", ... Shuffle="every-epoch", ... VerboseFrequency=30, ... Verbose=true);
Train ReID Network
To train the ReID network, set the doTraining variable to true. Train the network using the trainReidentificationNetwork function. Set the LossFunction name-value argument to "cosine-softmax" as defined in DeepSORT ReID network [1]. Training takes about 1 hour on a 24 GB GPU. To prevent out-of-memory errors, reduce the mini-batch size if your system has less memory.
doTraining = false; if doTraining net = trainReidentificationNetwork(dsTrain,net,options, ... LossFunction="cosine-softmax",FreezeBackbone=false); else net = pretrainedNet; end
Evaluate ReID Network
Load Test Data
Load the labeled pedestrian ground truth test data into the workspace.
load("pedestrianLabelTestData.mat","gTruth");
Process the test data and store network-ready input images. The helperCropImagesWithGroundtruth helper function uses the ground truth data to crop out all the labeled test data within the video frames. The function also resizes the cropped images to a size of 128-by-64 pixels and organizes the labels into individual folders under the root folder, testDataFolder.
testDataFolder = fullfile("pedestrianTestData"); if ~isfolder(testDataFolder) helperCropImagesWithGroundtruth(gTruth,testDataFolder) end
Write images extracted for training to folder:
videoFrames
Writing 169 images extracted from PedestrianTrackingVideo.avi...Completed.
Cleaning up videoFrames directory.
Load the cropped and organized test data into an ImageDatastore object. Set the IncludeSubfolders name-value argument to true to use the all of the data in trainingDataFolder, and set LabelSource to "foldernames" to use the corresponding folder names as the training data labels.
testImds = imageDatastore(testDataFolder,IncludeSubfolders=true,LabelSource="foldernames");To extract the appearance feature vectors of all the images in the test image datastore, testImds, use the extractReidentificationFeatures (Computer Vision Toolbox) object function of the reidentificationNetwork object.
[appearanceFeatures,appearanceLabels] = extractReidentificationFeatures(net,testImds,MiniBatchSize=miniBatchSize);
Running Reidentification network -------------------------- * Processed 589 images. Finished processing images.
Visualize Appearance Feature Vectors
Analyze how well the ReID network is able to separate appearance features using the tsne (Statistics and Machine Learning Toolbox) function, which helps visualize high-dimensional data using the t-Distributed Stochastic Neighbor Embedding (TSNE) statistical method.
numTestClasses = numel(unique(testImds.Labels));
classColors = turbo(numTestClasses);
Y2 = tsne(appearanceFeatures',Distance="cosine",NumDimensions=2);Plot the feature embeddings using the gscatter (Statistics and Machine Learning Toolbox) function, using a unique color to identify the pedestrian class of each embedding.
gscatter(Y2(:,1),Y2(:,2),categorical(appearanceLabels),classColors,[],8)

The network is trained to group appearance feature vectors from the same pedestrian and to separate each pedestrian class as far away from another as possible. In the scatter plot, it is clear that detection of person 5 is not well localized to a single class and often spills into other pedestrian clusters (persons 6 and 7). In several instances, the feature vectors of person 7 are grouped with different pedestrian clusters and the person 7 cluster contains outliers from other pedestrian instances.
Calculate Cumulative Matching Characteristics and Mean Average Precision
Evaluate the performance of the ReID network by using the evaluateReidentificationNetwork (Computer Vision Toolbox) function. The function returns a reidentificationMetrics (Computer Vision Toolbox) object that contains the cumulative matching characteristics (CMC) metric and the mean average precision (mAP) of the network [2]. To identify the frames in which the network has difficulty re-identifying the correct pedestrian, you can view the queries and galleries used to calculate the CMC using the queries and gallerySets output arguments.
[metrics,queries,gallerySets] = evaluateReidentificationNetwork(appearanceFeatures,appearanceLabels);
Plot the Cumulative Matching Characteristics and Mean Average Precision
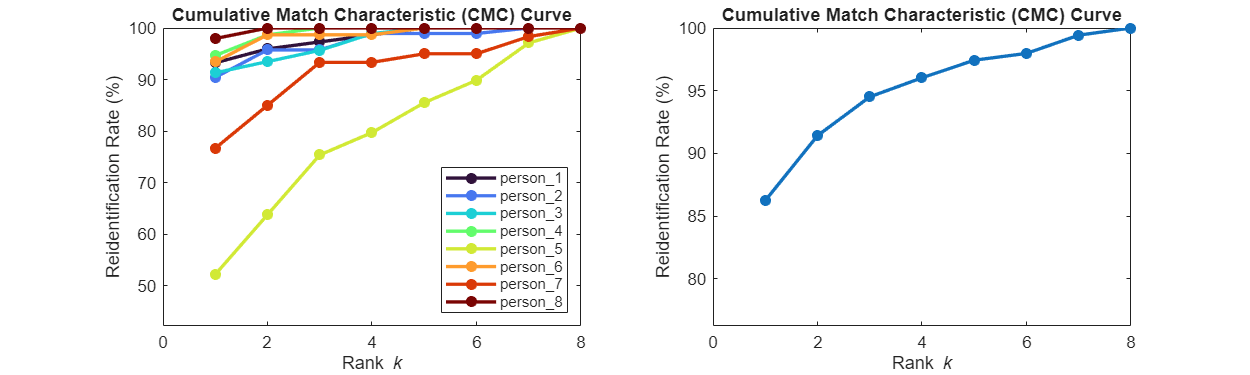
Use the plot (Computer Vision Toolbox) object function of the reidentificationMetrics object to directly plot the CMC per pedestrian and the average CMC. The CMC curve shows the re-identification rate versus the rank, the position at which the correct identity match appears in a sorted list of results. For example, rank k = 1 indicates that the correct identity match is the first result for a given probe image.
