Define Custom Deep Learning Layers
Tip
This topic explains how to define custom deep learning layers for your problems. For a list of built-in layers in Deep Learning Toolbox™, see List of Deep Learning Layers.
If Deep Learning Toolbox does not provide the layer that you require for your task, then you can define your own custom layer using this topic as a guide. After you define the custom layer, you can automatically check that the layer is valid and GPU compatible, and outputs correctly defined gradients.
Neural Network Layer Architecture
During training, the software iteratively performs forward and backward passes through the network.
During a forward pass through the network, each layer takes the outputs of the previous layers, applies a function, and then outputs (forward propagates) the results to the next layers. Stateful layers, such as LSTM layers, also update the layer state.
Layers can have multiple inputs or outputs. For example, a layer can take X1, …, XN from multiple previous layers and forward propagate the outputs Y1, …, YM to subsequent layers.
At the end of a forward pass of the network, the software calculates the loss L between the predictions and the targets.
During the backward pass through the network, each layer takes the derivatives of the loss with respect to the outputs of the layer, computes the derivatives of the loss L with respect to the inputs, and then backward propagates the results. If the layer has learnable parameters, then the layer also computes the derivatives of the loss with respect to the layer weights (learnable parameters). The software uses these derivatives to update the learnable parameters. To save on computation, the forward function can share information with the backward function using an optional memory output.
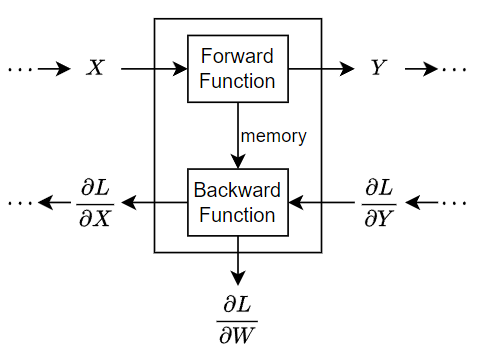
This figure illustrates the flow of data through a deep neural network and highlights the data flow through a layer with a single input X, a single output Y, and a learnable parameter W.
Custom Layer Template
To define a custom layer, use this class definition template. This template gives the structure of a custom layer class definition. It outlines:
The optional
propertiesblocks for the layer properties, learnable parameters, and state parameters. For more information, see Custom Layer Properties.The layer constructor function.
The
predictfunction and the optionalforwardfunction. For more information, see Forward Functions.The optional
resetStatefunction for layers with state properties. For more information, see Reset State Function.The optional
backwardfunction. For more information, see Backward Function.
classdef myLayer < nnet.layer.Layer % ... % & nnet.layer.Formattable ... % (Optional) % & nnet.layer.Acceleratable % (Optional) properties % (Optional) Layer properties. % Declare layer properties here. end properties (Learnable) % (Optional) Layer learnable parameters. % Declare learnable parameters here. end properties (State) % (Optional) Layer state parameters. % Declare state parameters here. end properties (Learnable, State) % (Optional) Nested dlnetwork objects with both learnable % parameters and state parameters. % Declare nested networks with learnable and state parameters here. end methods function layer = myLayer() % (Optional) Create a myLayer. % This function must have the same name as the class. % Define layer constructor function here. end function layer = initialize(layer,layout) % (Optional) Initialize layer learnable and state parameters. % % Inputs: % layer - Layer to initialize % layout - Data layout, specified as a networkDataLayout % object % % Outputs: % layer - Initialized layer % % - For layers with multiple inputs, replace layout with % layout1,...,layoutN, where N is the number of inputs. % Define layer initialization function here. end function [Y,state] = predict(layer,X) % Forward input data through the layer at prediction time and % output the result and updated state. % % Inputs: % layer - Layer to forward propagate through % X - Input data % Outputs: % Y - Output of layer forward function % state - (Optional) Updated layer state % % - For layers with multiple inputs, replace X with X1,...,XN, % where N is the number of inputs. % - For layers with multiple outputs, replace Y with % Y1,...,YM, where M is the number of outputs. % - For layers with multiple state parameters, replace state % with state1,...,stateK, where K is the number of state % parameters. % Define layer predict function here. end function [Y,state,memory] = forward(layer,X) % (Optional) Forward input data through the layer