splitapply
Split data into groups and apply function
Syntax
Description
To split data into groups and apply a function to the groups, use the
findgroups and splitapply functions
together. For more information about calculations on groups of data, see Calculations on Groups of Data.
Y = splitapply(func,X,G)X into groups specified by G and
applies the function func to each group. Then
splitapply returns Y as an array that
contains the concatenated outputs from func for the groups split
out of X. The input argument G is a vector of
positive integers that specifies the groups to which corresponding elements of
X belong.
The output Y and the group numbers G have
the same ordering.
If any elements of G are NaNs, then
splitapply omits the corresponding values in
X when it splits X into groups.
To create G, first use the findgroups function. Then use
splitapply.
Y = splitapply(func,T,G)T into groups, applies
func, and returns Y as an array. The
splitapply function treats the variables of
T as vectors, matrices, or cell arrays, depending on the data
types and sizes of the table variables. If T has
N variables, then func must accept
N input arguments.
[Y1,...,YM] = splitapply(___) splits variables
into groups and applies func to each group.
func returns multiple output arguments.
Y1,...,YM contains the concatenated outputs from
func for the groups split out of the input data variables.
func can return output arguments that belong to different
classes, but the class of each output must be the same each time
func is called. You can use this syntax with any of the input
arguments of the previous syntaxes.
The number of output arguments from func need not be the same
as the number of input arguments specified by X1,...,XN.
Examples
Input Arguments
Output Arguments
More About
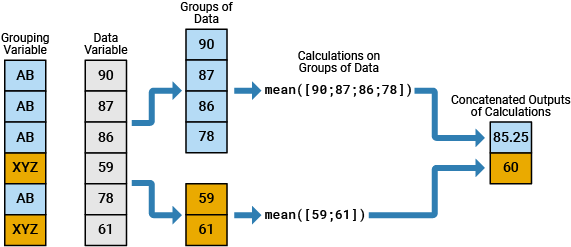
In data analysis, you commonly perform calculations on groups of data. For such calculations, you split one or more data variables into groups of data, perform a calculation on each group, and combine the results into one or more output variables. You can specify the groups using one or more grouping variables. The unique values in the grouping variables define the groups that the corresponding values of the data variables belong to.
For example, the diagram shows a simple grouped calculation that splits a
6-by-1 numeric vector into two groups of data, calculates the mean of each
group, and then combines the outputs into a 2-by-1 numeric vector. The
6-by-1 grouping variable has two unique values, AB and
XYZ.
You can specify grouping variables that have numbers, text, dates and times, categories, or bins.
Extended Capabilities
Version History
Introduced in R2015b