Feature Extraction
Extract features from audio signals for use as input to machine
learning or deep learning systems. Use individual functions, such as
melSpectrogram, mfcc, pitch, and spectralCentroid, or use the audioFeatureExtractor object to create a feature
extraction pipeline that minimizes redundant calculations. Use blocks
such as Mel
Spectrogram and MFCC to extract features from audio signals in Simulink®. In live scripts, use Extract Audio Features to graphically select the
features to extract.
Objects
audioFeatureExtractor | Streamline audio feature extraction |
ivectorSystem | Create i-vector system |
Live Editor Tasks
| Extract Audio Features | Streamline audio feature extraction in the Live Editor |
Functions
Blocks
| Audio Delta | Compute delta features (Since R2022b) |
| Auditory Spectrogram | Extract mel, Bark, or ERB spectrogram from audio (Since R2022a) |
| Cepstral Coefficients | Extract cepstral coefficients from spectrogram (Since R2022b) |
| Design Auditory Filter Bank | Design frequency-domain auditory filter bank (Since R2022a) |
| Design Mel Filter Bank | Design frequency-domain mel filter bank (Since R2022a) |
| Mel Spectrogram | Extract mel spectrogram from audio (Since R2022a) |
| MFCC | Extract mel-frequency cepstral coefficients from audio (Since R2022b) |
Topics
- Feature Selection for Audio Classification