at training % time and output the result, the updated state, and a memory % value. % % Inputs: % layer - Layer to forward propagate through % X - Layer input data % Outputs: % Y - Output of layer forward function % state - (Optional) Updated layer state % memory - (Optional) Memory value for custom backward % function % % - For layers with multiple inputs, replace X with X1,...,XN, % where N is the number of inputs. % - For layers with multiple outputs, replace Y with % Y1,...,YM, where M is the number of outputs. % - For layers with multiple state parameters, replace state % with state1,...,stateK, where K is the number of state % parameters. % Define layer forward function here. end function layer = resetState(layer) % (Optional) Reset layer state. % Define reset state function here. end function [dLdX,dLdW,dLdSin] = backward(layer,X,Y,dLdY,dLdSout,memory) % (Optional) Backward propagate the derivative of the loss % function through the layer. % % Inputs: % layer - Layer to backward propagate through % X - Layer input data % Y - Layer output data % dLdY - Derivative of loss with respect to layer % output % dLdSout - (Optional) Derivative of loss with respect % to state output % memory - Memory value from forward function % Outputs: % dLdX - Derivative of loss with respect to layer input % dLdW - (Optional) Derivative of loss with respect to % learnable parameter % dLdSin - (Optional) Derivative of loss with respect to % state input % % - For layers with state parameters, the backward syntax must % include both dLdSout and dLdSin, or neither. % - For layers with multiple inputs, replace X and dLdX with % X1,...,XN and dLdX1,...,dLdXN, respectively, where N is % the number of inputs. % - For layers with multiple outputs, replace Y and dLdY with % Y1,...,YM and dLdY,...,dLdYM, respectively, where M is the % number of outputs. % - For layers with multiple learnable parameters, replace % dLdW with dLdW1,...,dLdWP, where P is the number of % learnable parameters. % - For layers with multiple state parameters, replace dLdSin % and dLdSout with dLdSin1,...,dLdSinK and % dLdSout1,...,dldSoutK, respectively, where K is the number % of state parameters. % Define layer backward function here. end end end
Formatted Inputs and Outputs
Using dlarray objects makes working with high
dimensional data easier by allowing you to label the dimensions. For example, you can label
which dimensions correspond to spatial, time, channel, and batch dimensions using the
"S", "T", "C", and
"B" labels, respectively. For unspecified and other dimensions, use the
"U" label. For dlarray object functions that operate
over particular dimensions, you can specify the dimension labels by formatting the
dlarray object directly, or by using the DataFormat
option.
Using formatted dlarray objects in layers functions also allows you to define
layers where the inputs and outputs have different formats, such as layers that
permute, add, or remove dimensions. For example, you can define a layer that takes
as input a mini-batch of images with the format "SSCB" (spatial,
spatial, channel, batch) and output a mini-batch of sequences with the format
"CBT" (channel, batch, time). Using formatted
dlarray objects also allows you to define layers that can
operate on data with different input formats, for example, layers that support
inputs with the formats "SSCB" (spatial, spatial, channel, batch)
and "CBT" (channel, batch, time).
You can specify how to processes formatted and unformatted data that the software passes
to and from the layer by opting to inherit from the
nnet.layer.Formattable class. This table describes how the software
processes formatted and unformatted data in custom layers.
| Layer Definition | Input Data Processing | Output Data Processing |
|---|---|---|
Inherits from nnet.layer.Formattable |
The software passes the layer input to the layer function directly:
|
The software passes the layer function outputs to subsequent layers directly:
Warning For custom layers that inherit
from Before R2026a: The layer automatically applies the format of the input data to the unformatted output data.
|
Does not inherit from
nnet.layer.Formattable | The software removes the formats from any formatted inputs and passes the unformatted data to the layer function:
|
The output data must be unformatted. The software applies the formats of the layer inputs to any unformatted layer function outputs, and passes the result to subsequent layers:
|
For an example showing how to define a custom layer with formatted inputs, see Define Custom Deep Learning Layer with Formatted Inputs.
