ivectorSystem
Create i-vector system
Description
i-vectors are compact statistical representations of identity extracted from audio
signals. ivectorSystem creates a trainable i-vector system to extract
i-vectors and perform classification tasks such as speaker recognition, speaker diarization,
and sound classification. You can also determine thresholds for open set tasks and enroll
labels into the system for both open and closed set classification.
Creation
Properties
Object Functions
trainExtractor | Train i-vector extractor |
trainClassifier | Train i-vector classifier |
calibrate | Train i-vector system calibrator |
enroll | Enroll labels |
unenroll | Unenroll labels |
detectionErrorTradeoff | Evaluate binary classification system |
verify | Verify label |
identify | Identify label |
ivector | Extract i-vector |
info | Return training configuration and data info |
addInfoHeader | Add custom information about i-vector system |
release | Allow property values and input characteristics to change |
Examples
Use the Pitch Tracking Database from Graz University of Technology (PTDB-TUG) [1]. The data set consists of 20 English native speakers reading 2342 phonetically rich sentences from the TIMIT corpus. Download and extract the data set.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","ptdb-tug.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) dataset = fullfile(dataFolder,"ptdb-tug");
Create an audioDatastore object that points to the data set. The data set was originally intended for use in pitch-tracking training and evaluation and includes laryngograph readings and baseline pitch decisions. Use only the original audio recordings.
ads = audioDatastore([fullfile(dataset,"SPEECH DATA","FEMALE","MIC"),fullfile(dataset,"SPEECH DATA","MALE","MIC")], ... IncludeSubfolders=true, ... FileExtensions=".wav");
The file names contain the speaker IDs. Decode the file names to set the labels in the audioDatastore object.
ads.Labels = extractBetween(ads.Files,"mic_","_"); countEachLabel(ads)
ans=20×2 table
F01 236
F02 236
F03 236
F04 236
F05 236
F06 236
F07 236
F08 234
F09 236
F10 236
M01 236
M02 236
M03 236
M04 236
⋮
Read an audio file from the data set, listen to it, and plot it.
[audioIn,audioInfo] = read(ads); fs = audioInfo.SampleRate; t = (0:size(audioIn,1)-1)/fs; sound(audioIn,fs) plot(t,audioIn) xlabel("Time (s)") ylabel("Amplitude") axis([0 t(end) -1 1]) title("Sample Utterance from Data Set")
Separate the audioDatastore object into four: one for training, one for enrollment, one to evaluate the detection-error tradeoff, and one for testing. The training set contains 16 speakers. The enrollment, detection-error tradeoff, and test sets contain the other four speakers.
speakersToTest = categorical(["M01","M05","F01","F05"]); adsTrain = subset(ads,~ismember(ads.Labels,speakersToTest)); ads = subset(ads,ismember(ads.Labels,speakersToTest)); [adsEnroll,adsTest,adsDET] = splitEachLabel(ads,3,1);
Display the label distributions of the audioDatastore objects.
countEachLabel(adsTrain)
ans=16×2 table
F02 236
F03 236
F04 236
F06 236
F07 236
F08 234
F09 236
F10 236
M02 236
M03 236
M04 236
M06 236
M07 236
M08 236
countEachLabel(adsEnroll)
ans=4×2 table
F01 3
F05 3
M01 3
M05 3
countEachLabel(adsTest)
ans=4×2 table
F01 1
F05 1
M01 1
M05 1
countEachLabel(adsDET)
ans=4×2 table
F01 232
F05 232
M01 232
M05 232
Create an i-vector system. By default, the i-vector system assumes the input to the system is mono audio signals.
speakerVerification = ivectorSystem(SampleRate=fs)
speakerVerification =
ivectorSystem with properties:
InputType: 'audio'
SampleRate: 48000
DetectSpeech: 1
Verbose: 1
EnrolledLabels: [0×2 table]
To train the extractor of the i-vector system, call trainExtractor. Specify the number of universal background model (UBM) components as 128 and the number of expectation maximization iterations as 5. Specify the total variability space (TVS) rank as 64 and the number of iterations as 3.
trainExtractor(speakerVerification,adsTrain, ... UBMNumComponents=128,UBMNumIterations=5, ... TVSRank=64,TVSNumIterations=3)
Calculating standardization factors ....done. Training universal background model ........done. Training total variability space ......done. i-vector extractor training complete.
To train the classifier of the i-vector system, use trainClassifier. To reduce dimensionality of the i-vectors, specify the number of eigenvectors in the projection matrix as 16. Specify the number of dimensions in the probabilistic linear discriminant analysis (PLDA) model as 16, and the number of iterations as 3.
trainClassifier(speakerVerification,adsTrain,adsTrain.Labels, ... NumEigenvectors=16, ... PLDANumDimensions=16,PLDANumIterations=3)
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model ......done. i-vector classifier training complete.
To calibrate the system so that scores can be interpreted as a measure of confidence in a positive decision, use calibrate.
calibrate(speakerVerification,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
To inspect parameters used previously to train the i-vector system, use info.
info(speakerVerification)
i-vector system input Input feature vector length: 60 Input data type: double trainExtractor Train signals: 3774 UBMNumComponents: 128 UBMNumIterations: 5 TVSRank: 64 TVSNumIterations: 3 trainClassifier Train signals: 3774 Train labels: F02 (236), F03 (236) ... and 14 more NumEigenvectors: 16 PLDANumDimensions: 16 PLDANumIterations: 3 calibrate Calibration signals: 3774 Calibration labels: F02 (236), F03 (236) ... and 14 more
Split the enrollment set.
[adsEnrollPart1,adsEnrollPart2] = splitEachLabel(adsEnroll,1,2);
To enroll speakers in the i-vector system, call enroll.
enroll(speakerVerification,adsEnrollPart1,adsEnrollPart1.Labels)
Extracting i-vectors ...done. Enrolling i-vectors .......done. Enrollment complete.
When you enroll speakers, the read-only EnrolledLabels property is updated with the enrolled labels and corresponding template i-vectors. The table also keeps track of the number of signals used to create the template i-vector. Generally, using more signals results in a better template.
speakerVerification.EnrolledLabels
ans=4×2 table
16×1 double 1
16×1 double 1
16×1 double 1
16×1 double 1
Enroll the second part of the enrollment set and then view the enrolled labels table again. The i-vector templates and the number of samples are updated.
enroll(speakerVerification,adsEnrollPart2,adsEnrollPart2.Labels)
Extracting i-vectors ...done. Enrolling i-vectors .......done. Enrollment complete.
speakerVerification.EnrolledLabels
ans=4×2 table
16×1 double 3
16×1 double 3
16×1 double 3
16×1 double 3
To evaluate the i-vector system and determine a decision threshold for speaker verification, call detectionErrorTradeoff.
[results, eerThreshold] = detectionErrorTradeoff(speakerVerification,adsDET,adsDET.Labels);
Extracting i-vectors ...done. Scoring i-vector pairs ...done. Detection error tradeoff evaluation complete.
