Train Agents Using Parallel Computing and GPUs
If you have Parallel Computing Toolbox™ software, you can run parallel simulations on multicore processors or GPUs. If you additionally have MATLAB® Parallel Server™ software, you can run parallel simulations on computer clusters or cloud resources.
When you use parallel computing to train an agent (by setting the
UseParallel training option), the training algorithm uses multiple
processes to scale up the number of simulations with the environment. For example, multiple
parallel workers can generate trajectories (synchronously or asynchronously). The client
process then learns from those trajectories. Therefore, with this option, multiple workers can
speed up the generation of data for learning. For more information on using parallel computing
to scale up simulations, see Using Multiple Processes.
You can also use a GPU for learning. This is different from parallelizing simulations. To
use a GPU for learning, set the UseDevice option to
"gpu" in the actor and critic objects of the agent. Generally GPU usage
is recommended when you are training from large batches of data, or the data is itself large,
like an image. Using GPUs for images can speed up learning. Because there is a cost associated
with copying data to and from a GPU, it might not be valuable to use GPU for learning if the
data is smaller size. For more information on using GPU for learning, see Using GPUs.
Independently on which devices you use to simulate or train the agent, once the agent has been trained, you can generate code to deploy the optimal policy on a CPU or GPU. This is explained in more detail in Generate Code from Trained Reinforcement Learning Policies.
Using Multiple Processes
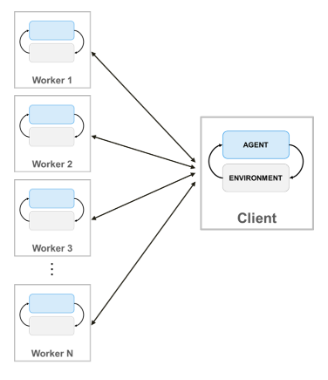
When you train agents using parallel computing, the parallel pool client (the MATLAB process that starts the training) sends copies of both its agent and environment to each parallel worker. Each worker simulates the agent within the environment and sends their simulation data back to the client. The client agent learns from the data sent by the workers and sends the updated policy parameters back to the workers.
Note
Parallel training and simulation of agents within multiagent environments is not supported.
Note
Due to the non-deterministic nature of parallel execution timing, the results of parallel training cannot in general be reproduced.
To train an agent using multiple processes you must pass to the train function an
rlTrainingOptions
object in which the UseParallel property is set to
true.
To create a parallel pool of N workers, use the following
syntax.
pool = parpool(N);
If you do not create a parallel pool using parpool (Parallel Computing Toolbox), the train function automatically creates one
using your default parallel pool settings. For more information on specifying these
settings, see Specify Your Parallel Settings (Parallel Computing Toolbox). Note that using a parallel pool of thread workers,
such as pool = parpool("threads"), is not supported.
For more information on configuring your training to use parallel computing, see the
UseParallel and ParallelizationOptions options
in rlTrainingOptions.
For an example on how to configure options for asynchronous advantage actor-critic (A3C)
agent training, see the last example in rlTrainingOptions.
For an example that trains an agent using parallel computing in MATLAB, see Train AC Agent to Balance Discrete Cart-Pole Using Parallel Computing. For an example that trains an agent using parallel computing in Simulink®, see Train DQN Agent for Lane Keeping Assist Using Parallel Computing and Train Biped Robot to Walk Using Reinforcement Learning Agents.
Agent-Specific Parallel Training Considerations
Reinforcement learning agents can be trained in parallel in two main ways, experience-based parallelization, in which the workers only calculate experiences, and gradient-based parallelization, in which the workers also calculate the gradients that allow the agent approximators to learn. You do not need to specify when using gradient vs. experience based parallelization, the software automatically selects the parallelization type depending on the agent type. However, you can specify whether to use asynchronous training instead of synchronous training in some cases.
Experience-Based Parallelization (DQN, DDPG, TD3, SAC, PPO, TRPO)
When training an DQN, DDPG, TD3, SAC, PPO or TRPO agent in parallel, the environment simulation is done by the workers and the gradient computation is done by the client. Specifically, the workers simulate (their copy of) the agent within (their copy of) the environment, and send experience data (observation, action, reward, next observation, and a termination signal) to the client. The client then computes the gradients from experiences, updates the agent parameters and sends the updated parameters back to the workers, which then continue to perform simulations using their copy of the updated agent.
This type of parallel training is also known as experience-based parallelization, and
can run using asynchronous training (to
specify asynchronous training, set the Mode property of the rlTrainingOptions
object that you pass to the train function to
"async"). Asynchronous training can improve performance for
off-policy agents.
With asynchronous training, the client agent calculates gradients and updates agent parameters from the received experiences, without waiting to receive experiences from all the workers. The client then sends the updated parameters back to the worker that provided the experiences. Then, while other workers are still running, the worker updates its copy of the agent and continues to generate experiences using its copy of the environment.
Experience-based parallelization can also run using synchronous
training, (to specify synchronous training, set the Mode property of
the rlTrainingOptions
object that you pass to the train function to
"sync"). Synchronous training is the default behavior for all agents,
and often yields better performance for on-policy agents.