Custom Layer Acceleration
If you do not specify a backward function when you define a custom layer, then the software automatically determines the gradients using automatic differentiation.
When you train a network with a custom layer without a backward function, the
software traces each input dlarray object of the custom layer
forward function to determine the computation graph used for automatic
differentiation. This tracing process can take some time and can end up recomputing
the same trace. By optimizing, caching, and reusing the traces, you can speed up
gradient computation when training a network. The software can also reuse these
traces to speed up network predictions after training.
The trace depends on the size, format, and underlying data type of the layer inputs. That is, the layer triggers a new trace for inputs with a size, format, or underlying data type not contained in the cache. Any inputs differing only by value to a previously cached trace do not trigger a new trace.
To indicate that the custom layer supports acceleration, also inherit from the
nnet.layer.Acceleratable class when defining the custom
layer. When a custom layer inherits from
nnet.layer.Acceleratable, the software automatically caches
traces when passing data through a dlnetwork object.
For example, to indicate that the custom layer myLayer supports
acceleration, use this
syntax
classdef myLayer < nnet.layer.Layer & nnet.layer.Acceleratable ... end
Acceleration Considerations
Because of the nature of caching traces, not all functions support acceleration.
The caching process can cache values or code structures that you might expect to change or that depend on external factors. You must take care when accelerating custom layers that:
Generate random numbers.
Use
ifstatements andwhileloops with conditions that depend on the values ofdlarrayobjects.
Because the caching process requires extra computation, acceleration can lead to longer running code in some cases. This scenario can happen when the software spends time creating new caches that do not get reused often. For example, when you pass multiple mini-batches of different sequence lengths to the function, the software triggers a new trace for each unique sequence length.
When custom layer acceleration causes slowdown, you can disable acceleration
by removing the Acceleratable class or by disabling
acceleration of the dlnetwork object functions predict and
forward by setting the
Acceleration option to "none".
For more information about enabling acceleration support for custom layers, see Custom Layer Function Acceleration.
Custom Layer Properties
Declare the layer properties in the properties section of the class
definition.
By default, custom layers have these properties. Do not declare these properties in the
properties section.
| Property | Description |
|---|---|
Name | Layer name, specified as a character vector or a string scalar.
For Layer array input, the trainnet and
dlnetwork functions automatically assign
names to unnamed layers. |
Description | One-line description of the layer, specified as a string scalar or a character vector. This
description appears when you display a If you do not specify a layer description, then the software displays the layer class name. |
Type | Type of the layer, specified as a character vector or a string
scalar. The value of If you do not specify a layer type, then the software displays the layer class name. |
NumInputs | Number of inputs of the layer, specified as a positive integer. If
you do not specify this value, then the software automatically sets
NumInputs to the number of names in
InputNames. The default value is 1. |
InputNames | Input names of the layer, specified as a cell array of character
vectors. If you do not specify this value and
NumInputs is greater than 1, then the software
automatically sets InputNames to
{'in1',...,'inN'}, where N is
equal to NumInputs. The default value is
{'in'}. |
NumOutputs | Number of outputs of the layer, specified as a positive integer. If
you do not specify this value, then the software automatically sets
NumOutputs to the number of names in
OutputNames. The default value is 1. |
OutputNames | Output names of the layer, specified as a cell array of character
vectors. If you do not specify this value and
NumOutputs is greater than 1, then the software
automatically sets OutputNames to
{'out1',...,'outM'}, where M
is equal to NumOutputs. The default value is
{'out'}. |
If the layer has no other properties, then you can omit the properties
section.
Tip
If you are creating a layer with multiple inputs, then you must
set either the NumInputs or InputNames properties in the
layer constructor. If you are creating a layer with multiple outputs, then you must set either
the NumOutputs or OutputNames properties in the layer
constructor. For an example, see Define Custom Deep Learning Layer with Multiple Inputs.