The first output from detectionErrorTradeoff is a structure with two fields: CSS and PLDA. Each field contains a table. Each row of the table contains a possible decision threshold for speaker verification tasks, and the corresponding false acceptance rate (FAR) and false rejection rate (FRR). The FAR and FRR are determined using the enrolled speaker labels and the data input to the detectionErrorTradeoff function.
results
results = struct with fields:
PLDA: [1000×3 table]
CSS: [1000×3 table]
results.CSS
ans=1000×3 table
2.3259e-10 1 0
2.3965e-10 0.9996 0
2.4693e-10 0.9993 0
2.5442e-10 0.9993 0
2.6215e-10 0.9993 0
2.7010e-10 0.9993 0
2.7830e-10 0.9993 0
2.8675e-10 0.9993 0
2.9545e-10 0.9993 0
3.0442e-10 0.9993 0
3.1366e-10 0.9993 0
3.2318e-10 0.9993 0
3.3299e-10 0.9993 0
3.4310e-10 0.9993 0
⋮
results.PLDA
ans=1000×3 table
3.2661e-40 1 0
3.6177e-40 0.9996 0
4.0072e-40 0.9996 0
4.4387e-40 0.9996 0
4.9166e-40 0.9996 0
5.4459e-40 0.9996 0
6.0322e-40 0.9996 0
6.6817e-40 0.9996 0
7.4011e-40 0.9996 0
8.1980e-40 0.9996 0
9.0806e-40 0.9996 0
1.0058e-39 0.9996 0
1.1141e-39 0.9996 0
1.2341e-39 0.9996 0
⋮
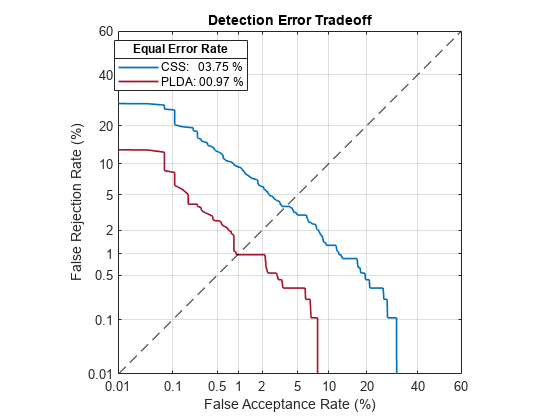
The second output from detectionErrorTradeoff is a structure with two fields: CSS and PLDA. The corresponding value is the decision threshold that results in the equal error rate (when FAR and FRR are equal).
eerThreshold
eerThreshold = struct with fields:
PLDA: 0.0398
CSS: 0.9369
The first time you call detectionErrorTradeoff, you must provide data and corresponding labels to evaluate. Subsequently, you can get the same information, or a different analysis using the same underlying data, by calling detectionErrorTradeoff without data and labels.
Call detectionErrorTradeoff a second time with no data arguments or output arguments to visualize the detection-error tradeoff.
detectionErrorTradeoff(speakerVerification)
Call detectionErrorTradeoff again. This time, visualize only the detection-error tradeoff for the PLDA scorer.
detectionErrorTradeoff(speakerVerification,Scorer="plda")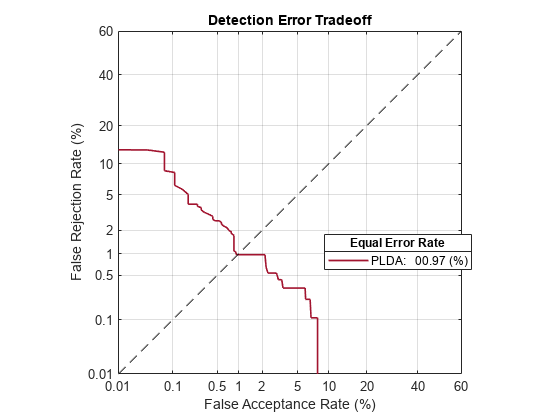
Depending on your application, you may want to use a threshold that weights the error cost of a false acceptance higher or lower than the error cost of a false rejection. You may also be using data that is not representative of the prior probability of the speaker being present. You can use the minDCF parameter to specify custom costs and prior probability. Call detectionErrorTradeoff again, this time specify the cost of a false rejection as 1, the cost of a false acceptance as 2, and the prior probability that a speaker is present as 0.1.
costFR = 1;
costFA = 2;
priorProb = 0.1;
detectionErrorTradeoff(speakerVerification,Scorer="plda",minDCF=[costFR,costFA,priorProb])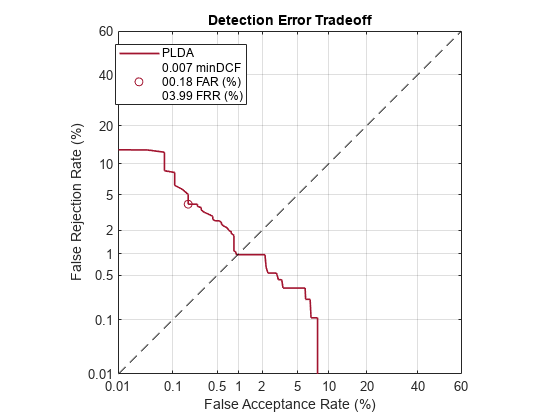
Call detectionErrorTradeoff again. This time, get the minDCF threshold for the PLDA scorer and the parameters of the detection cost function.
[~,minDCFThreshold] = detectionErrorTradeoff(speakerVerification,Scorer="plda",minDCF=[costFR,costFA,priorProb])minDCFThreshold = 0.4709
Test Speaker Verification System
Read a signal from the test set.
adsTest = shuffle(adsTest); [audioIn,audioInfo] = read(adsTest); knownSpeakerID = audioInfo.Label
knownSpeakerID = 1×1 cell array
{'F01'}
To perform speaker verification, call verify with the audio signal and specify the speaker ID, a scorer, and a threshold for the scorer. The verify function returns a logical value indicating whether a speaker identity is accepted or rejected, and a score indicating the similarity of the input audio and the template i-vector corresponding to the enrolled label.
[tf,score] = verify(speakerVerification,audioIn,knownSpeakerID,"plda",eerThreshold.PLDA); if tf fprintf('Success!\nSpeaker accepted.\nSimilarity score = %0.2f\n\n',score) else fprinf('Failure!\nSpeaker rejected.\nSimilarity score = %0.2f\n\n',score) end
Success! Speaker accepted. Similarity score = 1.00
Call speaker verification again. This time, specify an incorrect speaker ID.
possibleSpeakers = speakerVerification.EnrolledLabels.Properties.RowNames; imposterIdx = find(~ismember(possibleSpeakers,knownSpeakerID)); imposter = possibleSpeakers(imposterIdx(randperm(numel(imposterIdx),1)))
imposter = 1×1 cell array
{'M05'}
[tf,score] = verify(speakerVerification,audioIn,imposter,"plda",eerThreshold.PLDA); if tf fprintf('Failure!\nSpeaker accepted.\nSimilarity score = %0.2f\n\n',score) else fprintf('Success!\nSpeaker rejected.\nSimilarity score = %0.2f\n\n',score) end
Success! Speaker rejected. Similarity score = 0.00
References
[1] Signal Processing and Speech Communication Laboratory. https://www.spsc.tugraz.at/databases-and-tools/ptdb-tug-pitch-tracking-database-from-graz-university-of-technology.html. Accessed 12 Dec. 2019.
This example uses a 1.36 GB subset of the Common Voice data set from Mozilla [1]. The data set contains 48 kHz recordings of subjects speaking short sentences.
