forecast
Forecast responses from Bayesian vector autoregression (VAR) model
Description
forecast is well suited for computing out-of-sample unconditional forecasts of a Bayesian VAR(p) model that does not contain an exogenous regression component. For advanced applications, such as out-of-sample conditional forecasting, VARX(p) model forecasting, missing value imputation, and Gibbs sampler specification for posterior predictive distribution estimation, see simsmooth.
YF = forecast(PriorMdl,numperiods,Y)YF over the length numperiods forecast horizon. Each period in YF is the mean of the posterior predictive distribution, which is derived from the posterior distribution of the prior Bayesian VAR(p) model
PriorMdl given the response data Y. The output YF represents the continuation of Y.
NaNs in the data indicate missing values, which forecast removes using list-wise deletion.
Examples
Consider the 3-D VAR(4) model for the US inflation (INFL), unemployment (UNRATE), and federal funds (FEDFUNDS) rates.
For all , is a series of independent 3-D normal innovations with a mean of 0 and covariance . Assume a diffuse prior distribution for the parameters .
Load and Preprocess Data
Load the US macroeconomic data set. Compute the inflation rate, stabilize the unemployment and federal funds rates, and remove missing values.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)]; DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTimeTable = rmmissing(DataTimeTable);
Create Prior Model
Create a diffuse prior model. Specify the response series names.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = bayesvarm(numseries,numlags,'SeriesNames',seriesnames);Forecast Responses
Directly forecast two years (eight quarters) of observations from the posterior predictive distribution. forecast estimates the posterior distribution of the parameters, and then forms the posterior predictive distribution.
numperiods = 8;
YF = forecast(PriorMdl,numperiods,rmDataTimeTable{:,seriesnames});YF is an 8-by-3 matrix of forecasted responses.
Plot the forecasted responses.
fh = rmDataTimeTable.Time(end) + calquarters(0:8); tiledlayout(3,1) for j = 1:PriorMdl.NumSeries nexttile plot(rmDataTimeTable.Time(end - 20:end),rmDataTimeTable{end - 20:end,seriesnames(j)},'r',... fh,[rmDataTimeTable{end,seriesnames(j)}; YF(:,j)],'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end
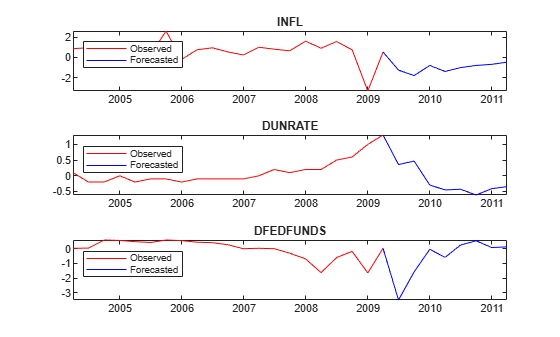
Consider the 3-D VAR(4) model of Forecast Responses from Posterior Predictive Distribution.
Load the US macroeconomic data set. Compute the inflation rate, stabilize the unemployment and federal funds rates, and remove missing values.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTimeTable.INFL = 100*[NaN; price2ret(DataTimeTable.CPIAUCSL)]; DataTimeTable.DUNRATE = [NaN; diff(DataTimeTable.UNRATE)]; DataTimeTable.DFEDFUNDS = [NaN; diff(DataTimeTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTimeTable = rmmissing(DataTimeTable);
Create a diffuse prior model. Specify the response series names.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = bayesvarm(numseries,numlags,'SeriesNames',seriesnames);Directly forecast two years (eight quarters) of response observations from the posterior predictive distribution. Return the posterior standard deviations.
numperiods = 8;
[YF,YStd] = forecast(PriorMdl,numperiods,rmDataTimeTable{:,seriesnames});YF and YStd are 8-by-3 matrices of forecasted responses and corresponding standard deviations, respectively.
Plot the forecasted responses and approximate 95% credible intervals.
fh = rmDataTimeTable.Time(end) + calquarters(0:8); for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(rmDataTimeTable.Time(end - 20:end),rmDataTimeTable{end - 20:end,seriesnames(j)},'r',... fh,[rmDataTimeTable{end,seriesnames(j)}; YF(:,j)],'b',... fh,[rmDataTimeTable{end,seriesnames(j)}; YF(:,j) + 1.96*YStd(:,j)],'b--',... fh,[rmDataTimeTable{end,seriesnames(j)}; YF(:,j) - 1.96*YStd(:,j)],'b--'); legend("Observed","Forecasted","Approximate 95% Credible Interval",'Location','NorthWest') title(seriesnames(j)) end
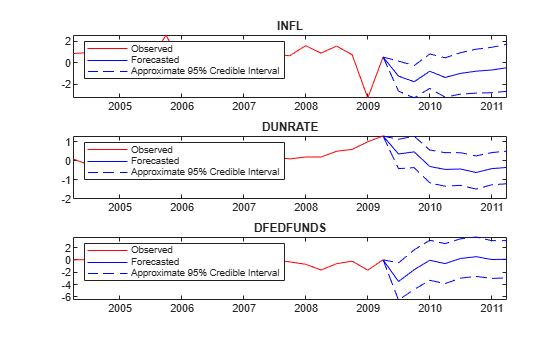
Input Arguments
Output Arguments
More About
Tips
Monte Carlo simulation is subject to variation. If
forecastuses Monte Carlo simulation, then estimates and inferences might vary when you callforecastmultiple times under seemingly equivalent conditions. To reproduce estimation results, set a random number seed by usingrngbefore callingforecast.
Algorithms
If the posterior predictive distribution is analytically intractable (true for most cases),
forecastimplements Markov Chain Monte Carlo (MCMC) sampling with Bayesian data augmentation to compute the mean and standard deviation of the posterior predictive distribution. To do so,forecastcallssimsmooth, which uses a computationally intensive procedure.Most Econometrics Toolbox™
forecastfunctions accept an estimated or posterior model object from which to generate forecasts. Such a model encompasses the parametric structure and data. However, theforecastfunction of Bayesian VAR models requires presample and estimation sample data to do the following:Perform Bayesian parameter updating to estimate posterior distributions.
forecastimplements MCMC sampling with Bayesian data augmentation, which includes a Kalman filter smoothing step that requires the entire observed series.Predict future responses in the presence of two sources of uncertainty:
Estimation noise ε1,…,εT, which induces parameter uncertainty
Forecast period noise εT+1,…,εT+
numperiods
References
[1] Litterman, Robert B. "Forecasting with Bayesian Vector Autoregressions: Five Years of Experience." Journal of Business and Economic Statistics 4, no. 1 (January 1986): 25–38. https://doi.org/10.2307/1391384.
Version History
Introduced in R2020a