robustcov
Robust multivariate covariance and mean estimate
Syntax
Description
[___] = robustcov( returns
any of the arguments shown in the previous syntaxes, using additional
options specified by one or more x,Name,Value)Name,Value pair
arguments. For example, you can specify which robust estimator to
use or the start method to use for the attractors.
Examples
Use a Gaussian copula to generate random data points from a bivariate distribution.
rng default rho = [1,0.05;0.05,1]; u = copularnd('Gaussian',rho,50);
Modify 5 randomly selected observations to be outliers.
noise = randperm(50,5); u(noise,1) = u(noise,1)*5;
Calculate the robust covariance matrices using the three available methods: Fast-MCD, Orthogonalized Gnanadesikan-Kettenring (OGK), and Olive-Hawkins.
[Sfmcd, Mfmcd, dfmcd, Outfmcd] = robustcov(u); [Sogk, Mogk, dogk, Outogk] = robustcov(u,'Method','ogk'); [Soh, Moh, doh, Outoh] = robustcov(u,'Method','olivehawkins');
Calculate the classical distance values for the sample data using the Mahalanobis measure.
d_classical = pdist2(u, mean(u),'mahal');
p = size(u,2);
chi2quantile = sqrt(chi2inv(0.975,p));Create DD Plots for each robust covariance calculation method.
tiledlayout(2,2) nexttile plot(d_classical, dfmcd, 'o') line([chi2quantile, chi2quantile], [0, 30], 'color', 'r') line([0, 6], [chi2quantile, chi2quantile], 'color', 'r') hold on plot(d_classical(Outfmcd), dfmcd(Outfmcd), 'r+') xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('DD Plot, FMCD method') hold off nexttile plot(d_classical, dogk, 'o') line([chi2quantile, chi2quantile], [0, 30], 'color', 'r') line([0, 6], [chi2quantile, chi2quantile], 'color', 'r') hold on plot(d_classical(Outogk), dogk(Outogk), 'r+') xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('DD Plot, OGK method') hold off nexttile plot(d_classical, doh, 'o') line([chi2quantile, chi2quantile], [0, 30], 'color', 'r') line([0, 6], [chi2quantile, chi2quantile], 'color', 'r') hold on plot(d_classical(Outoh), doh(Outoh), 'r+') xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('DD Plot, Olive-Hawkins method') hold off
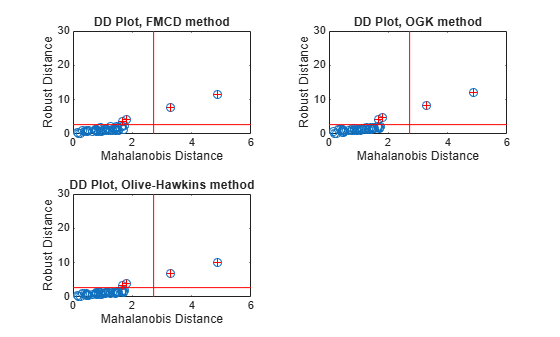
In a DD plot, the data points tend to cluster in a straight line that passes through the origin. Points that are far removed from this line are generally considered outliers. In each of the previous plots, the red '+' symbol indicates the data points that robustcov considers to be outliers.
This example shows how to use robustcov to evaluate sample data for multivariate normal or other elliptically-contoured (EC) distributions.
Generate random sample data from a multivariate normal distribution. Calculate the Mahalanobis distances for the robust covariance estimates (using the Olive-Hawkins method) and the classical covariance estimates.
rng('default') x1 = mvnrnd(zeros(1,3),eye(3),200); [~, ~, d1] = robustcov(x1,'Method','olivehawkins'); d_classical1 = pdist2(x1,mean(x1),'mahalanobis');
Generate random sample data from an elliptically-contoured (EC) distribution. Calculate the Mahalanobis distances for the robust covariance estimates (using the Olive-Hawkins method) and the classical covariance estimates.
mu1 = [0 0 0]; sig1 = eye(3); mu2 = [0 0 0]; sig2 = 25*eye(3); x2 = [mvnrnd(mu1,sig1,120);mvnrnd(mu2,sig2,80)]; [~, ~, d2] = robustcov(x2, 'Method','olivehawkins'); d_classical2 = pdist2(x2, mean(x2), 'mahalanobis');
Generate random sample data from a multivariate lognormal distribution, which is neither multivariate normal or elliptically-contoured. Calculate the Mahalanobis distances for the robust covariance estimates (using the Olive-Hawkins method) and the classical covariance estimates.
x3 = exp(x1); [~, ~, d3] = robustcov(x3, 'Method','olivehawkins'); d_classical3 = pdist2(x3, mean(x3), 'mahalanobis');
Create a D-D Plot for each of the three sets of sample data to compare.
figure subplot(2,2,1) plot(d_classical1,d1, 'o') line([0 4.5], [0, 4.5]) xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('DD Plot, Multivariate Normal') subplot(2,2,2) plot(d_classical2, d2, 'o') line([0 18], [0, 18]) xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('DD Plot, Elliptically-Contoured') subplot(2,2,3) plot(d_classical3, d3, 'o') line([0 18], [0, 18]) xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('DD Plot, 200 Lognormal cases')
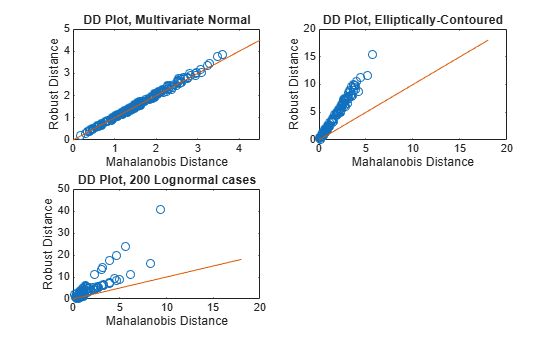
For data with a multivariate normal distribution (as shown in the upper left), the plotted points follow a straight, 45-degree line extending from the origin. For data with an elliptically-contoured distribution (as shown in the upper right), the plotted points follow a straight line, but are not at a 45-degree angle to the origin. For the lognormal distribution (as shown in the lower left), the plotted points do not follow a straight line.