Download the data set if it doesn't already exist and unzip it into tempdir.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","commonvoice.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder);
Ingest the train set using audioDatastore and, to speed up this example, keep only 20% of each of the speaker files.
trainTable = readtable(dataFolder + fullfile("commonvoice","train","train.tsv"),FileType="text",Delimiter="tab"); adsTrain = audioDatastore(append(fullfile(dataFolder,"commonvoice","train","clips",filesep),trainTable.path,".wav")); idx = splitlabels(trainTable.client_id,0.2); adsTrain = subset(adsTrain,idx{1}); trainLabels = trainTable.client_id(idx{1});
Ingest the validation set using audioDatastore.
valTable = readtable(dataFolder + fullfile("commonvoice","validation","validation.tsv"),FileType="text",Delimiter="tab"); valLabels = valTable.client_id; adsVal = audioDatastore(append(fullfile(dataFolder,"commonvoice","validation","clips",filesep),valTable.path,".wav"));
Split the validation data set into enroll and test sets. Use two utterances for enrollment and the remaining for the test set. Also, exclude any speakers with less than 5 utterances. Generally, the more utterances you use for enrollment, the better the performance of the system. However, most practical applications are limited to a small set of enrollment utterances.
labelCounts = countlabels(valLabels);
labelsToExclude = labelCounts.Label(labelCounts.Count<5);
idxs = splitlabels(valLabels,2,Exclude=labelsToExclude);
adsEnroll = subset(adsVal,idxs{1});
enrollLabels = valLabels(idxs{1});
adsTest = subset(adsVal,idxs{2});
testLabels = valLabels(idxs{2});Create an i-vector system that accepts feature input.
fs = 48e3;
iv = ivectorSystem(SampleRate=fs,InputType="features");Create an audioFeatureExtractor object to extract the gammatone cepstral coefficients (GTCC), the delta GTCC, the delta-delta GTCC, and the pitch from 50 ms periodic Hann windows with 45 ms overlap.
afe = audioFeatureExtractor(... SampleRate=fs, ... Window=hann(round(0.05*fs),"periodic"), ... OverlapLength=round(0.045*fs), ... gtcc=true,gtccDelta=true,gtccDeltaDelta=true,pitch=true);
Extract features from the train and enroll datastores.
xTrain = extract(afe,adsTrain); xEnroll = extract(afe,adsEnroll);
Train both the extractor and classifier using the training set.
trainExtractor(iv,xTrain, ... UBMNumComponents=64, ... UBMNumIterations=5, ... TVSRank=32, ... TVSNumIterations=3);
Calculating standardization factors .....done. Training universal background model ........done. Training total variability space ......done. i-vector extractor training complete.
trainClassifier(iv,xTrain,trainLabels, ... NumEigenvectors=16, ... ... PLDANumDimensions=16, ... PLDANumIterations=5);
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model ........done. i-vector classifier training complete.
To calibrate the system so that scores can be interpreted as a measure of confidence in a positive decision, use calibrate.
calibrate(iv,xTrain,trainLabels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
Enroll the speakers from the enrollment set.
enroll(iv,xEnroll,enrollLabels)
Extracting i-vectors ...done. Enrolling i-vectors ...................done. Enrollment complete.
Evaluate the file-level prediction accuracy on the test set.
numCorrect = 0; reset(adsTest) for index = 1:numel(adsTest.Files) features = extract(afe,read(adsTest)); results = identify(iv,features); trueLabel = testLabels(index); predictedLabel = results.Label(1); isPredictionCorrect = trueLabel==predictedLabel; numCorrect = numCorrect + isPredictionCorrect; end display("File Accuracy: " + round(100*numCorrect/numel(adsTest.Files),2) + " (%)")
"File Accuracy: 97.92 (%)"
References
Download and unzip the environment sound classification data set. This data set consists of recordings labeled as one of 10 different audio sound classes (ESC-10).
loc = matlab.internal.examples.downloadSupportFile("audio","ESC-10.zip"); unzip(loc,pwd)
Create an audioDatastore object to manage the data and split it into training and validation sets. Call countEachLabel to display the distribution of sound classes and the number of unique labels.
ads = audioDatastore(pwd,IncludeSubfolders=true,LabelSource="foldernames");
countEachLabel(ads)ans=10×2 table
chainsaw 40
clock_tick 40
crackling_fire 40
crying_baby 40
dog 40
helicopter 40
rain 40
rooster 38
sea_waves 40
sneezing 40
Listen to one of the files.
[audioIn,audioInfo] = read(ads); fs = audioInfo.SampleRate; sound(audioIn,fs) audioInfo.Label
ans = categorical
chainsaw
Split the datastore into training and test sets.
[adsTrain,adsTest] = splitEachLabel(ads,0.8);
Create an audioFeatureExtractor to extract all possible features from the audio.
afe = audioFeatureExtractor(SampleRate=fs, ... Window=hamming(round(0.03*fs),"periodic"), ... OverlapLength=round(0.02*fs)); params = info(afe,"all"); params = structfun(@(x)true,params,UniformOutput=false); set(afe,params); afe
afe =
audioFeatureExtractor with properties:
Properties
Window: [1323×1 double]
OverlapLength: 882
SampleRate: 44100
FFTLength: []
SpectralDescriptorInput: 'linearSpectrum'
FeatureVectorLength: 862
Enabled Features
linearSpectrum, melSpectrum, barkSpectrum, erbSpectrum, mfcc, mfccDelta
mfccDeltaDelta, gtcc, gtccDelta, gtccDeltaDelta, spectralCentroid, spectralCrest
spectralDecrease, spectralEntropy, spectralFlatness, spectralFlux, spectralKurtosis, spectralRolloffPoint
spectralSkewness, spectralSlope, spectralSpread, pitch, harmonicRatio, zerocrossrate
shortTimeEnergy
Disabled Features
none
To extract a feature, set the corresponding property to true.
For example, obj.mfcc = true, adds mfcc to the list of enabled features.
Create two directories in your current folder: train and test. Extract features from the training and the test data sets and write the features as MAT files to the respective directories. Pre-extracting features can save time when you want to evaluate different feature combinations or training configurations.
if ~isdir("train") mkdir("train") mkdir("test") outputType = ".mat"; writeall(adsTrain,"train",WriteFcn=@(x,y,z)writeFeatures(x,y,z,afe)) writeall(adsTest,"test",WriteFcn=@(x,y,z)writeFeatures(x,y,z,afe)) end
Create signal datastores to point to the audio features.
sdsTrain = signalDatastore("train",IncludeSubfolders=true); sdsTest = signalDatastore("test",IncludeSubfolders=true);
Create label arrays that are in the same order as the signalDatastore files.
labelsTrain = categorical(extractBetween(sdsTrain.Files,"ESC-10"+filesep,filesep)); labelsTest = categorical(extractBetween(sdsTest.Files,"ESC-10"+filesep,filesep));
Create a transform datastore from the signal datastores to isolate and use only the desired features. You can use the output from info on the audioFeatureExtractor to map your chosen features to the index in the features matrix. You can experiment with the example by choosing different features.
featureIndices = info(afe)
featureIndices = struct with fields:
linearSpectrum: [1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 … ]
melSpectrum: [663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694]
barkSpectrum: [695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726]
erbSpectrum: [727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769]
mfcc: [770 771 772 773 774 775 776 777 778 779 780 781 782]
mfccDelta: [783 784 785 786 787 788 789 790 791 792 793 794 795]
mfccDeltaDelta: [796 797 798 799 800 801 802 803 804 805 806 807 808]
gtcc: [809 810 811 812 813 814 815 816 817 818 819 820 821]
gtccDelta: [822 823 824 825 826 827 828 829 830 831 832 833 834]
gtccDeltaDelta: [835 836 837 838 839 840 841 842 843 844 845 846 847]
spectralCentroid: 848
spectralCrest: 849
spectralDecrease: 850
spectralEntropy: 851
spectralFlatness: 852
spectralFlux: 853
spectralKurtosis: 854
spectralRolloffPoint: 855
spectralSkewness: 856
spectralSlope: 857
spectralSpread: 858
pitch: 859
harmonicRatio: 860
zerocrossrate: 861
shortTimeEnergy: 862
idxToUse = [... featureIndices.harmonicRatio ... ,featureIndices.spectralRolloffPoint ... ,featureIndices.spectralFlux ... ,featureIndices.spectralSlope ... ]; tdsTrain = transform(sdsTrain,@(x)x(:,idxToUse)); tdsTest = transform(sdsTest,@(x)x(:,idxToUse));
Create an i-vector system that accepts feature input.
soundClassifier = ivectorSystem(InputType="features");Train the extractor and classifier using the training set.
trainExtractor(soundClassifier,tdsTrain,UBMNumComponents=128,TVSRank=64);
Calculating standardization factors ....done. Training universal background model .....done. Training total variability space ......done. i-vector extractor training complete.
trainClassifier(soundClassifier,tdsTrain,labelsTrain,NumEigenvectors=32,PLDANumIterations=0)
Extracting i-vectors ...done. Training projection matrix .....done. i-vector classifier training complete.