Perform audio feature selection to select a feature set for either speaker recognition or word recognition tasks.
- Extract Features from Audio Data Sets
Use different methods of extracting features from an audio data set.
- Spectral Descriptors
Overview and applications of spectral descriptors.
- Learn Pre-Emphasis Filter Using Deep Learning
Use a convolutional deep network to learn a pre-emphasis filter for speech recognition. (Since R2021b)
Featured Examples
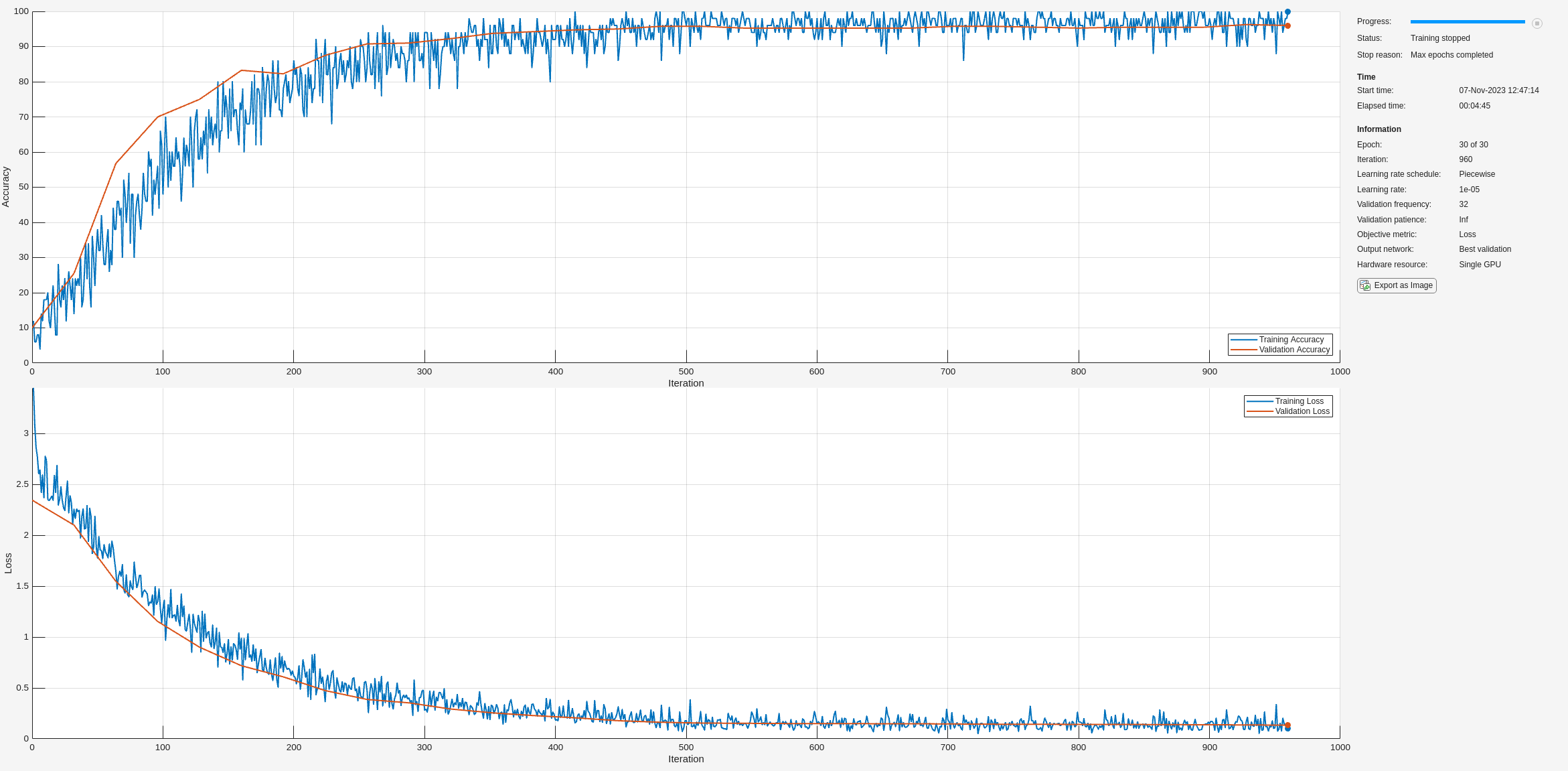
Train Spoken Digit Recognition Network Using Out-of-Memory Features
Trains a spoken digit recognition network on out-of-memory auditory spectrograms using a transformed datastore. In this example, you extract auditory spectrograms from audio using audioDatastore and audioFeatureExtractor, and you write them to disk. You then use a signalDatastore to access the features during training. The workflow is useful when the training features do not fit in memory. In this workflow, you only extract features once, which speeds up your workflow if you are iterating on the deep learning model design.
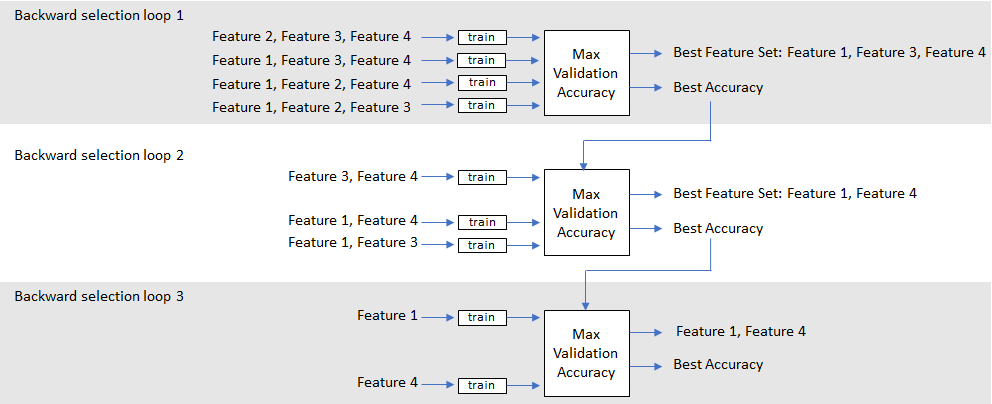
Sequential Feature Selection for Audio Features
A typical workflow for feature selection applied to the task of spoken digit recognition.
Pitch Tracking Using Multiple Pitch Estimations and HMM
Perform pitch tracking using multiple pitch estimations, octave and median smoothing, and a hidden Markov model (HMM).