ivector
Extract i-vector
Description
w = ivector(ivs,data,Name,Value)trainClassifier.
Examples
An i-vector system consists of a trainable front end that learns how to extract i-vectors based on unlabeled data, and a trainable backend that learns how to classify i-vectors based on labeled data. In this example, you apply an i-vector system to the task of word recognition. First, evaluate the accuracy of the i-vector system using the classifiers included in a traditional i-vector system: probabilistic linear discriminant analysis (PLDA) and cosine similarity scoring (CSS). Next, evaluate the accuracy of the system if you replace the classifier with bidirectional long short-term memory (BiLSTM) network or a K-nearest neighbors classifier.
Create Training and Validation Sets
Download the Free Spoken Digit Dataset (FSDD) [1]. FSDD consists of short audio files with spoken digits (0-9).
loc = matlab.internal.examples.downloadSupportFile("audio","FSDD.zip"); unzip(loc,pwd)
Create an audioDatastore to point to the recordings. Get the sample rate of the data set.
ads = audioDatastore(pwd,IncludeSubfolders=true); [~,adsInfo] = read(ads); fs = adsInfo.SampleRate;
The first element of the file names is the digit spoken in the file. Get the first element of the file names, convert them to categorical, and then set the Labels property of the audioDatastore.
[~,filenames] = cellfun(@(x)fileparts(x),ads.Files,UniformOutput=false); ads.Labels = categorical(string(cellfun(@(x)x(1),filenames)));
To split the datastore into a development set and a validation set, use splitEachLabel. Allocate 80% of the data for development and the remaining 20% for validation.
[adsTrain,adsValidation] = splitEachLabel(ads,0.8);
Evaluate Traditional i-vector Backend Performance
Create an i-vector system that expects audio input at a sample rate of 8 kHz and does not perform speech detection.
wordRecognizer = ivectorSystem(DetectSpeech=false,SampleRate=fs)
wordRecognizer =
ivectorSystem with properties:
InputType: 'audio'
SampleRate: 8000
DetectSpeech: 0
Verbose: 1
EnrolledLabels: [0×2 table]
Train the i-vector extractor using the data in the training set.
trainExtractor(wordRecognizer,adsTrain, ... UBMNumComponents=64, ... UBMNumIterations=5, ... ... TVSRank=32, ... TVSNumIterations=5);
Calculating standardization factors ....done. Training universal background model ........done. Training total variability space ........done. i-vector extractor training complete.
Train the i-vector classifier using the data in the training data set and the corresponding labels.
trainClassifier(wordRecognizer,adsTrain,adsTrain.Labels, ... NumEigenvectors=10, ... ... PLDANumDimensions=10, ... PLDANumIterations=5);
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model ........done. i-vector classifier training complete.
Calibrate the scores output by wordRecognizer so they can be interpreted as a measure of confidence in a positive decision. Enroll labels into the system using the entire training set.
calibrate(wordRecognizer,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
enroll(wordRecognizer,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Enrolling i-vectors .............done. Enrollment complete.
In a loop, read audio from the validation datastore, identify the most-likely word present according to the specified scorer, and save the prediction for analysis.
trueLabels = adsValidation.Labels; predictedLabels = trueLabels; reset(adsValidation) scorer ="plda"; for ii = 1:numel(trueLabels) audioIn = read(adsValidation); to = identify(wordRecognizer,audioIn,scorer); predictedLabels(ii) = to.Label(1); end
Display a confusion chart of the i-vector system's performance on the validation set.
figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) confusionchart(trueLabels,predictedLabels, ... ColumnSummary="column-normalized", ... RowSummary="row-normalized", ... Title=sprintf('Accuracy = %0.2f (%%)',100*mean(predictedLabels==trueLabels)))
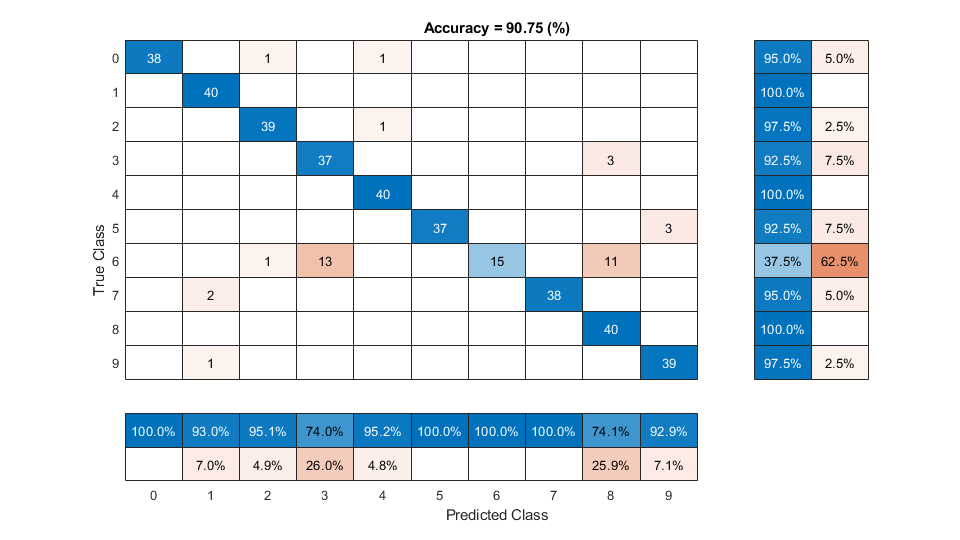
Evaluate Deep Learning Backend Performance
Next, train a fully-connected network using i-vectors as input.
ivectorsTrain = (ivector(wordRecognizer,adsTrain))'; ivectorsValidation = (ivector(wordRecognizer,adsValidation))';
Define a fully connected network.
layers = [ ... featureInputLayer(size(ivectorsTrain,2),Normalization="none") fullyConnectedLayer(128) dropoutLayer(0.4) fullyConnectedLayer(256) dropoutLayer(0.4) fullyConnectedLayer(256) dropoutLayer(0.4) fullyConnectedLayer(128) dropoutLayer(0.4) fullyConnectedLayer(numel(unique(adsTrain.Labels))) softmaxLayer classificationLayer];
Define training parameters.
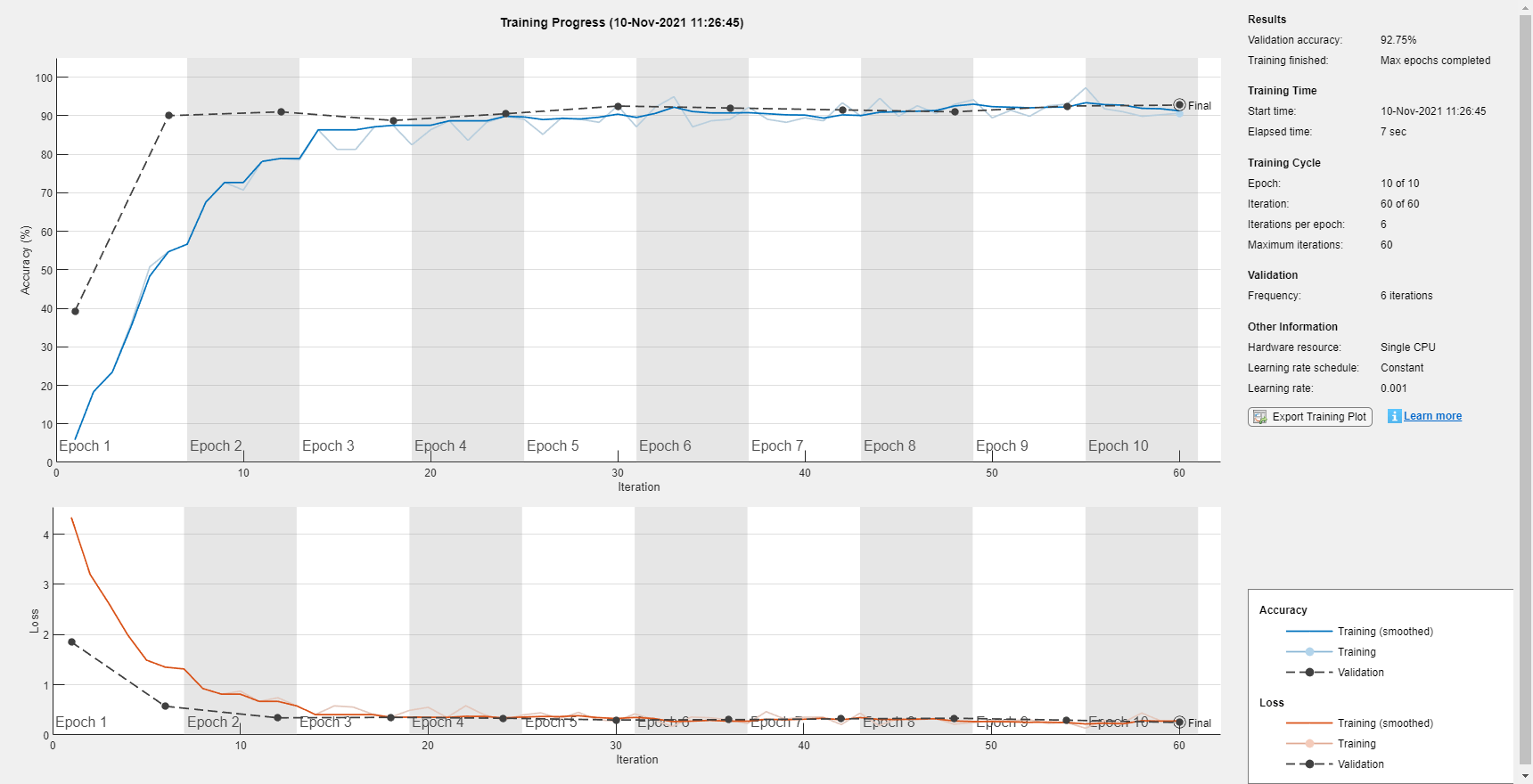
