CensoredLinearModel
Description
A CensoredLinearModel object contains the results of fitting a
linear regression model to censored data. An observation is censored if
at least one bound on its value is known while the exact value remains unknown.
Use the properties of a CensoredLinearModel object to investigate a
fitted censored linear regression model. The object properties include information about
coefficient estimates, summary statistics, residuals, and censoring. Use the object functions
to predict responses, generate random values, and visualize the linear regression model.
Creation
Create a CensoredLinearModel object using fitlmcens.
Properties
Object Functions
compact | Create compact censored linear regression model |
plotResiduals | Plot residuals of censored linear regression model |
plotSlice | Plot of slices through fitted censored linear regression surface |
predict | Predict responses of censored linear regression model |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
feval | Predict responses of censored linear regression model using one input for each predictor |
random | Simulate responses with random noise for censored linear regression model |
coefCI | Confidence intervals of coefficient estimates for censored linear regression model |
coefTest | Linear hypothesis test on censored linear regression model coefficients |
Examples
Load the readmissiontimes sample data.
load readmissiontimesThe variables Age, Weight, and ReadmissionTime contain data for patient age, weight, and time of readmission. The Censored variable contains censoring information for ReadmissionTime.
Save Age, Weight, and ReadmissionTime in a table.
tbl = table(Age,Weight,ReadmissionTime);
Fit a censored linear regression model using Age, Weight, and Smoker as the predictor variables, ReadmissionTime as the response, and Censored as the censoring information. Because ReadmissionTime is the last column in tbl, you do not need to specify the ResponseVarName argument.
mdl1 = fitlmcens(tbl,Censoring=Censored)
mdl1 =
Censored linear regression model
ReadmissionTime ~ 1 + Age + Weight
Estimated Coefficients:
Estimate SE tStat pValue
_________ ________ ________ __________
(Intercept) 28.62 3.5313 8.1047 1.7047e-12
Age -0.060686 0.061984 -0.97905 0.33001
Weight -0.11977 0.017199 -6.9638 4.1162e-10
Sigma: 4.245
Number of observations: 100, Error degrees of freedom: 96
25 right-censored observations
75 uncensored observations
Likelihood ratio statistic vs. constant model: 39, p-value = 3.47e-09
mdl1 is a CensoredLinearModel object that includes the results of fitting a censored linear regression model to the data. The output display includes information about the model, statistics for each model term, and the censored observations. The p-values for the Weight and Age terms indicate that Weight has a statistically significant effect on patient readmission time and Age does not.
Fit another model to the data, using only the Weight term.
mdl2 = fitlmcens(tbl,"ReadmissionTime~Weight",Censoring=Censored)mdl2 =
Censored linear regression model
ReadmissionTime ~ 1 + Weight
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ _______ __________
(Intercept) 26.398 2.7107 9.7387 4.9168e-16
Weight -0.12041 0.01729 -6.9642 3.9554e-10
Sigma: 4.273
Number of observations: 100, Error degrees of freedom: 97
25 right-censored observations
75 uncensored observations
Likelihood ratio statistic vs. constant model: 38, p-value = 7.06e-10
The result for Likelihood ratio statistic vs. constant model shows that mdl2 is a slightly better fit than mdl1.
Load the censoreddata sample data.
load censoreddata.matThe matrix X contains data for three predictors, and the matrix yint contains bounds for a censored response variable.
Fit a linear regression model to the censored data in X and yint.
mdl = fitlmcens(X,yint);
Display a probability plot of the standardized residuals.
plotResiduals(mdl,"probability",ResidualType="standardized")
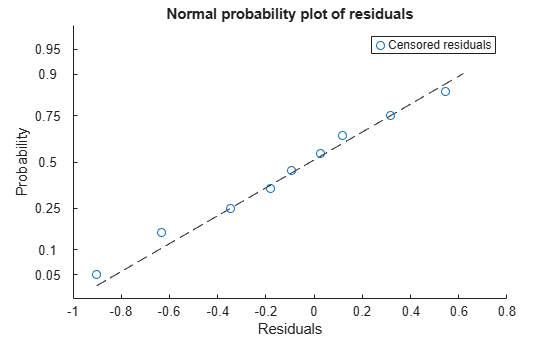
The plot shows that the standardized residuals have a normal distribution (approximately).
Load the readmissiontimes sample data.
load readmissiontimesThe variables Age, Weight, Smoker, and ReadmissionTime contain data for patient age, weight, smoking status, and time of readmission. The Censored variable contains censoring information for ReadmissionTime.
Save Age, Weight, Smoker, ReadmissionTime, and Censored in a table.
tbl = table(Age,Weight,Smoker,ReadmissionTime,Censored);
Fit a censored linear regression model using Age, Weight, and Smoker as the predictor variables, ReadmissionTime as the response, and Censored as the censoring information. Specify that smoker is a categorical variable.
mdl = fitlmcens(tbl,"ReadmissionTime",Censoring="Censored",CategoricalVars="Smoker");
Display the estimates, standard errors, t-statistics, and p-values for the model coefficients.
mdl.Coefficients
ans=4×4 table
Estimate SE tStat pValue
_________ ________ ________ __________
(Intercept) 27.74 3.4008 8.1569 1.4048e-12
Age -0.053476 0.059514 -0.89854 0.37117
Weight -0.11101 0.016823 -6.5986 2.3484e-09
Smoker_1 -2.3455 0.93105 -2.5192 0.013434
The p-values for the coefficients indicate that not enough evidence exists to conclude that age has a statistically significant effect on patient readmission time. Note that the model does not contain a coefficient corresponding to Smoker=0, indicating that nonsmokers are the reference category.
Generate new predictor data from the ranges for Age and Weight using the meshgrid function.
[ageNew,weightNew] = meshgrid(25:50,100:200);
Save the coefficient estimates for the fitted model in a variable named coefs, and display the model formula.
coefs = mdl.Coefficients.Estimate; mdl.Formula
ans = ReadmissionTime ~ 1 + Age + Weight + Smoker
Create a vector of indices for the observations in the fitting data that correspond to smokers. Generate new response data for smokers using the model formula and coefs.
idx = Smoker==1; resNew = coefs(1) + coefs(2)*ageNew + coefs(3)*weightNew + coefs(4);
Use the surf and scatter3 functions to plot a surface of the new data together with the fitting data, and the fitted responses corresponding to smokers.
surf(ageNew,weightNew,resNew,FaceAlpha=0.2,FaceColor="k",EdgeColor="none") % Regression surface hold on scatter3(Age(idx),Weight(idx),ReadmissionTime(idx),"x",SizeData=30) % Data used to fit the model scatter3(Age(idx),Weight(idx),mdl.Fitted(idx),"Filled",SizeData=30) % Fitted response data legend("Regression surface","Fitted values","Data") xlabel("Age") ylabel("Weight") zlabel("Readmission Time") view(-85,20)

The plot shows the fitted responses in blue on the gray response surface. The surface passes through the bulk of the data used to fit the model, shown with red x markers.
References
[1] Allison, P. D. Measures of Fit for Logistic Regression. Statistical Horizons LLC and the University of Pennsylvania, 2014.
[2] Law, M., and Jackson, D. Residual Plots for Linear Regression Models with Censored Outcome Data: A Refined Method for Visualizing Residual Uncertainty, Communications in Statistics - Simulation and Computation, vol. 46, no. 4, pp. 3159–71, 2017.
Version History
Introduced in R2025a