The CMC per pedestrian class (below, left) demonstrates that both person 5 and person 7 are not recognized as well as the other pedestrians, which is consistent with the TSNE visualization. The CMC curve averaged over all classes (below, right) demonstrates that the ReID network performs well on average, identifying the individual about 86% of the time.
figure("Position",[10, 10, 1000, 300]); ax1 = subplot(1,2,1); plot(metrics,"cmc-per-object",Parent=ax1,LineColor=classColors) ax2 = subplot(1,2,2); plot(metrics,"cmc",Parent=ax2)
Plot the precision-recall using the plot object function. The precision-recall curve displays that the ReID model achieves a mAP of approximately 86% as well.
plot(metrics,"precision-recall")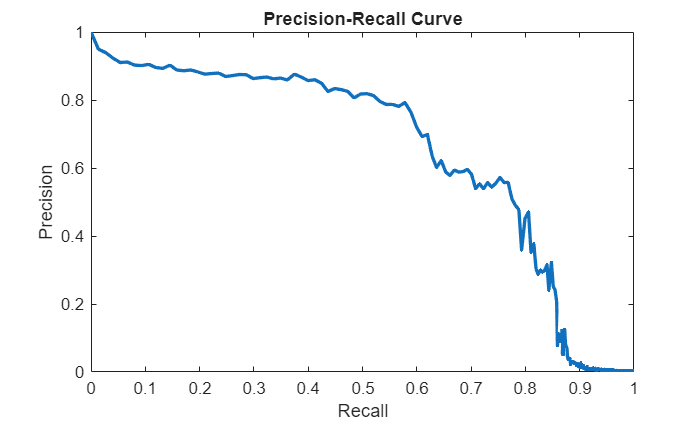
Visualize Problematic Pedestrians
According to the CMC per pedestrian curve and TSNE plot, the ReID network struggles to identify person 5 and person 7. To understand the variation in network performance, visualize the test data samples for person 1, 5, and 7 using the gallery sets returned by the evaluateReidentificationNetwork function.
montage(testImds.Files(gallerySets([1 5 7],1:5)'),Size=[3,5],BorderSize=[3 0])
title("Sample Gallery Sets - Person 1, 5, and 7 (Top to Bottom)")
The severely distorted images of person 5 account for the low performance, when the network cannot generate strong correlations if feature details are minimal. Person 7 is similarly distorted in some frames and contains a similar clothing color to a few other pedestrians in the test data. Analyzing the test video, it is clear that person 7 is also occluded in quite a few frames, which can lead to outlier appearance feature vectors to more closely resemble the pedestrian occluding person 7. The TSNE visualization in the Visualize Appearance Feature Vectors section and the video frames in the Reidentify Pedestrian in Video Sequence section of this example similarly show that the cluster for person 7 has several various pedestrian outlier points. The network performs well in general on the test data, but it does not learn to properly distinguish person 7 and the numerous occlusions that occur in front of them.
To demonstrate examples of features that hinder performance, display examples of low quality frames containing person 5 and occluded frames containing person 7.
lowQualityImgs = cell(5,2);
lowQualityImgs(:,1) = testImds.Files(336:340);
lowQualityImgs(:,2) = testImds.Files(533:537);
montage(lowQualityImgs,ThumbnailSize=[256 128])
title("Low Quality Examples of Person 5 (Top) and Occluded Examples of Person 7 (Bottom)")
To improve performance issues originating from occlusions with person 7, train the ReID network using a backbone that is attention aware, such as the vision transformer (ViT) neural network, visionTransformer (Computer Vision Toolbox). With this backbone, the network can learn small focused sections of each pedestrian and can identify a person correctly even when most of the pedestrian is occluded.
Summary
Object re-identification for visual tracking is a challenging problem and remains an active research area. In this example, you train a re-identification network that uses the ResNet-50 architecture as its backbone. Network performance is reasonable for the amount of training data in this example and for the global feature structure of the network.
To improve the network performance, increase the amount of training data. Additional training data must include more challenging scenarios, such as occluded objects, and more varied individuals. If those challenging scenarios are missing, add synthetically occluded objects to increase network robustness. To further improve performance, you can improve the distortion of individual features in the problematic frames or use another network architecture as the backbone of the ReID network.
