kfoldLoss
Classification loss for cross-validated linear classification model
Description
L = kfoldLoss(CVMdl)CVMdl. That is, for every fold,
kfoldLoss estimates the classification loss for
observations that it holds out when it trains using all other observations.
L contains a classification loss for each regularization strength in the
linear classification models that compose CVMdl.
L = kfoldLoss(CVMdl,Name=Value)
Examples
Load the NLP data set.
load nlpdataX is a sparse matrix of predictor data, and Y is a categorical vector of class labels. There are more than two classes in the data.
The models should identify whether the word counts in a web page are from the Statistics and Machine Learning Toolbox™ documentation. So, identify the labels that correspond to the Statistics and Machine Learning Toolbox™ documentation web pages.
Ystats = Y == 'stats';Cross-validate a binary, linear classification model that can identify whether the word counts in a documentation web page are from the Statistics and Machine Learning Toolbox™ documentation.
rng(1); % For reproducibility CVMdl = fitclinear(X,Ystats,'CrossVal','on');
CVMdl is a ClassificationPartitionedLinear model. By default, the software implements 10-fold cross validation. You can alter the number of folds using the 'KFold' name-value pair argument.
Estimate the average of the out-of-fold, classification error rates.
ce = kfoldLoss(CVMdl)
ce = 7.6017e-04
Alternatively, you can obtain the per-fold classification error rates by specifying the name-value pair 'Mode','individual' in kfoldLoss.
Load the NLP data set. Preprocess the data as in Estimate k-Fold Cross-Validation Classification Error, and transpose the predictor data.
load nlpdata Ystats = Y == 'stats'; X = X';
Cross-validate a binary, linear classification model using 5-fold cross-validation. Optimize the objective function using SpaRSA. Specify that the predictor observations correspond to columns.
rng(1) % For reproducibility CVMdl = fitclinear(X,Ystats,'Solver','sparsa','KFold',5, ... 'ObservationsIn','columns'); CMdl = CVMdl.Trained{1};
CVMdl is a ClassificationPartitionedLinear model. It contains the property Trained, which is a 5-by-1 cell array holding a ClassificationLinear models that the software trained using the training set of each fold.
Create an anonymous function that measures linear loss, that is,
is the weight for observation j, is response j (-1 for the negative class, and 1 otherwise), and is the raw classification score of observation j. Custom loss functions must be written in a particular form. For rules on writing a custom loss function, see the LossFun name-value pair argument. Because the function does not use classification cost, use ~ to have kfoldLoss ignore its position.
linearloss = @(C,S,W,~)sum(-W.*sum(S.*C,2))/sum(W);
Estimate the average cross-validated classification loss using the linear loss function. Also, obtain the loss for each fold.
ce = kfoldLoss(CVMdl,'LossFun',linearloss)ce = -8.0982
ceFold = kfoldLoss(CVMdl,'LossFun',linearloss,'Mode','individual')
ceFold = 5×1
-8.3165
-8.7633
-7.4342
-8.0423
-7.9347
To determine a good lasso-penalty strength for a linear classification model that uses a logistic regression learner, compare test-sample classification error rates.
Load the NLP data set. Preprocess the data as in Specify Custom Classification Loss.
load nlpdata Ystats = Y == 'stats'; X = X';
Create a set of 11 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-6,-0.5,11);
Cross-validate binary, linear classification models using 5-fold cross-validation, and that use each of the regularization strengths. Optimize the objective function using SpaRSA. Lower the tolerance on the gradient of the objective function to 1e-8.
rng(10); % For reproducibility CVMdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'KFold',5,'Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8)
CVMdl =
ClassificationPartitionedLinear
CrossValidatedModel: 'Linear'
ResponseName: 'Y'
NumObservations: 31572
KFold: 5
Partition: [1×1 cvpartition]
ClassNames: [0 1]
ScoreTransform: 'none'
Properties, Methods
Extract a trained linear classification model.
Mdl1 = CVMdl.Trained{1}Mdl1 =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'logit'
Beta: [34023×11 double]
Bias: [-13.2949 -13.2950 -13.2950 -13.2950 -9.4521 -7.1038 -5.4345 -4.6431 -3.6889 -3.1589 -2.9793]
Lambda: [1.0000e-06 3.5481e-06 1.2589e-05 4.4668e-05 1.5849e-04 5.6234e-04 0.0020 0.0071 0.0251 0.0891 0.3162]
Learner: 'logistic'
Properties, Methods
Mdl1 is a ClassificationLinear model object. Because Lambda is a sequence of regularization strengths, you can think of Mdl as 11 models, one for each regularization strength in Lambda.
Estimate the cross-validated classification error.
ce = kfoldLoss(CVMdl);
Because there are 11 regularization strengths, ce is a 1-by-11 vector of classification error rates.
