What is Structure from Motion?
Structure from motion (SfM) is the process of estimating the 3-D structure of a scene from a set of 2-D images. SfM is used in many applications, such as 3-D scanning , augmented reality, and visual simultaneous localization and mapping (vSLAM).
SfM can be computed in many different ways. The way in which you approach the problem depends on different factors, such as the number and type of cameras used, and whether the images are ordered. If the images are taken with a single calibrated camera, then the 3-D structure and camera motion can only be recovered up to scale. up to scale means that you can rescale the structure and the magnitude of the camera motion and still maintain observations. For example, if you put a camera close to an object, you can see the same image as when you enlarge the object and move the camera far away. If you want to compute the actual scale of the structure and motion in world units, you need additional information, such as:
The size of an object in the scene
Information from another sensor, for example, an odometer.
Structure from Motion from Two Views
For the simple case of structure from two stationary cameras or one moving camera, one view must be considered camera 1 and the other one camera 2. In this scenario, the algorithm assumes that camera 1 is at the origin and its optical axis lies along the z-axis.
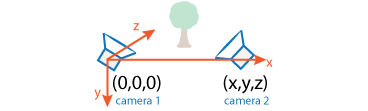
SfM requires point correspondences between images. Find corresponding points either by matching features or tracking points from image 1 to image 2. Feature tracking techniques, such as Kanade-Lucas-Tomasi (KLT) algorithm, work well when the cameras are close together. As cameras move further apart, the KLT algorithm breaks down, and feature matching can be used instead.

Distance Between Cameras (Baseline) Method for Finding Point Correspondences Example Wide Match features using matchFeaturesFind Image Rotation and Scale Using Automated Feature Matching Narrow Track features using vision.PointTrackerFace Detection and Tracking Using the KLT Algorithm To find the pose of the second camera relative to the first camera, you must compute the fundamental matrix. Use the corresponding points found in the previous step for the computation. The fundamental matrix describes the epipolar geometry of the two cameras. It relates a point in one camera to an epipolar line in the other camera. Use the
estimateFundamentalMatrixfunction to estimate the fundamental matrix.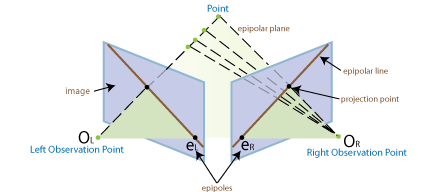
Input the fundamental matrix to the
estrelposefunction.estrelposereturns the pose the second camera in the coordinate system of the first camera. The location can only be computed up to scale, so the distance between two cameras is set to 1. In other words, the distance between the cameras is defined to be 1 unit.Determine the 3-D locations of the matched points using
triangulate. Because the pose is up to scale, when you compute the structure, it has the right shape but not the actual size.The
triangulatefunction takes two camera matrices, which you can compute using thecameraProjectionfunction.Use
pcshoworpcplayerto display the reconstruction. UseplotCamerato visualize the camera poses.
To recover the scale of the reconstruction, you need additional information. One method to recover the scale is to detect an object of a known size in the scene. The Structure from Motion from Two Views example shows how to recover scale by detecting a sphere of a known size in the point cloud of the scene.
Structure from Motion from Multiple Views
For most applications, such as robotics and autonomous driving, SfM uses more than two views.
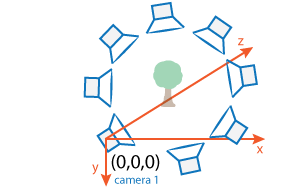
The approach used for SfM from two views can be extended for multiple views. The set
of multiple views used for SfM can be ordered or unordered. The approach taken here
assumes an ordered sequence of views. SfM from multiple views requires point
correspondences across multiple images, called tracks. A typical
approach is to compute the tracks from pairwise point correspondences. You can use
imageviewset to manage the pairwise correspondences and find the tracks.
Each track corresponds to a 3-D point in the scene. To compute 3-D points from the
tracks, use triangulateMultiview. The 3-D point can
be stored in a worldpointset object. The worldpointset object also stores the correspondence between the 3-D points
and the 2-D image points across camera views.

Using the approach in SfM from two views, you can find the pose of camera 2 relative
to camera 1. To extend this approach to the multiple view case, find the pose of camera
3 relative to camera 2, and so on. The relative poses must be transformed into a common
coordinate system. Typically, all camera poses are computed relative to camera 1 so that
all poses are in the same coordinate system. You can use imageviewset to manage camera poses. The imageviewset object stores the views and connections between the views.
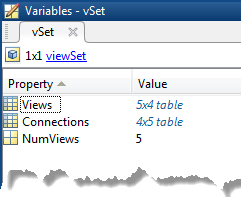
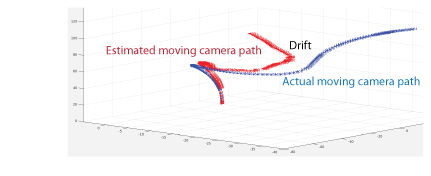
Every camera pose estimation from one view to the next contains errors. The errors
arise from imprecise point localization in images, and from noisy matches and imprecise
calibration. These errors accumulate as the number of views increases, an effect known
as drift. One way to reduce the drift, is to refine camera poses
and 3-D point locations. The nonlinear optimization algorithm, called bundle
adjustment, implemented by the bundleAdjustment function, can be used for the refinement. You can fix
the 3-D point locations and refine only the camera poses using bundleAdjustmentMotion. You can also fix the camera poses and refine
only the 3-D locations using bundleAdjustmentStructure.
Another method of reducing drift is by using pose graph
optimization over the imageviewset object. Once there is a loop closure detected, add anew
connection to the imageviewset object and use the optimizePoses function to refine the camera poses constrained by
relative poses.
The Structure from Motion from Two Views example shows how
to reconstruct a 3-D scene from a sequence of 2-D views. The example uses the Camera Calibrator app to calibrate the camera that takes the views. It uses
an imageviewset object to store and manage the data associated with each
view.
The Monocular Visual Simultaneous Localization and Mapping example shows you how to process image data from a monocular camera to build a map of an indoor environment and estimate the motion of the camera.
See Also
Apps
Functions
bundleAdjustment|bundleAdjustmentStructure|bundleAdjustmentMotion|estrelpose|cameraProjection|triangulateMultiview|estimateFundamentalMatrix|matchFeatures
Objects
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)