Enroll the labels from the training set to create i-vector templates for each of the environmental sounds.
enroll(soundClassifier,tdsTrain,labelsTrain)
Extracting i-vectors ...done. Enrolling i-vectors .............done. Enrollment complete.
Calibrate the i-vector system.
calibrate(soundClassifier,tdsTrain,labelsTrain)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibration complete.
Use the identify function on the test set to return the system's inferred label.
inferredLabels = labelsTest; inferredLabels(:) = inferredLabels(1); for ii = 1:numel(labelsTest) features = read(tdsTest); tableOut = identify(soundClassifier,features,"css",NumCandidates=1); inferredLabels(ii) = tableOut.Label(1); end
Create a confusion matrix to visualize performance on the test set.
uniqueLabels = unique(labelsTest); cm = zeros(numel(uniqueLabels),numel(uniqueLabels)); for ii = 1:numel(uniqueLabels) for jj = 1:numel(uniqueLabels) cm(ii,jj) = sum((labelsTest==uniqueLabels(ii)) & (inferredLabels==uniqueLabels(jj))); end end labelStrings = replace(string(uniqueLabels),"_"," "); heatmap(labelStrings,labelStrings,cm) colorbar off ylabel("True Labels") xlabel("Predicted Labels") accuracy = mean(inferredLabels==labelsTest); title(sprintf("Accuracy = %0.2f %%",accuracy*100))
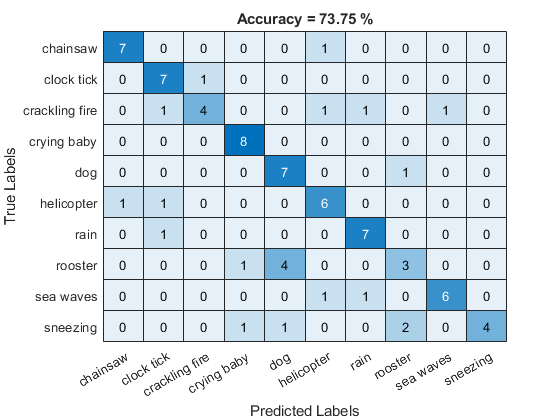
Release the i-vector system.
release(soundClassifier)
Supporting Functions
function writeFeatures(audioIn,info,~,afe) % Convert to single-precision audioIn = single(audioIn); % Extract features features = extract(afe,audioIn); % Replace the file extension of the suggested output name with MAT. filename = strrep(info.SuggestedOutputName,".wav",".mat"); % Save the MFCC coefficients to the MAT file. save(filename,"features") end
Download and unzip the air compressor data set [1]. This data set consists of recordings from air compressors in a healthy state or one of seven faulty states.
loc = matlab.internal.examples.downloadSupportFile("audio", ... "AirCompressorDataset/AirCompressorDataset.zip"); unzip(loc,pwd)
Create an audioDatastore object to manage the data and split it into training and validation sets.
ads = audioDatastore(pwd,IncludeSubfolders=true,LabelSource="foldernames");
[adsTrain,adsTest] = splitEachLabel(ads,0.8,0.2);Read an audio file from the datastore and save the sample rate. Listen to the audio signal and plot the signal in the time domain.
[x,fileInfo] = read(adsTrain); fs = fileInfo.SampleRate; sound(x,fs) t = (0:size(x,1)-1)/fs; plot(t,x) xlabel("Time (s)") title("State = " + string(fileInfo.Label)) axis tight
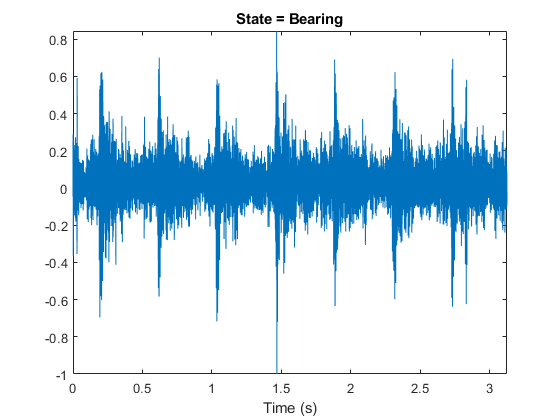
Create an i-vector system with DetectSpeech set to false. Turn off the verbose behavior.
faultRecognizer = ivectorSystem(SampleRate=fs,DetectSpeech=false, ...
Verbose=false)faultRecognizer =
ivectorSystem with properties:
InputType: 'audio'
SampleRate: 16000
DetectSpeech: 0
Verbose: 0
EnrolledLabels: [0×2 table]
Train the i-vector extractor and the i-vector classifier using the training datastore.
trainExtractor(faultRecognizer,adsTrain, ... UBMNumComponents=80, ... UBMNumIterations=3, ... ... TVSRank=40, ... TVSNumIterations=3) trainClassifier(faultRecognizer,adsTrain,adsTrain.Labels, ... NumEigenvectors=7, ... ... PLDANumDimensions=32, ... PLDANumIterations=5)
Calibrate the scores output by faultRecognizer so they can be interpreted as a measure of confidence in a positive decision. Turn the verbose behavior back on. Enroll all of the labels from the training set.
calibrate(faultRecognizer,adsTrain,adsTrain.Labels) faultRecognizer.Verbose = true; enroll(faultRecognizer,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Enrolling i-vectors ...........done. Enrollment complete.
Use the read-only property EnrolledLabels to view the enrolled labels and the corresponding i-vector templates.
faultRecognizer.EnrolledLabels
ans=8×2 table
[-1.7754;2.7459;1.8946;-0.9161;-1.2876;-3.1496;-1.2082] 180
[-0.8997;2.7728;1.6466;-0.5736;-0.6705;-1.7095;1.6218] 180
[2.6075;-0.3423;0.7196;-1.7987;0.0418;-2.0834;-0.3119] 180
[-3.0463;1.7082;-0.3501;-3.4135;-1.2038;-2.3229;0.3877] 180
[-2.3203;-0.5169;-0.1180;-0.1466;-2.5011;-1.5579;-0.1835] 180
[-4.3502;0.7117;0.6711;-0.8584;1.2934;-1.5556;-0.4946] 180
[-0.8910;2.8137;1.3467;-2.0241;-1.2625;-0.2699;-0.9879] 180
[-2.9266;-0.8552;3.3690;-2.2964;-1.2539;-1.7204;0.1214] 180
Use the identify function with the PLDA scorer to predict the condition of machines in the test set. The identify function returns a table of possible labels sorted in descending order of confidence.
[audioIn,audioInfo] = read(adsTest); trueLabel = audioInfo.Label
trueLabel = categorical
Bearing
predictedLabels = identify(faultRecognizer,audioIn,"plda")predictedLabels=8×2 table
Bearing 1
Flywheel 0
Piston 0
LIV 0
NRV 0
Riderbelt 0
LOV 0
Healthy 0
By default, the identify function returns all possible candidate labels and their corresponding scores. Use NumCandidates to reduce the number of candidates returned.
results = identify(faultRecognizer,audioIn,"plda",NumCandidates=3)results=3×2 table
Bearing 1
Flywheel 0
Piston 0
References
[1] Verma, Nishchal K., et al. “Intelligent Condition Based Monitoring Using Acoustic Signals for Air Compressors.” IEEE Transactions on Reliability, vol. 65, no. 1, Mar. 2016, pp. 291–309. DOI.org (Crossref), doi:10.1109/TR.2015.2459684.