Learnable Parameters
Declare the layer learnable parameters in the properties
(Learnable) section of the class definition.
You can specify numeric arrays or dlnetwork objects as learnable
parameters. If the dlnetwork object has both learnable and state
parameters (for example, a dlnetwork object that contains an LSTM
layer), then you must specify it in the properties (Learnable,
State) section. If the layer has no learnable parameters, then you can
omit the properties sections with the
Learnable attribute.
Optionally, you can specify the learning rate factor and the
L2 factor of the learnable
parameters. By default, each learnable parameter has its learning rate factor and
L2 factor set to
1. For both built-in and custom layers, you can set and get
the learning rate factors and L2
regularization factors using the following functions.
| Function | Description |
|---|---|
setLearnRateFactor | Set the learning rate factor of a learnable parameter. |
setL2Factor | Set the L2 regularization factor of a learnable parameter. |
getLearnRateFactor | Get the learning rate factor of a learnable parameter. |
getL2Factor | Get the L2 regularization factor of a learnable parameter. |
To specify the learning rate factor and the
L2 factor of a learnable parameter,
use the syntaxes layer =
setLearnRateFactor(layer,parameterName,value) and layer =
setL2Factor(layer,parameterName,value), respectively.
To get the value of the learning rate factor and the
L2 factor of a learnable
parameter, use the syntaxes
getLearnRateFactor(layer,parameterName) and
getL2Factor(layer,parameterName), respectively.
For example, this syntax sets the learning rate factor of the learnable parameter
"Alpha" to 0.1.
layer = setLearnRateFactor(layer,"Alpha",0.1);State Parameters
For stateful layers, such as recurrent layers, declare the layer state parameters
in the properties (State) section of the class definition. If the
learnable parameter is a dlnetwork object that has both learnable
and state parameters (for example, a dlnetwork object that contains
an LSTM layer), then you must specify the corresponding property in the
properties (Learnable, State) section. If the layer has no
state parameters, then you can omit the properties sections with
the State attribute.
If the layer has state parameters, then the forward functions must also return the updated layer state. For more information, see Forward Functions.
To specify a custom reset state function, include a function with syntax
layer = resetState(layer) in the class definition. For more
information, see Reset State Function.
Parallel training of networks containing custom layers with state parameters using the
trainnet function is not supported. When you train a network with
custom layers with state parameters, the ExecutionEnvironment training
option must be "auto", "gpu", or
"cpu".
Learnable and State Parameter Initialization
You can specify to initialize the layer learnable parameters and states in the
layer constructor function or in a custom initialize function:
If the learnable or state parameter initialization does not require size information from the layer input, for example, the learnable weights of a weighted addition layer is a vector with size matching the number of layer inputs, then you can initialize the weights in the layer constructor function. For an example, see Define Custom Deep Learning Layer with Multiple Inputs.
If the learnable or state parameter initialization requires size information from the layer input, for example, the learnable weights of a SReLU layer is a vector with size matching the number of channels of the input data, then you can initialize the weights in a custom initialize function that utilizes the information about the input data layout. For an example, see Define Custom Deep Learning Layer with Learnable Parameters.
Forward Functions
Some layers behave differently during training and during prediction. For example, a
dropout layer performs dropout only during training and has no effect during prediction. A
layer uses one of two functions to perform a forward pass: predict or
forward. If the forward pass is at prediction time, then the layer
uses the predict function. If the forward pass is at training time, then
the layer uses the forward function. If you do not require two different
functions for prediction time and training time, then you can omit the
forward function. When you do so, the layer uses
predict at training time.
If the layer has state parameters, then the forward functions must also return the updated layer state parameters as numeric arrays.
If you define both a custom forward function and a custom
backward function, then the forward function must return a
memory output.
The predict function syntax depends on the type of layer.
