fsrmrmr
Rank features for regression using minimum redundancy maximum relevance (MRMR) algorithm
Since R2022a
Syntax
Description
fsrmrmr ranks features (predictors) using the MRMR algorithm to
identify important predictors for regression problems.
To perform MRMR-based feature ranking for classification, see fscmrmr.
idx = fsrmrmr(Tbl,ResponseVarName)idx, ordered by predictor importance
(from most important to least important). The table Tbl contains the
predictor variables and a response variable, ResponseVarName, which
contains the response values. You can use idx to select important
predictors for regression problems.
idx = fsrmrmr(Tbl,formula)Tbl by using formula. For example,
fsrmrmr(cartable,"MPG ~ Acceleration + Displacement + Horsepower")
ranks the Acceleration, Displacement, and
Horsepower predictors in cartable using the response
variable MPG in cartable.
idx = fsrmrmr(___,Name=Value)
Examples
Simulate 1000 observations from the model .
is a 1000-by-10 matrix of standard normal elements.
e is a vector of random normal errors with mean 0 and standard deviation 0.3.
rng("default") % For reproducibility X = randn(1000,10); Y = X(:,4) + 2*X(:,7) + 0.3*randn(1000,1);
Rank the predictors based on importance.
idx = fsrmrmr(X,Y);
Select the top two most important predictors.
idx(1:2)
ans = 1×2
7 4
The function identifies the seventh and fourth columns of X as the most important predictors of Y.
Load the carbig data set, and create a table containing the different variables. Include the response variable MPG as the last variable in the table.
load carbig cartable = table(Acceleration,Cylinders,Displacement, ... Horsepower,Model_Year,Weight,Origin,MPG);
Rank the predictors based on importance. Specify the response variable.
[idx,scores] = fsrmrmr(cartable,"MPG");Note: If fsrmrmr uses a subset of variables in a table as predictors, then the function indexes the subset of predictors only. The returned indices do not count the variables that the function does not rank (including the response variable).
Create a bar plot of the predictor importance scores. Use the predictor names for the x-axis tick labels.
bar(scores(idx)) xlabel("Predictor rank") ylabel("Predictor importance score") predictorNames = cartable.Properties.VariableNames(1:end-1); xticklabels(strrep(predictorNames(idx),"_","\_")) xtickangle(45)
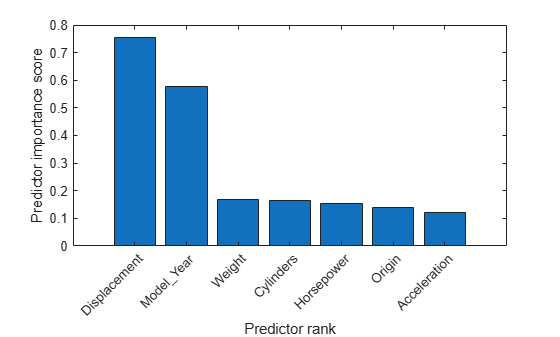
The drop in score between the second and third most important predictors is large, while the drops after the third predictor are relatively small. A drop in the importance score represents the confidence of feature selection. Therefore, the large drop implies that the software is confident of selecting the second most important predictor, given the selection of the most important predictor. The small drops indicate that the differences in predictor importance are not significant.
Select the top two most important predictors.
idx(1:2)
ans = 1×2
3 5
The third column of cartable is the most important predictor of MPG. The fifth column of cartable is the second most important predictor of MPG.
To improve the performance of a regression model, generate new features by using genrfeatures and then select the most important predictors by using fsrmrmr. Compare the test set performance of the model trained using only original features to the performance of the model trained using the most important generated features.
Read power outage data into the workspace as a table. Remove observations with missing values, and display the first few rows of the table.
outages = readtable("outages.csv");
Tbl = rmmissing(outages);
head(Tbl) Region OutageTime Loss Customers RestorationTime Cause
_____________ ________________ ______ __________ ________________ ___________________
{'SouthWest'} 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 {'winter storm' }
{'SouthEast'} 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 {'winter storm' }
{'West' } 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 {'equipment fault'}
{'MidWest' } 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 {'severe storm' }
{'West' } 2003-06-18 02:49 0 0 2003-06-18 10:54 {'attack' }
{'NorthEast'} 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 {'fire' }
{'MidWest' } 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 {'equipment fault'}
{'SouthEast'} 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 {'equipment fault'}
Some of the variables, such as OutageTime and RestorationTime, have data types that are not supported by regression model training functions like fitrensemble.