Download the Berlin Database of Emotional Speech [1]. The database contains 535 utterances spoken by 10 actors intended to convey one of the following emotions: anger, boredom, disgust, anxiety/fear, happiness, sadness, or neutral. The emotions are text independent.
url = "http://emodb.bilderbar.info/download/download.zip"; downloadFolder = tempdir; datasetFolder = fullfile(downloadFolder,"Emo-DB"); if ~exist(datasetFolder,"dir") disp("Downloading Emo-DB (40.5 MB) ...") unzip(url,datasetFolder) end
Create an audioDatastore that points to the audio files.
ads = audioDatastore(fullfile(datasetFolder,"wav"));The file names are codes indicating the speaker id, text spoken, emotion, and version. The website contains a key for interpreting the code and additional information about the speakers such as gender and age. Create a table with the variables Speaker and Emotion. Decode the file names into the table.
filepaths = ads.Files; emotionCodes = cellfun(@(x)x(end-5),filepaths,"UniformOutput",false); emotions = replace(emotionCodes,{'W','L','E','A','F','T','N'}, ... {'Anger','Boredom','Disgust','Anxiety','Happiness','Sadness','Neutral'}); speakerCodes = cellfun(@(x)x(end-10:end-9),filepaths,"UniformOutput",false); labelTable = table(categorical(speakerCodes),categorical(emotions),VariableNames=["Speaker","Emotion"]); summary(labelTable)
Variables:
Speaker: 535×1 categorical
Values:
03 49
08 58
09 43
10 38
11 55
12 35
13 61
14 69
15 56
16 71
Emotion: 535×1 categorical
Values:
Anger 127
Anxiety 69
Boredom 81
Disgust 46
Happiness 71
Neutral 79
Sadness 62
labelTable is in the same order as the files in audioDatastore. Set the Labels property of the audioDatastore to labelTable.
ads.Labels = labelTable;
Read a signal from the datastore and listen to it. Display the speaker ID and emotion of the audio signal.
[audioIn,audioInfo] = read(ads); fs = audioInfo.SampleRate; sound(audioIn,fs) audioInfo.Label
ans=1×2 table
03 Happiness
Split the datastore into a training set and a test set. Assign two speakers to the test set and the remaining to the training set.
testSpeakerIdx = ads.Labels.Speaker=="12" | ads.Labels.Speaker=="13"; adsTrain = subset(ads,~testSpeakerIdx); adsTest = subset(ads,testSpeakerIdx);
Read all the training and testing audio data into cell arrays. If your data can fit in memory, training is usually faster to input cell arrays to an i-vector system rather than datastores.
trainSet = readall(adsTrain); trainLabels = adsTrain.Labels.Emotion; testSet = readall(adsTest); testLabels = adsTest.Labels.Emotion;
Create an i-vector system that does not apply speech detection. When DetectSpeech is set to true (the default), only regions of detected speech are used to train the i-vector system. When DetectSpeech is set to false, the entire input audio is used to train the i-vector system. The usefulness of applying speech detection depends on the data input to the system.
emotionRecognizer = ivectorSystem(SampleRate=fs,DetectSpeech= false)
false)emotionRecognizer =
ivectorSystem with properties:
InputType: 'audio'
SampleRate: 16000
DetectSpeech: 0
Verbose: 1
EnrolledLabels: [0×2 table]
Call trainExtractor using the training set.
rng default trainExtractor(emotionRecognizer,trainSet, ... UBMNumComponents =256, ... UBMNumIterations =
5, ... ... TVSRank =
128, ... TVSNumIterations =
5);
Calculating standardization factors .....done. Training universal background model ........done. Training total variability space ........done. i-vector extractor training complete.
Copy the emotion recognition system for use later in the example.
sentimentRecognizer = copy(emotionRecognizer);
Call trainClassifier using the training set.
rng default trainClassifier(emotionRecognizer,trainSet,trainLabels, ... NumEigenvectors =32, ... ... PLDANumDimensions =
16, ... PLDANumIterations =
10);
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model .............done. i-vector classifier training complete.
Call calibrate using the training set. In practice, the calibration set should be different than the training set.
calibrate(emotionRecognizer,trainSet,trainLabels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
Enroll the training labels into the i-vector system.
enroll(emotionRecognizer,trainSet,trainLabels)
Extracting i-vectors ...done. Enrolling i-vectors ..........done. Enrollment complete.
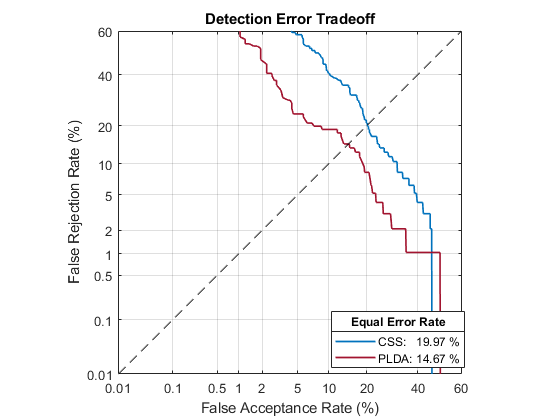
You can use detectionErrorTradeoff as a quick sanity check on the performance of a multilabel closed-set classification system. However, detectionErrorTradeoff provides information more suitable to open-set binary classification problems, for example, speaker verification tasks.
detectionErrorTradeoff(emotionRecognizer,testSet,testLabels)
Extracting i-vectors ...done. Scoring i-vector pairs ...done. Detection error tradeoff evaluation complete.
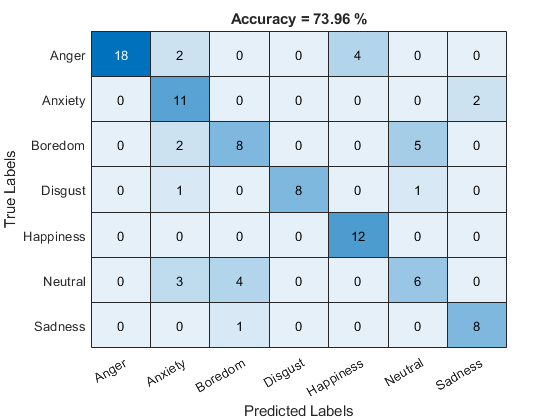
For a more detailed view of the i-vector system's performance in a multilabel closed set application, you can use the identify function and create a confusion matrix. The confusion matrix enables you to identify which emotions are misidentified and what they are misidentified as. Use the supporting function plotConfusion to display the results.
trueLabels = testLabels; predictedLabels = trueLabels; scorer ="plda"; for ii = 1:numel(testSet) tableOut = identify(emotionRecognizer,testSet{ii},scorer); predictedLabels(ii) = tableOut.Label(1); end plotConfusion(trueLabels,predictedLabels)
Call info to inspect how emotionRecognizer was trained and evaluated.
info(emotionRecognizer)
i-vector system input Input feature vector length: 60 Input data type: double trainExtractor Train signals: 439 UBMNumComponents: 256 UBMNumIterations: 5 TVSRank: 128 TVSNumIterations: 5 trainClassifier Train signals: 439 Train labels: Anger (103), Anxiety (56) ... and 5 more NumEigenvectors: 32 PLDANumDimensions: 16 PLDANumIterations: 10 calibrate Calibration signals: 439 Calibration labels: Anger (103), Anxiety (56) ... and 5 more detectionErrorTradeoff Evaluation signals: 96 Evaluation labels: Anger (24), Anxiety (13) ... and 5 more
Next, modify the i-vector system to recognize emotions as positive, neutral, or negative. Update the labels to only include the categories negative, positive, and categorical.