Y = predict(layer,X)forwards the input dataXthrough the layer and outputs the resultY, wherelayerhas a single input and a single output.[Y,state] = predict(layer,X)also outputs the updated state parameterstate, wherelayerhas a single state parameter.
You can adjust the syntaxes for layers with multiple inputs, multiple outputs, or multiple state parameters:
For layers with multiple inputs, replace
XwithX1,...,XN, whereNis the number of inputs. TheNumInputsproperty must matchN.For layers with multiple outputs, replace
YwithY1,...,YM, whereMis the number of outputs. TheNumOutputsproperty must matchM.For layers with multiple state parameters, replace
statewithstate1,...,stateK, whereKis the number of state parameters.
Tip
If the number of inputs to the layer can vary, then use varargin instead of X1,…,XN. In this case, varargin is a cell array of the inputs, where varargin{i} corresponds to Xi.
If the number of outputs can vary, then use varargout instead of Y1,…,YM. In this case, varargout is a cell array of the outputs, where varargout{j} corresponds to Yj.
Tip
If the custom layer has a dlnetwork object for a learnable parameter, then in
the predict function of the custom layer, use the
predict function for the dlnetwork. When you do
so, the dlnetwork object predict function uses the
appropriate layer operations for prediction. If the dlnetwork has state
parameters, then also return the network state.
The forward function syntax depends on the type of layer:
Y = forward(layer,X)forwards the input dataXthrough the layer and outputs the resultY, wherelayerhas a single input and a single output.[Y,state] = forward(layer,X)also outputs the updated state parameterstate, wherelayerhas a single state parameter.[__,memory] = forward(layer,X)also returns a memory value for a custombackwardfunction using any of the previous syntaxes. If the layer has both a customforwardfunction and a custombackwardfunction, then the forward function must return a memory value.
You can adjust the syntaxes for layers with multiple inputs, multiple outputs, or multiple state parameters:
For layers with multiple inputs, replace
XwithX1,...,XN, whereNis the number of inputs. TheNumInputsproperty must matchN.For layers with multiple outputs, replace
YwithY1,...,YM, whereMis the number of outputs. TheNumOutputsproperty must matchM.For layers with multiple state parameters, replace
statewithstate1,...,stateK, whereKis the number of state parameters.
Tip
If the number of inputs to the layer can vary, then use varargin instead of X1,…,XN. In this case, varargin is a cell array of the inputs, where varargin{i} corresponds to Xi.
If the number of outputs can vary, then use varargout instead of Y1,…,YM. In this case, varargout is a cell array of the outputs, where varargout{j} corresponds to Yj.
Tip
If the custom layer has a dlnetwork object for a learnable parameter, then in
the forward function of the custom layer, use the
forward function of the dlnetwork object. When you
do so, the dlnetwork object forward function uses the
appropriate layer operations for training.
The dimensions of the inputs depend on the type of data and the output of the connected layers.
| Layer Input | Example | |
|---|---|---|
| Shape | Data Format | |
| 2-D images |
h-by-w-by-c-by-N numeric array, where h, w, c and N are the height, width, number of channels of the images, and number of observations, respectively. | "SSCB" |
| 3-D images | h-by-w-by-d-by-c-by-N numeric array, where h, w, d, c and N are the height, width, depth, number of channels of the images, and number of image observations, respectively. | "SSSCB" |
| Vector sequences |
c-by-N-by-s matrix, where c is the number of features of the sequence, N is the number of sequence observations, and s is the sequence length. | "CBT" |
| 2-D image sequences |
h-by-w-by-c-by-N-by-s array, where h, w, and c correspond to the height, width, and number of channels of the image, respectively, N is the number of image sequence observations, and s is the sequence length. | "SSCBT" |
| 3-D image sequences |
h-by-w-by-d-by-c-by-N-by-s array, where h, w, d, and c correspond to the height, width, depth, and number of channels of the image, respectively, N is the number of image sequence observations, and s is the sequence length. | "SSSCBT" |
| Features | c-by-N array, where c is the number of features, and N is the number of observations. | "CB" |
For layers that output sequences, the layers can output sequences of any length or output data with no time dimension.