With synchronous training, the client agent waits to receive experiences from all of the workers and then calculates the gradients from all these experiences. The client updates the agent parameters, and sends the updated parameters to all the workers at the same time. Then, all workers use a single updated agent copy, together with their copy of the environment, to generate experiences. Because each worker must pause execution until all the workers are finished, synchronous training only advances as fast as the slowest worker allows.
With either synchronous or asynchronous training, experience-based parallelization can reduce training time only when the computational cost of simulating the environment is high compared to the cost of optimizing network parameters. Otherwise, when the environment simulation is fast enough, some workers might lie idle waiting for the client to learn and send back the updated parameters.
In other words, experience-based parallelization can improve sample efficiency (intended as the number of samples an agent can process within a given time) only when the ratio R between the environment step complexity and the learning complexity is large. If both environment simulation and gradient computation (that is, learning) are similarly computationally expensive, experience-based parallelization is unlikely to improve sample efficiency. In this case, for off-policy agents that are supported in parallel (DQN, DDPG, TD3, and SAC) you can reduce the mini-batch size to make R larger, thereby improving sample efficiency.
Note
For experience-based parallelization, do not use all of your processor cores for parallel training. For example, if your CPU has six cores, train with four workers. Doing so provides more resources for the parallel pool client to compute gradients based on the experiences sent back from the workers.
For an example of experience-based parallel training, see Train DQN Agent for Lane Keeping Assist Using Parallel Computing.
Gradient-Based Parallelization (AC and PG)
When training an AC or PG agent in parallel, both the environment simulation and gradient computations are done by the workers. Specifically, workers simulate (their copy of) the agent within (their copy of) the environment, obtain the experiences, compute the gradients from the experiences, and send the gradients to the client. The client averages the gradients, updates the agent parameters and sends the updated parameters back to the workers so they can continue to perform simulations using an updated copy of the agent.
For PG agents gradient-based parallelization requires synchronous training. For AC agent, you can still chose either synchronous or asynchronous training. The algorithm used to train an AC agent in asynchronous mode is also referred to as asynchronous advantage AC (A3C).
Synchronous gradient-based parallelization allows you to achieve, in principle, a speed improvement which is nearly linear in the number of workers. However, since each worker must pause execution until all workers are finished, synchronous training only advances as fast as the slowest worker allows.
In general, limiting the number of workers in order to leave some processor cores for the client is not necessary when using gradient-based parallelization, because the gradients are not computed on the client. Therefore, for gradient-based parallelization, it might be beneficial to use all your processor cores for parallel training.
For an example of gradient-based parallel training, see Train AC Agent to Balance Discrete Cart-Pole Using Parallel Computing.
Using GPUs
You can speed up training by performing actor and critic operations (such as gradient
computation and prediction), on a local GPU rather than a CPU. To do so, when creating a
critic or actor, set its UseDevice option to "gpu"
instead of "cpu".
The "gpu" option requires both Parallel Computing Toolbox software and a CUDA® enabled NVIDIA® GPU. For more information on supported GPUs see GPU Computing Requirements (Parallel Computing Toolbox).
You can use gpuDevice (Parallel Computing Toolbox) to query or select a local GPU
device to be used with MATLAB.
Using GPUs is likely to be beneficial when you have a deep neural network in the actor or critic which has large batch sizes or needs to perform operations such as multiple convolutional layers on input images.
For an example on how to train an agent using the GPU, see Train DDPG Agent with Custom Networks Using Image Observation.
Using Both Multiple Processes and GPUs
You can also train agents using both multiple processes and a local GPU (previously
selected using gpuDevice (Parallel Computing Toolbox)) at the same time. To do so, first
create a critic or actor approximator object in which the UseDevice
option is set to "gpu". You can then use the critic and actor to create
an agent, and then train the agent using multiple processes. This is done by creating an
rlTrainingOptions
object in which UseParallel is set to true and
passing it to the train
function.
For gradient-based parallelization, (which must run in synchronous mode) the environment simulation is done by the workers, which also use their local GPU to calculate the gradients and perform a prediction step. The gradients are then sent back to the parallel pool client process which calculates the averages, updates the network parameters and sends them back to the workers so they continue to simulate the agent, with the new parameters, against the environment.
For experience-based parallelization, (which can run in asynchronous mode), the workers simulate the agent against the environment, and send experiences data back to the parallel pool client. The client then uses its local GPU to compute the gradients from the experiences, then updates the network parameters and sends the updated parameters back to the workers, which continue to simulate the agent, with the new parameters, against the environment.
Note that when using both parallel processing and GPU to train PPO agents, the workers use their local GPU to compute the advantages, and then send processed experience trajectories (which include advantages, targets and action probabilities) back to the client.
See Also
Functions
Objects
rlTrainingOptions|gpuDevice(Parallel Computing Toolbox)
Topics
- Train AC Agent to Balance Discrete Cart-Pole Using Parallel Computing
- Train DQN Agent for Lane Keeping Assist Using Parallel Computing
- Train Biped Robot to Walk Using Reinforcement Learning Agents
- Train DDPG Agent with Custom Networks Using Image Observation
- Train Reinforcement Learning Agents
- GPU Computing Requirements (Parallel Computing Toolbox)
- Reinforcement Learning Agents
- Create Actors, Critics, and Policy Objects
- Train Reinforcement Learning Agents