trainLabelsSentiment = trainLabels; trainLabelsSentiment(ismember(trainLabels,categorical(["Anger","Anxiety","Boredom","Sadness","Disgust"]))) = categorical("Negative"); trainLabelsSentiment(ismember(trainLabels,categorical("Happiness"))) = categorical("Positive"); trainLabelsSentiment = removecats(trainLabelsSentiment); testLabelsSentiment = testLabels; testLabelsSentiment(ismember(testLabels,categorical(["Anger","Anxiety","Boredom","Sadness","Disgust"]))) = categorical("Negative"); testLabelsSentiment(ismember(testLabels,categorical("Happiness"))) = categorical("Positive"); testLabelsSentiment = removecats(testLabelsSentiment);
Train the i-vector system classifier using the updated labels. You do not need to retrain the extractor. Recalibrate the system.
rng default trainClassifier(sentimentRecognizer,trainSet,trainLabelsSentiment, ... NumEigenvectors =64, ... ... PLDANumDimensions =
32, ... PLDANumIterations =
10);
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model .............done. i-vector classifier training complete.
calibrate(sentimentRecognizer,trainSet,trainLabels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
Enroll the training labels into the system and then plot the confusion matrix for the test set.
enroll(sentimentRecognizer,trainSet,trainLabelsSentiment)
Extracting i-vectors ...done. Enrolling i-vectors ......done. Enrollment complete.
trueLabels = testLabelsSentiment; predictedLabels = trueLabels; scorer ="plda"; for ii = 1:numel(testSet) tableOut = identify(sentimentRecognizer,testSet{ii},scorer); predictedLabels(ii) = tableOut.Label(1); end plotConfusion(trueLabels,predictedLabels)
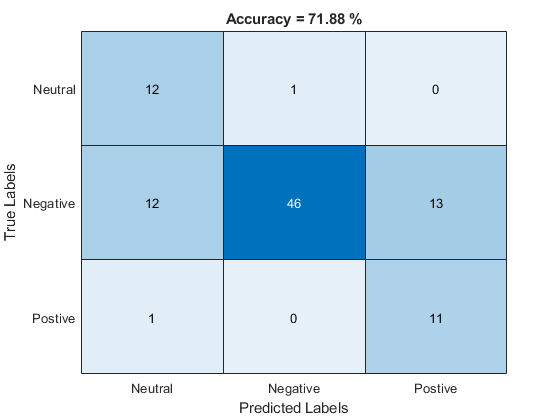
An i-vector system does not require the labels used to train the classifier to be equal to the enrolled labels.
Unenroll the sentiment labels from the system and then enroll the original emotion categories in the system. Analyze the system's classification performance.
unenroll(sentimentRecognizer) enroll(sentimentRecognizer,trainSet,trainLabels)
Extracting i-vectors ...done. Enrolling i-vectors ..........done. Enrollment complete.
trueLabels = testLabels; predictedLabels = trueLabels; scorer ="plda"; for ii = 1:numel(testSet) tableOut = identify(sentimentRecognizer,testSet{ii},scorer); predictedLabels(ii) = tableOut.Label(1); end plotConfusion(trueLabels,predictedLabels)
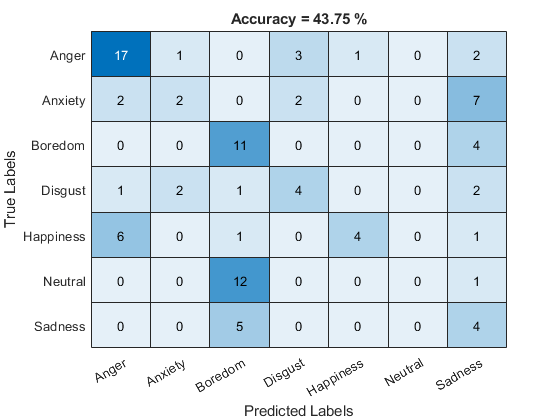
Supporting Functions
function plotConfusion(trueLabels,predictedLabels) uniqueLabels = unique(trueLabels); cm = zeros(numel(uniqueLabels),numel(uniqueLabels)); for ii = 1:numel(uniqueLabels) for jj = 1:numel(uniqueLabels) cm(ii,jj) = sum((trueLabels==uniqueLabels(ii)) & (predictedLabels==uniqueLabels(jj))); end end heatmap(uniqueLabels,uniqueLabels,cm) colorbar off ylabel('True Labels') xlabel('Predicted Labels') accuracy = mean(trueLabels==predictedLabels); title(sprintf("Accuracy = %0.2f %%",accuracy*100)) end
References
[1] Burkhardt, F., A. Paeschke, M. Rolfes, W.F. Sendlmeier, and B. Weiss, "A Database of German Emotional Speech." In Proceedings Interspeech 2005. Lisbon, Portugal: International Speech Communication Association, 2005.
An i-vector system consists of a trainable front end that learns how to extract i-vectors based on unlabeled data, and a trainable backend that learns how to classify i-vectors based on labeled data. In this example, you apply an i-vector system to the task of word recognition. First, evaluate the accuracy of the i-vector system using the classifiers included in a traditional i-vector system: probabilistic linear discriminant analysis (PLDA) and cosine similarity scoring (CSS). Next, evaluate the accuracy of the system if you replace the classifier with bidirectional long short-term memory (BiLSTM) network or a K-nearest neighbors classifier.
Create Training and Validation Sets
Download the Free Spoken Digit Dataset (FSDD) [1]. FSDD consists of short audio files with spoken digits (0-9).
loc = matlab.internal.examples.downloadSupportFile("audio","FSDD.zip"); unzip(loc,pwd)
Create an audioDatastore to point to the recordings. Get the sample rate of the data set.
ads = audioDatastore(pwd,IncludeSubfolders=true); [~,adsInfo] = read(ads); fs = adsInfo.SampleRate;
The first element of the file names is the digit spoken in the file. Get the first element of the file names, convert them to categorical, and then set the Labels property of the audioDatastore.
[~,filenames] = cellfun(@(x)fileparts(x),ads.Files,UniformOutput=false); ads.Labels = categorical(string(cellfun(@(x)x(1),filenames)));
To split the datastore into a development set and a validation set, use splitEachLabel. Allocate 80% of the data for development and the remaining 20% for validation.
[adsTrain,adsValidation] = splitEachLabel(ads,0.8);
Evaluate Traditional i-vector Backend Performance
Create an i-vector system that expects audio input at a sample rate of 8 kHz and does not perform speech detection.
wordRecognizer = ivectorSystem(DetectSpeech=false,SampleRate=fs)
wordRecognizer =
ivectorSystem with properties:
InputType: 'audio'
SampleRate: 8000
DetectSpeech: 0
Verbose: 1
EnrolledLabels: [0×2 table]
Train the i-vector extractor using the data in the training set.
trainExtractor(wordRecognizer,adsTrain, ... UBMNumComponents=64, ... UBMNumIterations=5, ... ... TVSRank=32, ... TVSNumIterations=5);
Calculating standardization factors ....done. Training universal background model ........done. Training total variability space ........done. i-vector extractor training complete.
Train the i-vector classifier using the data in the training data set and the corresponding labels.
trainClassifier(wordRecognizer,adsTrain,adsTrain.Labels, ... NumEigenvectors=10, ... ... PLDANumDimensions=10, ... PLDANumIterations=5);
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model ........done. i-vector classifier training complete.
Calibrate the scores output by wordRecognizer so they can be interpreted as a measure of confidence in a positive decision. Enroll labels into the system using the entire training set.
calibrate(wordRecognizer,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
enroll(wordRecognizer,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Enrolling i-vectors .............done. Enrollment complete.