The outputs of the custom layer forward function can be
complex-valued. (since R2024a) If the layer outputs complex-valued data, then when you use
the custom layer in a neural network, you must ensure that the subsequent layers or loss
function support complex-valued input. Using complex numbers in the
predict or forward functions of your
custom layer can lead to complex learnable parameters. To train models with
complex-valued learnable parameters, use the trainnet function with
the "sgdm", "adam", or
"rmsprop" solvers, by specifying them using the
trainingOptions function, or use a custom training loop with
the sgdmupdate, adamupdate, or
rmspropupdate functions.
Before R2024a: The outputs of the custom layer forward
functions must not be complex. If the predict or
forward functions of your custom layer involve complex numbers,
convert all outputs to real values before returning them. Using complex numbers in the
predict or forward functions of your
custom layer can lead to complex learnable parameters. If you are using automatic
differentiation (in other words, you are not writing a backward function for your custom
layer) then convert all the learnable parameters to real values at the beginning of the
function computation. Doing so ensures that the automatic differentiation algorithm does
not output complex-valued gradients.
Reset State Function
The resetState function for dlnetwork objects, by
default, has no effect on custom layers with state parameters. To define the layer behavior
for the resetState function for network objects, define the optional
layer resetState function in the layer definition that resets the state
parameters.
The resetState function must have the syntax layer =
resetState(layer), where the returned layer has the reset state
properties.
The resetState function must not
set any layer properties except for learnable and state properties. If the function sets
other layers properties, then the layer can behave unexpectedly. (since R2023a)
Backward Function
The layer backward function computes the derivatives of the loss with respect to the
input data and then outputs (backward propagates) results to the previous layer. If the
layer has learnable parameters (for example, layer weights), then
backward also computes the derivatives of the loss with respect
to the learnable parameters. When you use the trainnet function,
the layer automatically updates the learnable parameters using these derivatives during
the backward pass.
Defining the backward function is optional. If you do not specify a backward function,
and the layer forward functions support dlarray objects, then the
software automatically determines the backward function using automatic differentiation.
For a list of functions that support dlarray objects, see List of Functions with dlarray Support. Define a custom
backward function when you want to:
Use a specific algorithm to compute the derivatives.
Use operations in the forward functions that do not support
dlarrayobjects.
Custom layers with learnable dlnetwork objects do not support custom backward functions.
To define a custom backward function, create a function named
backward.
The backward function syntax depends on the type of layer.
dLdX = backward(layer,X,Y,dLdY,memory)returns the derivativesdLdXof the loss with respect to the layer input, wherelayerhas a single input and a single output.Ycorresponds to the forward function output anddLdYcorresponds to the derivative of the loss with respect toY. The function inputmemorycorresponds to the memory output of the forward function.[dLdX,dLdW] = backward(layer,X,Y,dLdY,memory)also returns the derivativedLdWof the loss with respect to the learnable parameter, wherelayerhas a single learnable parameter.[dLdX,dLdSin] = backward(layer,X,Y,dLdY,dLdSout,memory)also returns the derivativedLdSinof the loss with respect to the state input, wherelayerhas a single state parameter anddLdSoutcorresponds to the derivative of the loss with respect to the layer state output.[dLdX,dLdW,dLdSin] = backward(layer,X,Y,dLdY,dLdSout,memory)also returns the derivativedLdWof the loss with respect to the learnable parameter and returns the derivativedLdSinof the loss with respect to the layer state input, wherelayerhas a single state parameter and single learnable parameter.
You can adjust the syntaxes for layers with multiple inputs, multiple outputs, multiple learnable parameters, or multiple state parameters:
For layers with multiple inputs, replace
XanddLdXwithX1,...,XNanddLdX1,...,dLdXN, respectively, whereNis the number of inputs.For layers with multiple outputs, replace
YanddLdYwithY1,...,YManddLdY1,...,dLdYM, respectively, whereMis the number of outputs.For layers with multiple learnable parameters, replace
dLdWwithdLdW1,...,dLdWP, wherePis the number of learnable parameters.For layers with multiple state parameters, replace
dLdSinanddLdSoutwithdLdSin1,...,dLdSinKanddLdSout1,...,dLdSoutK, respectively, whereKis the number of state parameters.