Helper Functions
helperCropImagesWithGroundtruth
Crop all source images in the ground truth data gTruth with the bounding box labels gTruth. Store the cropped images in organized subdirectories in dataFolder.
function helperCropImagesWithGroundtruth(gTruth,dataFolder) % Use gatherLabelData to obtain the label data from groundtruth. [labelData,timestamps] = gatherLabelData(gTruth,labelType.Rectangle,SampleFactor=1); % Write all of the video frames from the groundTruth data source. imageFrameWriteLoc = fullfile("videoFrames"); imgFileNames = writeFrames(gTruth,imageFrameWriteLoc,timestamps); imds = imageDatastore(imgFileNames{:}); blds = boxLabelDatastore(labelData{:}); combinedDs = combine(imds,blds); writeall(combinedDs,"videoFrames",WriteFcn=@(data,info,format)helperWriteCroppedData(data,info,format,dataFolder)) % Remove the video frame images. fprintf(1,"\nCleaning up %s directory.\n",imageFrameWriteLoc); rmdir(imageFrameWriteLoc,"s") end
helperWriteCroppedData
Crop, resize, and store image regions of interest (ROIs) from a combined datastore.
function helperWriteCroppedData(data,info,~,dataFolder) num = 1; for i = 1:size(data{1,2},1) personID = string(data{1,3}(i)); personIDFolder = fullfile(dataFolder,personID); if ~isfolder(personIDFolder) mkdir(personIDFolder) end frame = num2str(info.ReadInfo{1,2}.CurrentIndex); imgPath = fullfile(personIDFolder,strcat(frame,"_",num2str(num,'%02.f'),".jpg")); roi = data{1,2}(i,:); croppedImage = imcrop(data{1,1},roi); resizedImg = imresize(croppedImage,[384 192]); imwrite(resizedImg,imgPath); num = num + 1; end end
helperGenerateOcclusionData
Generate new training data images that have an individual inserted from another training image. See the Generate Training Data with Synthetic Object Occlusions section for more details.
function helperGenerateOcclusionData(img,writeInfo,~,datasetFolder) info = writeInfo.ReadInfo; occlusionDataFolder = writeInfo.Location; % Get the name of the training image. fileName = info.Filename; % Find the last slash in the image filename path to extract % only the actual image file name. if ispc slash = "\"; else slash = "/"; end slashIdx = strfind(info.Filename,slash); imgName = info.Filename(slashIdx(end)+1:end); % Set the output folder for the given indentity. imagesDataFolder = fullfile(occlusionDataFolder,datasetFolder,string(info.Label)); % Copy the original file to the occlusion training data folder if it % does not already exist. if ~isfile(fullfile(imagesDataFolder,imgName)) copyfile(fileName,fullfile(imagesDataFolder,imgName)); end numBlockErases = 3; for i = 1:numBlockErases % Select a random square window from the image. The area of the window is % between 4% and 15% of the area of the entire image. win = randomWindow2d(size(img),Scale=[0.04 0.15],DimensionRatio=[1 3;1 1]); % Determine the height and width of the erase region. hwin = diff(win.YLimits)+1; wwin = diff(win.XLimits)+1; % Erase the pixels within the erase region. Fill each pixel with a random color. img = imerase(img,win,FillValues=randi([1 255],[hwin wwin 3])); end imwrite(img,fullfile(imagesDataFolder,strcat(imgName(1:end-5),"_occlusion.jpeg"))); end
helperDownloadReIDNetwork
Download a pretrained ReID network.
function net = helperDownloadReIDNetwork() url = "https://ssd.mathworks.com/supportfiles/vision/data/pretrainedPersonReIDResNet_v2.zip"; zipFile = fullfile(pwd,"pretrainedPersonReIDResNet_v2.zip"); if ~exist(zipFile,"file") websave(zipFile,url); end fileName = fullfile(pwd,"personReIDResNet_v2.mat"); if ~exist(fileName,"file") unzip(zipFile,pwd); end pretrained = load(fileName); net = pretrained.net; end
helperUnzipData
Unzip the training data ZIP file.
function helperUnzipData(folder) zipFile = fullfile(folder,"pedestrianDataset.zip"); dataFolder = fullfile(folder,"pedestrianDataset"); if ~exist(dataFolder,"dir") unzip(zipFile,folder); end end
References
[1] Wojke, Nicolai, Alex Bewley, and Dietrich Paulus. "Simple Online and Realtime Tracking with a Deep Association Metric." In 2017 IEEE international conference on image processing (ICIP), 3645–49. Beijing: IEEE, 2017. https://doi.org/10.1109/ICIP.2017.8296962.
[2] Zheng, Liang, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qi Tian, "Scalable Person Re-identification: A Benchmark," In 2015 IEEE International Conference on Computer Vision (ICCV), 1116-24. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.133.