In a loop, read audio from the validation datastore, identify the most-likely word present according to the specified scorer, and save the prediction for analysis.
trueLabels = adsValidation.Labels; predictedLabels = trueLabels; reset(adsValidation) scorer ="plda"; for ii = 1:numel(trueLabels) audioIn = read(adsValidation); to = identify(wordRecognizer,audioIn,scorer); predictedLabels(ii) = to.Label(1); end
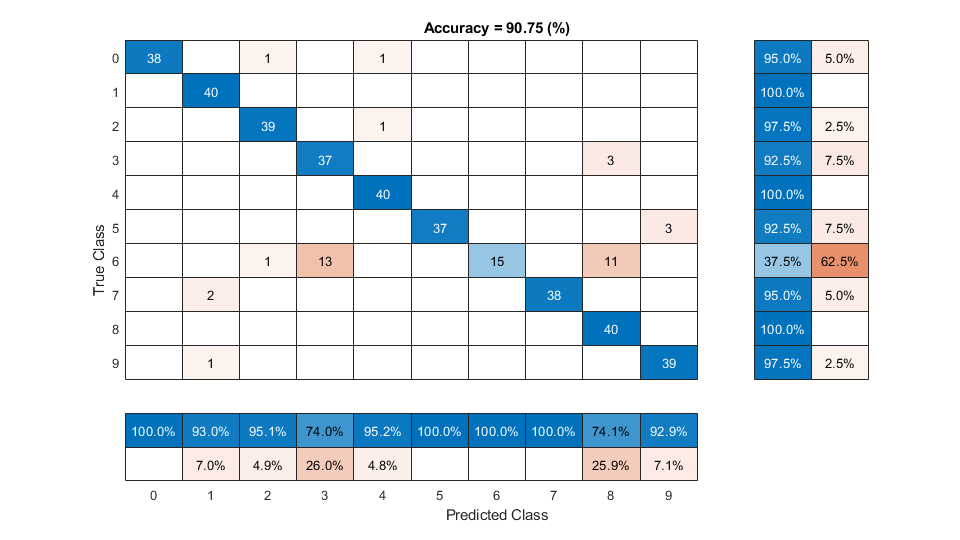
Display a confusion chart of the i-vector system's performance on the validation set.
figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) confusionchart(trueLabels,predictedLabels, ... ColumnSummary="column-normalized", ... RowSummary="row-normalized", ... Title=sprintf('Accuracy = %0.2f (%%)',100*mean(predictedLabels==trueLabels)))
Evaluate Deep Learning Backend Performance
Next, train a fully-connected network using i-vectors as input.
ivectorsTrain = (ivector(wordRecognizer,adsTrain))'; ivectorsValidation = (ivector(wordRecognizer,adsValidation))';
Define a fully connected network.
layers = [ ... featureInputLayer(size(ivectorsTrain,2),Normalization="none") fullyConnectedLayer(128) dropoutLayer(0.4) fullyConnectedLayer(256) dropoutLayer(0.4) fullyConnectedLayer(256) dropoutLayer(0.4) fullyConnectedLayer(128) dropoutLayer(0.4) fullyConnectedLayer(numel(unique(adsTrain.Labels))) softmaxLayer classificationLayer];
Define training parameters.
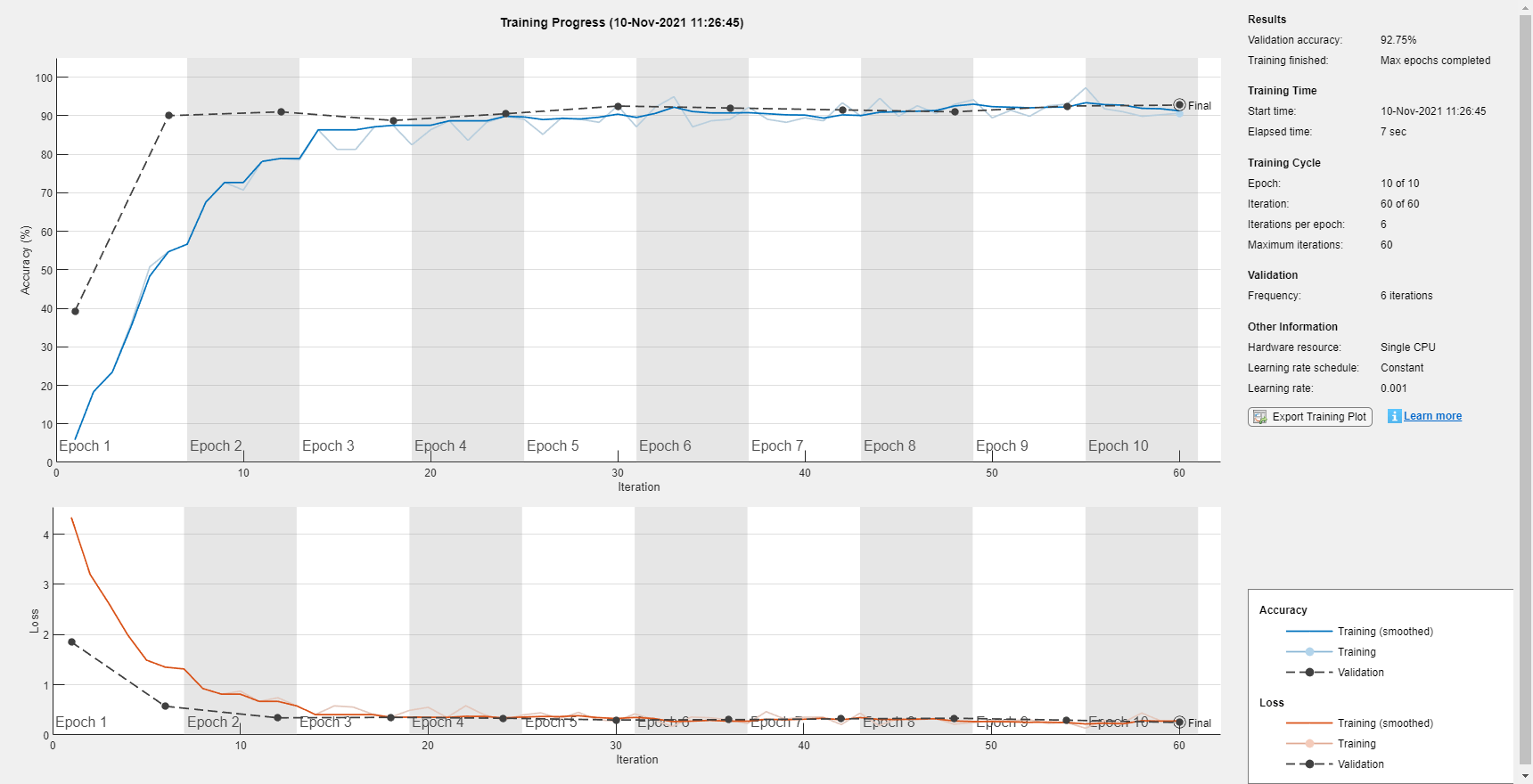
miniBatchSize = 256; validationFrequency = floor(numel(adsTrain.Labels)/miniBatchSize); options = trainingOptions("adam", ... MaxEpochs=10, ... MiniBatchSize=miniBatchSize, ... Plots="training-progress", ... Verbose=false, ... Shuffle="every-epoch", ... ValidationData={ivectorsValidation,adsValidation.Labels}, ... ValidationFrequency=validationFrequency);
Train the network.
net = trainNetwork(ivectorsTrain,adsTrain.Labels,layers,options);
Evaluate the performance of the deep learning backend using a confusion chart.