miniBatchSize = 256; validationFrequency = floor(numel(adsTrain.Labels)/miniBatchSize); options = trainingOptions("adam", ... MaxEpochs=10, ... MiniBatchSize=miniBatchSize, ... Plots="training-progress", ... Verbose=false, ... Shuffle="every-epoch", ... ValidationData={ivectorsValidation,adsValidation.Labels}, ... ValidationFrequency=validationFrequency);
Train the network.
net = trainNetwork(ivectorsTrain,adsTrain.Labels,layers,options);
Evaluate the performance of the deep learning backend using a confusion chart.
predictedLabels = classify(net,ivectorsValidation); trueLabels = adsValidation.Labels; figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) confusionchart(trueLabels,predictedLabels, ... ColumnSummary="column-normalized", ... RowSummary="row-normalized", ... Title=sprintf('Accuracy = %0.2f (%%)',100*mean(predictedLabels==trueLabels)))
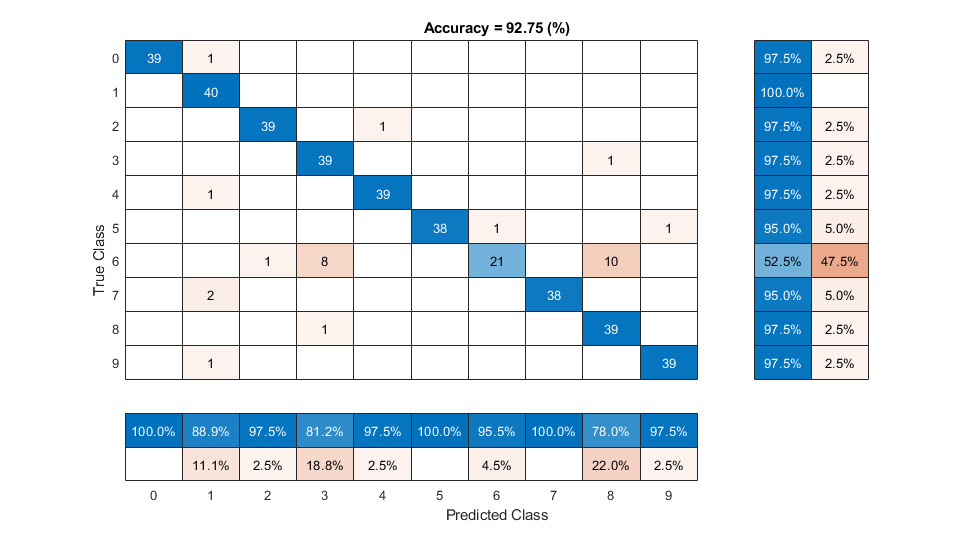
Evaluate KNN Backend Performance
Train and evaluate i-vectors with a k-nearest neighbor (KNN) backend.