It is difficult to identify any pattern in the lognormal distribution plot because most of the points are in the lower left of the plot. Use a weighted DD plot to magnify this corner and reveal features that are obscured when large robust distances exist.
d3_weighted = d3(d3 < sqrt(chi2inv(0.975,3))); d_classical_weighted = d_classical3(d3 < sqrt(chi2inv(0.975,3)));
Add a fourth subplot to the figure to show the results of the weighting process on the lognormally distributed data.
subplot(2,2,4) plot(d_classical_weighted, d3_weighted, 'o') line([0 3], [0, 3]) xlabel('Mahalanobis Distance') ylabel('Robust Distance') title('Weighted DD Plot, 200 Lognormal cases')
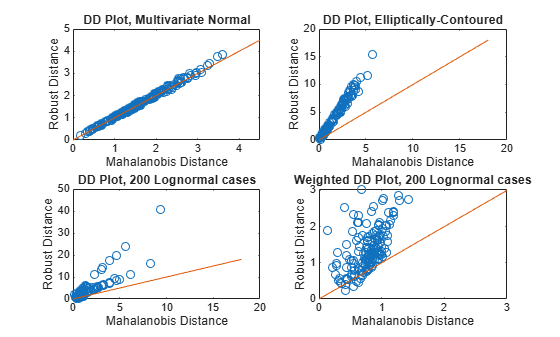
The scale on this plot indicates that it represents a magnified view of the original DD plot for the lognormal data. This view more clearly shows the lack of pattern to the plot, which indicates that the data is neither multivariate normal nor elliptically contoured.
Use a Gaussian copula to generate random data points from a bivariate distribution.
rng default rho = [1,0.05;0.05,1]; u = copularnd('Gaussian',rho,50);
Modify 5 randomly selected observations to be outliers.
noise = randperm(50,5); u(noise,1) = u(noise,1)*5;
Visualize the bivariate data using a scatter plot.
figure scatter(u(:,1),u(:,2))
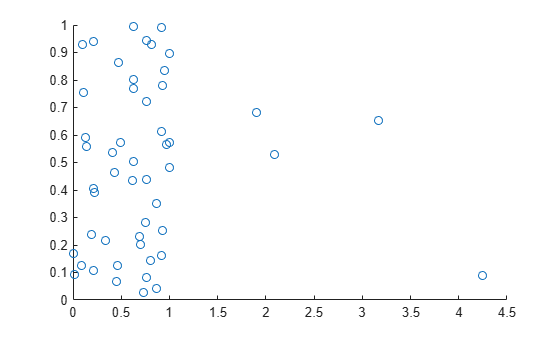
Most of the data points appear on the left side of the plot. However, some of the data points appear further to the right. These points are possible outliers that could affect the covariance matrix calculation.
Compare the classical and robust covariance matrices.
c = cov(u)
c = 2×2
0.5523 0.0000
0.0000 0.0913
rc = robustcov(u)
rc = 2×2
0.1117 0.0364
0.0364 0.1695
The classical and robust covariance matrices differ because the outliers present in the sample data influence the results.
Identify and plot the data points that robustcov considers outliers.
[sig,mu,mah,outliers] = robustcov(u); figure gscatter(u(:,1),u(:,2),outliers,'br','ox') legend({'Not outliers','Outliers'})
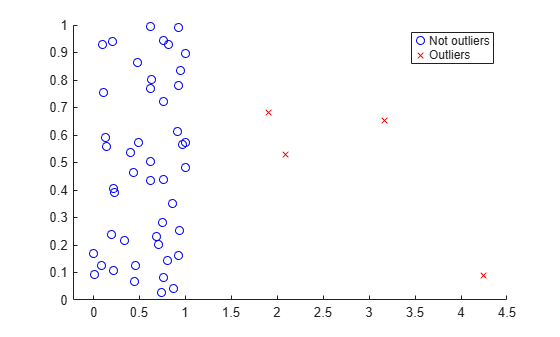
robustcov identifies the data points on the right side of the plot as potential outliers, and treats them accordingly when calculating the robust covariance matrix.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Maronna, R. and Zamar, R.H.. “Robust estimates of location and dispersion for high-dimensional datasets.” Technometrics, Vol. 50, 2002.
[2] Pison, S. Van Aelst and G. Willems. “Small Sample Corrections for LTS and MCD.” Metrika, Vol. 55, 2002.
[3] Rousseeuw, P.J. and Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator.” Technometrics, Vol. 41, 1999.
[4] Olive, D.J. “A resistant estimator of multivariate location and dispersion.” Computational Statistics and Data Analysis, Vol. 46, pp. 99–102, 2004.
Extended Capabilities
Version History
Introduced in R2016a