predictedLabels = classify(net,ivectorsValidation); trueLabels = adsValidation.Labels; figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) confusionchart(trueLabels,predictedLabels, ... ColumnSummary="column-normalized", ... RowSummary="row-normalized", ... Title=sprintf('Accuracy = %0.2f (%%)',100*mean(predictedLabels==trueLabels)))
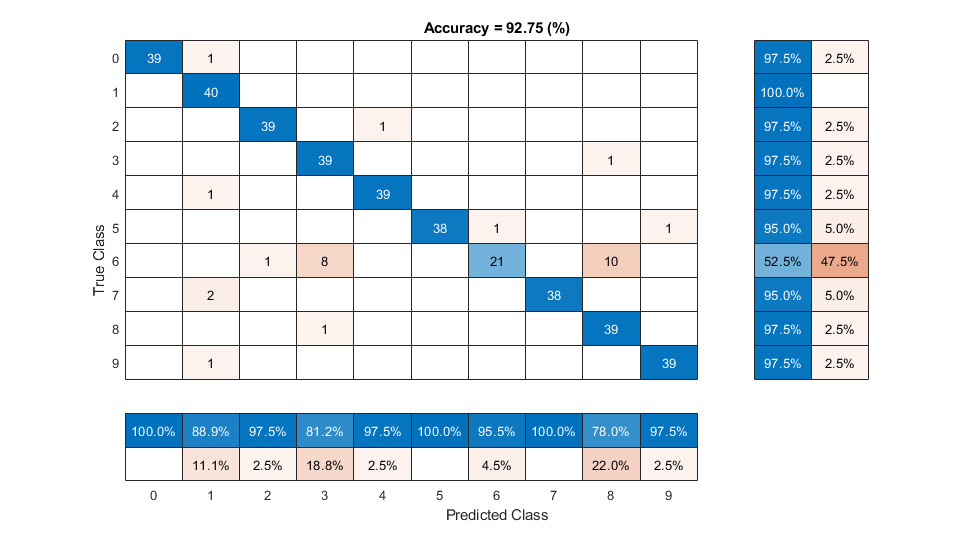
Evaluate KNN Backend Performance
Train and evaluate i-vectors with a k-nearest neighbor (KNN) backend.
Use fitcknn to train a KNN model.
classificationKNN = fitcknn(... ivectorsTrain, ... adsTrain.Labels, ... Distance="Euclidean", ... Exponent=[], ... NumNeighbors=10, ... DistanceWeight="SquaredInverse", ... Standardize=true, ... ClassNames=unique(adsTrain.Labels));
Evaluate the KNN backend.
predictedLabels = predict(classificationKNN,ivectorsValidation); trueLabels = adsValidation.Labels; figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) confusionchart(trueLabels,predictedLabels, ... ColumnSummary="column-normalized", ... RowSummary="row-normalized", ... Title=sprintf('Accuracy = %0.2f (%%)',100*mean(predictedLabels==trueLabels)))
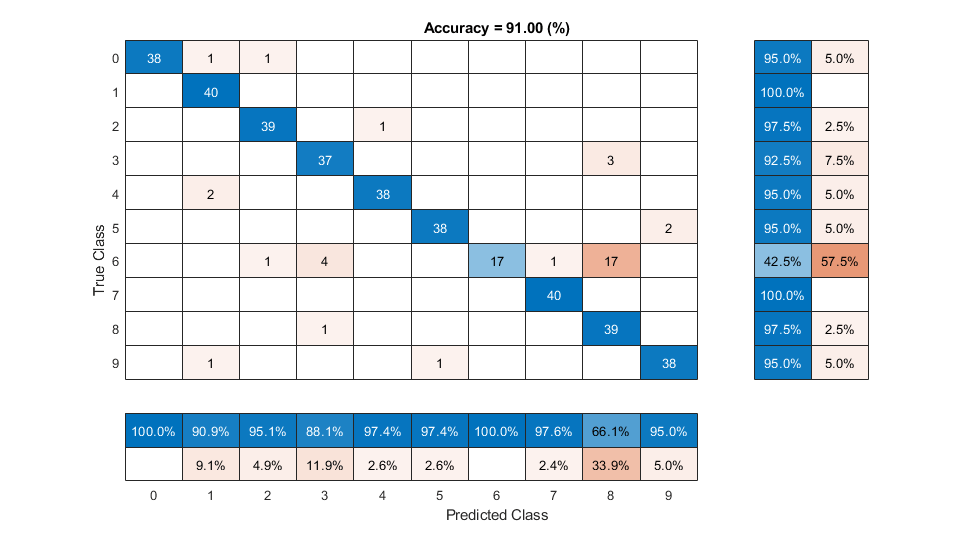
References
[1] Jakobovski. "Jakobovski/Free-Spoken-Digit-Dataset." GitHub, May 30, 2019. https://github.com/Jakobovski/free-spoken-digit-dataset.
References
[1] Reynolds, Douglas A., et al. “Speaker Verification Using Adapted Gaussian Mixture Models.” Digital Signal Processing, vol. 10, no. 1–3, Jan. 2000, pp. 19–41. DOI.org (Crossref), doi:10.1006/dspr.1999.0361.
[2] Kenny, Patrick, et al. “Joint Factor Analysis Versus Eigenchannels in Speaker Recognition.” IEEE Transactions on Audio, Speech and Language Processing, vol. 15, no. 4, May 2007, pp. 1435–47. DOI.org (Crossref), doi:10.1109/TASL.2006.881693.
[3] Kenny, P., et al. “A Study of Interspeaker Variability in Speaker Verification.” IEEE Transactions on Audio, Speech, and Language Processing, vol. 16, no. 5, July 2008, pp. 980–88. DOI.org (Crossref), doi:10.1109/TASL.2008.925147.
[4] Dehak, Najim, et al. “Front-End Factor Analysis for Speaker Verification.” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, May 2011, pp. 788–98. DOI.org (Crossref), doi:10.1109/TASL.2010.2064307.
[5] Matejka, Pavel, Ondrej Glembek, Fabio Castaldo, M. J. Alam, Oldrich Plchot, Patrick Kenny, Lukas Burget, and Jan Cernocky. “Full-Covariance UBM and Heavy-Tailed PLDA in i-Vector Speaker Verification.” 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2011. https://doi.org/10.1109/icassp.2011.5947436.
[6] Snyder, David, et al. “X-Vectors: Robust DNN Embeddings for Speaker Recognition.” 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2018, pp. 5329–33. DOI.org (Crossref), doi:10.1109/ICASSP.2018.8461375.
[7] Signal Processing and Speech Communication Laboratory. Accessed December 12, 2019. https://www.spsc.tugraz.at/databases-and-tools/ptdb-tug-pitch-tracking-database-from-graz-university-of-technology.html.
[8] Variani, Ehsan, et al. “Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification.” 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2014, pp. 4052–56. DOI.org (Crossref), doi:10.1109/ICASSP.2014.6854363.
[9] Dehak, Najim, Réda Dehak, James R. Glass, Douglas A. Reynolds and Patrick Kenny. “Cosine Similarity Scoring without Score Normalization Techniques.” Odyssey (2010).
[10] Verma, Pulkit, and Pradip K. Das. “I-Vectors in Speech Processing Applications: A Survey.” International Journal of Speech Technology, vol. 18, no. 4, Dec. 2015, pp. 529–46. DOI.org (Crossref), doi:10.1007/s10772-015-9295-3.
[11] D. García-Romero and C. Espy-Wilson, “Analysis of I-vector Length Normalization in Speaker Recognition Systems.” Interspeech, 2011, pp. 249–252.
[12] Kenny, Patrick. "Bayesian Speaker Verification with Heavy-Tailed Priors". Odyssey 2010 - The Speaker and Language Recognition Workshop, Brno, Czech Republic, 2010.
[13] Sizov, Aleksandr, Kong Aik Lee, and Tomi Kinnunen. “Unifying Probabilistic Linear Discriminant Analysis Variants in Biometric Authentication.” Lecture Notes in Computer Science Structural, Syntactic, and Statistical Pattern Recognition, 2014, 464–75. https://doi.org/10.1007/978-3-662-44415-3_47.
[14] Rajan, Padmanabhan, Anton Afanasyev, Ville Hautamäki, and Tomi Kinnunen. “From Single to Multiple Enrollment I-Vectors: Practical PLDA Scoring Variants for Speaker Verification.” Digital Signal Processing 31 (August), 2014, pp. 93–101. https://doi.org/10.1016/j.dsp.2014.05.001.
Version History
Introduced in R2021a