kfoldMargin
Classification margins for cross-validated kernel ECOC model
Description
margin = kfoldMargin(CVMdl)ClassificationPartitionedKernelECOC) CVMdl. For every fold,
kfoldMargin computes the classification margins for validation-fold
observations using a model trained on training-fold observations.
margin = kfoldMargin(CVMdl,Name,Value)
Examples
Load Fisher's iris data set. X contains flower measurements, and Y contains the names of flower species.
load fisheriris
X = meas;
Y = species;Cross-validate an ECOC model composed of kernel binary learners.
CVMdl = fitcecoc(X,Y,'Learners','kernel','CrossVal','on')
CVMdl =
ClassificationPartitionedKernelECOC
CrossValidatedModel: 'KernelECOC'
ResponseName: 'Y'
NumObservations: 150
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedKernelECOC model. By default, the software implements 10-fold cross-validation. To specify a different number of folds, use the 'KFold' name-value pair argument instead of 'Crossval'.
Estimate the classification margins for validation-fold observations.
m = kfoldMargin(CVMdl); size(m)
ans = 1×2
150 1
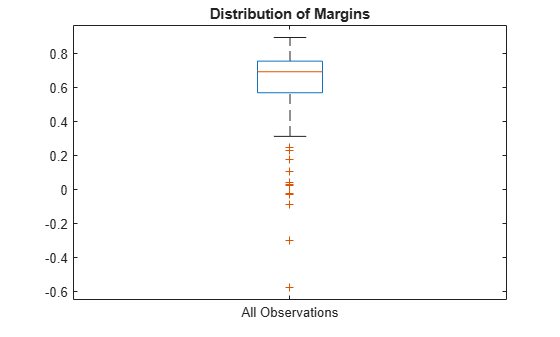
m is a 150-by-1 vector. m(j) is the classification margin for observation j.
Plot the k-fold margins using a boxplot.
boxplot(m,'Labels','All Observations') title('Distribution of Margins')
Perform feature selection by comparing k-fold margins from multiple models. Based solely on this criterion, the classifier with the greatest margins is the best classifier.
Load Fisher's iris data set. X contains flower measurements, and Y contains the names of flower species.
load fisheriris
X = meas;
Y = species;Randomly choose half of the predictor variables.
rng(1); % For reproducibility p = size(X,2); % Number of predictors idxPart = randsample(p,ceil(0.5*p));
Cross-validate two ECOC models composed of kernel classification models: one that uses all of the predictors, and one that uses half of the predictors.
CVMdl = fitcecoc(X,Y,'Learners','kernel','CrossVal','on'); PCVMdl = fitcecoc(X(:,idxPart),Y,'Learners','kernel','CrossVal','on');
CVMdl and PCVMdl are ClassificationPartitionedKernelECOC models. By default, the software implements 10-fold cross-validation. To specify a different number of folds, use the 'KFold' name-value pair argument instead of 'Crossval'.
Estimate the k-fold margins for each classifier.
fullMargins = kfoldMargin(CVMdl); partMargins = kfoldMargin(PCVMdl);
Plot the distribution of the margin sets using box plots.
boxplot([fullMargins partMargins], ... 'Labels',{'All Predictors','Half of the Predictors'}); title('Distribution of Margins')
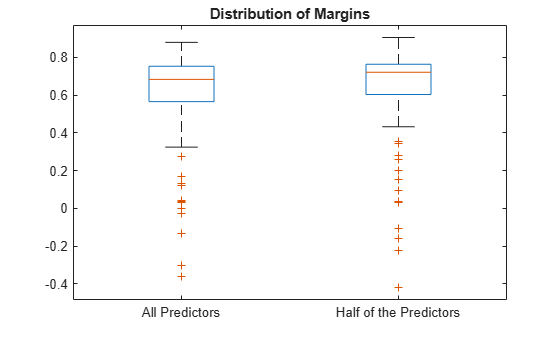
The PCVMdl margin distribution is similar to the CVMdl margin distribution.