Partition the data set into a training set and a test set by using cvpartition. Use approximately 70% of the observations as training data and the other 30% as test data.
rng("default") % For reproducibility of the data partition c = cvpartition(length(Tbl.Loss),"Holdout",0.30); trainTbl = Tbl(training(c),:); testTbl = Tbl(test(c),:);
Identify and remove outliers of Customers from the training data by using the isoutlier function.
[customersIdx,customersL,customersU] = isoutlier(trainTbl.Customers); trainTbl(customersIdx,:) = [];
Remove the outliers of Customers from the test data by using the same lower and upper thresholds computed on the training data.
testTbl(testTbl.Customers < customersL | testTbl.Customers > customersU,:) = [];
Generate 35 features from the predictors in trainTbl that can be used to train a bagged ensemble. Specify the Loss variable as the response and MRMR as the feature selection method.
[Transformer,newTrainTbl] = genrfeatures(trainTbl,"Loss",35, ... TargetLearner="bag",FeatureSelectionMethod="mrmr");
The returned table newTrainTbl contains various engineered features. The first three columns of newTrainTbl are the original features in trainTbl that can be used to train a regression model using the fitrensemble function, and the last column of newTrainTbl is the response variable Loss.
originalIdx = 1:3; head(newTrainTbl(:,[originalIdx end]))
c(Region) Customers c(Cause) Loss
_________ __________ _______________ ______
SouthEast 1.4294e+05 winter storm 289.4
West 3.4037e+05 equipment fault 434.81
MidWest 2.1275e+05 severe storm 186.44
West 0 attack 0
MidWest 66104 equipment fault 286.72
SouthEast 36073 equipment fault 73.387
SouthEast 1.0698e+05 winter storm 46.918
NorthEast 1.0444e+05 winter storm 255.45
Rank the predictors in newTrainTbl. Specify the response variable.
[idx,scores] = fsrmrmr(newTrainTbl,"Loss");Note: If fsrmrmr uses a subset of variables in a table as predictors, then the function indexes the subset only. The returned indices do not count the variables that the function does not rank (including the response variable).
Create a bar plot of the predictor importance scores.
bar(scores(idx)) xlabel("Predictor rank") ylabel("Predictor importance score")
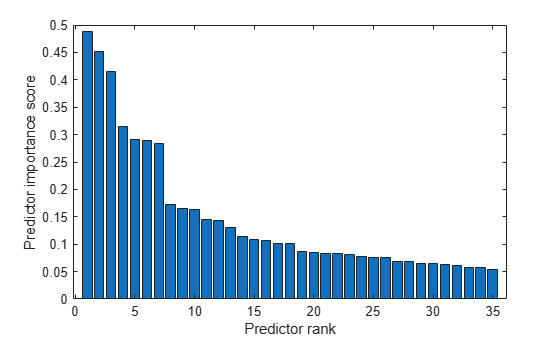
Because there is a large gap between the scores of the seventh and eighth most important predictors, select the seven most important features to train a bagged ensemble model.
importantIdx = idx(1:7); fsMdl = fitrensemble(newTrainTbl(:,importantIdx),newTrainTbl.Loss, ... Method="Bag");
For comparison, train another bagged ensemble model using the three original predictors that can be used for model training.
originalMdl = fitrensemble(newTrainTbl(:,originalIdx),newTrainTbl.Loss, ... Method="Bag");
Transform the test data set.
newTestTbl = transform(Transformer,testTbl);
Compute the test mean squared error (MSE) of the two regression models.
fsMSE = loss(fsMdl,newTestTbl(:,importantIdx), ...
newTestTbl.Loss)fsMSE = 1.0867e+06
originalMSE = loss(originalMdl,newTestTbl(:,originalIdx), ...
newTestTbl.Loss)originalMSE = 1.0961e+06
fsMSE is less than originalMSE, which suggests that the bagged ensemble trained on the most important generated features performs slightly better than the bagged ensemble trained on the original features.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Ding, C., and H. Peng. "Minimum redundancy feature selection from microarray gene expression data." Journal of Bioinformatics and Computational Biology. Vol. 3, Number 2, 2005, pp. 185–205.
[2] Darbellay, G. A., and I. Vajda. "Estimation of the information by an adaptive partitioning of the observation space." IEEE Transactions on Information Theory. Vol. 45, Number 4, 1999, pp. 1315–1321.
Version History
Introduced in R2022a