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a classifier. For each regularization strength, train a linear classification model using the entire data set and the same options as when you cross-validated the models. Determine the number of nonzero coefficients per model.
Mdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'Learner','logistic','Solver','sparsa','Regularization','lasso',... 'Lambda',Lambda,'GradientTolerance',1e-8); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the cross-validated, classification error rates and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(ce),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} classification error') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') title('Test-Sample Statistics') hold off
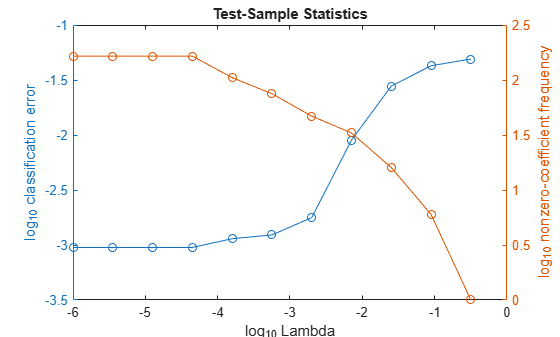
Choose the indexes of the regularization strength that balances predictor variable sparsity and low classification error. In this case, a value between to should suffice.
idxFinal = 7;
Select the model from Mdl with the chosen regularization strength.
MdlFinal = selectModels(Mdl,idxFinal);
MdlFinal is a ClassificationLinear model containing one regularization strength. To estimate labels for new observations, pass MdlFinal and the new data to predict.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Classification loss functions measure the predictive inaccuracy of classification models. When you compare the same type of loss among many models, a lower loss indicates a better predictive model.
Consider the following scenario.
L is the weighted average classification loss.
n is the sample size.
yj is the observed class label. The software codes it as –1 or 1, indicating the negative or positive class (or the first or second class in the
ClassNamesproperty), respectively.f(Xj) is the positive-class classification score for observation (row) j of the predictor data X.
mj = yjf(Xj) is the classification score for classifying observation j into the class corresponding to yj. Positive values of mj indicate correct classification and do not contribute much to the average loss. Negative values of mj indicate incorrect classification and contribute significantly to the average loss.
The weight for observation j is wj. The software normalizes the observation weights so that they sum to the corresponding prior class probability stored in the
Priorproperty. Therefore,
Given this scenario, the following table describes the supported loss functions that you can specify by using the LossFun name-value argument.
| Loss Function | Value of LossFun | Equation |
|---|---|---|
| Binomial deviance | "binodeviance" | |
| Observed misclassification cost | "classifcost" | where is the class label corresponding to the class with the maximal score, and is the user-specified cost of classifying an observation into class when its true class is yj. |
| Misclassified rate in decimal | "classiferror" | where I{·} is the indicator function. |
| Cross-entropy loss | "crossentropy" |
The weighted cross-entropy loss is where the weights are normalized to sum to n instead of 1. |
| Exponential loss | "exponential" | |
| Hinge loss | "hinge" | |
| Logistic loss | "logit" | |
| Minimal expected misclassification cost | "mincost" |
The software computes the weighted minimal expected classification cost using this procedure for observations j = 1,...,n.
The weighted average of the minimal expected misclassification cost loss is |
| Quadratic loss | "quadratic" |
If you use the default cost matrix (whose element value is 0 for correct classification
and 1 for incorrect classification), then the loss values for
"classifcost", "classiferror", and
"mincost" are identical. For a model with a nondefault cost matrix,
the "classifcost" loss is equivalent to the "mincost"
loss most of the time. These losses can be different if prediction into the class with
maximal posterior probability is different from prediction into the class with minimal
expected cost. Note that "mincost" is appropriate only if classification
scores are posterior probabilities.
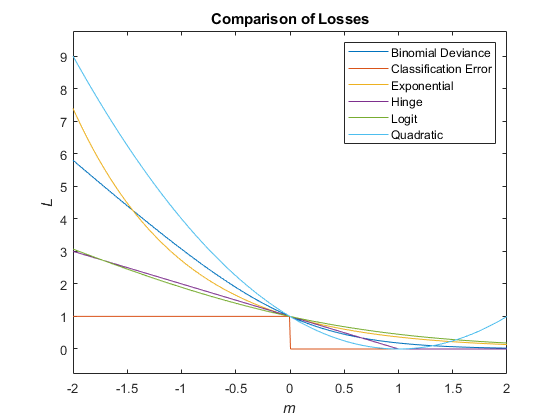
This figure compares the loss functions (except "classifcost",
"crossentropy", and "mincost") over the score
m for one observation. Some functions are normalized to pass through
the point (0,1).
Extended Capabilities
Version History
Introduced in R2016aSee Also
ClassificationPartitionedLinear | ClassificationLinear | kfoldPredict | loss