kfoldPredict
Classify observations in cross-validated kernel ECOC model
Syntax
Description
label = kfoldPredict(CVMdl)ClassificationPartitionedKernelECOC) CVMdl. For every fold,
kfoldPredict predicts class labels for validation-fold observations
using a model trained on training-fold observations. kfoldPredict
applies the same data used to create CVMdl (see fitcecoc).
The software predicts the classification of an observation by assigning the observation to the class yielding the largest negated average binary loss (or, equivalently, the smallest average binary loss).
label = kfoldPredict(CVMdl,Name,Value)
[
additionally returns negated values of the average binary loss per class
(label,NegLoss,PBScore]
= kfoldPredict(___)NegLoss) for validation-fold observations and positive-class scores
(PBScore) for validation-fold observations classified by each binary
learner, using any of the input argument combinations in the previous syntaxes.
If the coding matrix varies across folds (that is, the coding scheme is
sparserandom or denserandom), then
PBScore is empty ([]).
[
additionally returns posterior class probability estimates for validation-fold observations
(label,NegLoss,PBScore,Posterior]
= kfoldPredict(___)Posterior).
To obtain posterior class probabilities, the kernel classification binary learners must
be logistic regression models. Otherwise, kfoldPredict throws an
error.
Examples
Classify observations using a cross-validated, multiclass kernel ECOC classifier, and display the confusion matrix for the resulting classification.
Load Fisher's iris data set. X contains flower measurements, and Y contains the names of flower species.
load fisheriris
X = meas;
Y = species;Cross-validate an ECOC model composed of kernel binary learners.
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners','kernel','CrossVal','on')
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedKernelECOC model. By default, the software implements 10-fold cross-validation. To specify a different number of folds, use the 'KFold' name-value pair argument instead of 'Crossval'.
Classify the observations that fitcecoc does not use in training the folds.
label = kfoldPredict(CVMdl);
Construct a confusion matrix to compare the true classes of the observations to their predicted labels.
C = confusionchart(Y,label);
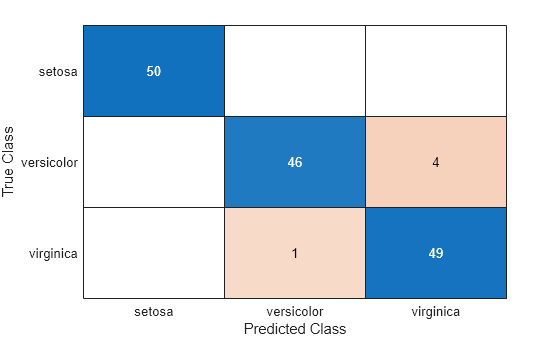
The CVMdl model misclassifies four 'versicolor' irises as 'virginica' irises and misclassifies one 'virginica' iris as a 'versicolor' iris.
Load Fisher's iris data set. X contains flower measurements, and Y contains the names of flower species.
load fisheriris
X = meas;
Y = species;Cross-validate an ECOC model of kernel classification models using 5-fold cross-validation.
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners','kernel','KFold',5)
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 5
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedKernelECOC model. It contains the property Trained, which is a 5-by-1 cell array of CompactClassificationECOC models.
By default, the kernel classification models that compose the CompactClassificationECOC models use SVMs. SVM scores are signed distances from the observation to the decision boundary. Therefore, the domain is . Create a custom binary loss function that:
Maps the coding design matrix (M) and positive-class classification scores (s) for each learner to the binary loss for each observation
Uses linear loss
Aggregates the binary learner loss using the median
You can create a separate function for the binary loss function, and then save it on the MATLAB® path. Or, you can specify an anonymous binary loss function. In this case, create a function handle (customBL) to an anonymous binary loss function.
customBL = @(M,s)median(1 - (M.*s),2,'omitnan')/2;Predict cross-validation labels and estimate the median binary loss per class. Print the median negative binary losses per class for a random set of 10 observations.