Use fitcknn to train a KNN model.
classificationKNN = fitcknn(... ivectorsTrain, ... adsTrain.Labels, ... Distance="Euclidean", ... Exponent=[], ... NumNeighbors=10, ... DistanceWeight="SquaredInverse", ... Standardize=true, ... ClassNames=unique(adsTrain.Labels));
Evaluate the KNN backend.
predictedLabels = predict(classificationKNN,ivectorsValidation); trueLabels = adsValidation.Labels; figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) confusionchart(trueLabels,predictedLabels, ... ColumnSummary="column-normalized", ... RowSummary="row-normalized", ... Title=sprintf('Accuracy = %0.2f (%%)',100*mean(predictedLabels==trueLabels)))
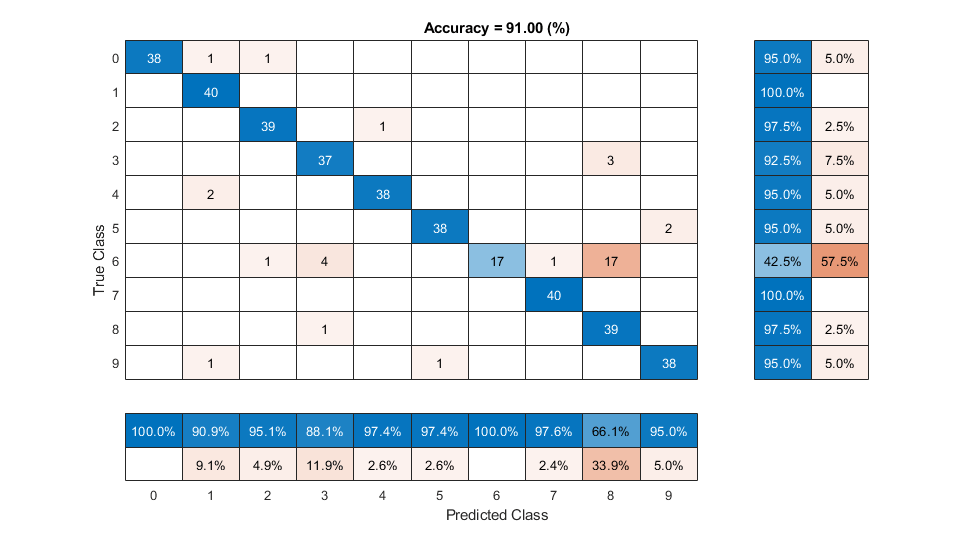
References
[1] Jakobovski. "Jakobovski/Free-Spoken-Digit-Dataset." GitHub, May 30, 2019. https://github.com/Jakobovski/free-spoken-digit-dataset.
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2021a
See Also
trainExtractor | trainClassifier | calibrate | enroll | unenroll | detectionErrorTradeoff | verify | identify | info | addInfoHeader | release | ivectorSystem | speakerRecognition