[label,NegLoss] = kfoldPredict(CVMdl,'BinaryLoss',customBL); idx = randsample(numel(label),10); table(Y(idx),label(idx),NegLoss(idx,1),NegLoss(idx,2),NegLoss(idx,3),... 'VariableNames',[{'True'};{'Predicted'};... unique(CVMdl.ClassNames)])
ans=10×5 table
True Predicted setosa versicolor virginica
______________ ______________ ________ __________ _________
{'setosa' } {'setosa' } 0.20926 -0.84572 -0.86354
{'setosa' } {'setosa' } 0.16144 -0.90572 -0.75572
{'virginica' } {'versicolor'} -0.83532 -0.12157 -0.54311
{'virginica' } {'virginica' } -0.97235 -0.69759 0.16994
{'virginica' } {'virginica' } -0.89441 -0.69937 0.093778
{'virginica' } {'virginica' } -0.86774 -0.47297 -0.15929
{'setosa' } {'setosa' } -0.1026 -0.69671 -0.70069
{'setosa' } {'setosa' } 0.1001 -0.89163 -0.70848
{'virginica' } {'virginica' } -1.0106 -0.52919 0.039829
{'versicolor'} {'versicolor'} -1.0298 0.027354 -0.49757
The cross-validated model correctly predicts the labels for 9 of the 10 random observations.
Estimate posterior class probabilities using a cross-validated, multiclass kernel ECOC classification model. Kernel classification models return posterior probabilities for logistic regression learners only.
Load Fisher's iris data set. X contains flower measurements, and Y contains the names of flower species.
load fisheriris
X = meas;
Y = species;Create a kernel template for the binary kernel classification models. Specify to fit logistic regression learners.
t = templateKernel('Learner','logistic')
t =
Fit template for classification Kernel.
BetaTolerance: []
BlockSize: []
BoxConstraint: []
Epsilon: []
NumExpansionDimensions: []
GradientTolerance: []
HessianHistorySize: []
IterationLimit: []
KernelScale: []
Lambda: []
Learner: 'logistic'
LossFunction: []
Stream: []
VerbosityLevel: []
StandardizeData: []
Version: 1
Method: 'Kernel'
Type: 'classification'
t is a kernel template. Most of its properties are empty. When training an ECOC classifier using the template, the software sets the applicable properties to their default values.
Cross-validate an ECOC model using the kernel template.
rng('default'); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'CrossVal','on')
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedECOC model. By default, the software uses 10-fold cross-validation.
Predict the validation-fold class posterior probabilities.
[label,~,~,Posterior] = kfoldPredict(CVMdl);
The software assigns an observation to the class that yields the smallest average binary loss. Because all binary learners are computing posterior probabilities, the binary loss function is quadratic.
Display the posterior probabilities for 10 randomly selected observations.
idx = randsample(size(X,1),10); CVMdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
table(Y(idx),label(idx),Posterior(idx,:),... 'VariableNames',{'TrueLabel','PredLabel','Posterior'})
ans=10×3 table
TrueLabel PredLabel Posterior
______________ ______________ ________________________________
{'setosa' } {'setosa' } 0.68216 0.18546 0.13238
{'virginica' } {'virginica' } 0.1581 0.14405 0.69785
{'virginica' } {'virginica' } 0.071807 0.093291 0.8349
{'setosa' } {'setosa' } 0.74918 0.11434 0.13648
{'versicolor'} {'versicolor'} 0.09375 0.67149 0.23476
{'versicolor'} {'versicolor'} 0.036202 0.85544 0.10836
{'versicolor'} {'versicolor'} 0.2252 0.50473 0.27007
{'virginica' } {'virginica' } 0.061562 0.11086 0.82758
{'setosa' } {'setosa' } 0.42448 0.21181 0.36371
{'virginica' } {'virginica' } 0.082705 0.1428 0.7745
The columns of Posterior correspond to the class order of CVMdl.ClassNames.