To reduce memory usage by preventing unused variables being saved between the forward and
backward pass, replace the corresponding input arguments with ~.
Tip
If the number of inputs to backward can vary, then use
varargin instead of the input arguments after
layer. In this case, varargin is a cell array
of the inputs, where the first N elements correspond to the
N layer inputs, the next M elements correspond
to the M layer outputs, the next M elements
correspond to the derivatives of the loss with respect to the M layer
outputs, the next K elements correspond to the K
derivatives of the loss with respect to the K state outputs, and the
last element corresponds to memory.
If the number of outputs can vary, then use varargout instead of the
output arguments. In this case, varargout is a cell array of the
outputs, where the first N elements correspond to the
N the derivatives of the loss with respect to the
N layer inputs, the next P elements correspond
to the derivatives of the loss with respect to the P learnable
parameters, and the next K elements correspond to the derivatives of
the loss with respect to the K state inputs.
The values of X and Y are the same as in the
forward functions. The dimensions of dLdY are the same as the
dimensions of Y.
The dimensions and data type of dLdX are the same as the dimensions
and data type of X. The dimensions and data types of
dLdW are the same as the dimensions and data types of
W.
To calculate the derivatives of the loss with respect to the input data, you can use the chain rule with the derivatives of the loss with respect to the output data and the derivatives of the output data with respect to the input data.:
When you use the trainnet function, the layer automatically
updates the learnable parameters using the derivatives dLdW during
the backward pass.
For an example showing how to define a custom backward function, see Specify Custom Layer Backward Function.
The outputs of the custom layer backward function can be
complex-valued. (since R2024a) Using complex valued gradients can lead to complex
learnable parameters. To train models with complex-valued learnable parameters, use the
trainnet function with the "sgdm",
"adam", or "rmsprop" solvers, by specifying
them using the trainingOptions function, or use a custom training
loop with the sgdmupdate, adamupdate, or
rmspropupdate functions.
Before R2024a: The outputs of the custom layer backward function must not be complex. If your backward function involves complex numbers, then convert all outputs of the backward function to real values before returning them.
GPU Compatibility
If the layer forward functions fully support dlarray objects, then the layer
is GPU compatible. Otherwise, to be GPU compatible, the layer functions must support inputs
and return outputs of type gpuArray (Parallel Computing Toolbox).
Many MATLAB® built-in functions support gpuArray (Parallel Computing Toolbox) and dlarray input arguments. For a list of
functions that support dlarray objects, see List of Functions with dlarray Support. For a list of functions
that execute on a GPU, see Run MATLAB Functions on a GPU (Parallel Computing Toolbox). To use a GPU for deep
learning, you must also have a supported GPU device. For information on supported devices, see
GPU Computing Requirements (Parallel Computing Toolbox). For more information on working with GPUs in MATLAB, see GPU Computing in MATLAB (Parallel Computing Toolbox).
Code Generation Compatibility
You must specify the pragma %#codegen in the layer definition to create
a custom layer for code generation. Code generation does not support custom layers with
state properties (properties with attribute State).
In addition, when generating code that uses third-party libraries:
Code generation supports custom layers with 2-D image or feature input only.
The inputs and output of the layer forward functions must have the same batch size.
Nonscalar properties must be a single, double, or character array.
Scalar properties must have type numeric, logical, or string.
For an example showing how to create a custom layer that supports code generation, see Define Custom Deep Learning Layer for Code Generation.
Network Composition
To create a custom layer that itself defines a neural network, you can declare a
dlnetwork object as a learnable parameter in the properties
(Learnable) section of the layer definition. This method is known as
network composition. You can use network composition to:
Create a network with control flow, for example, a network with a section that can dynamically change depending on the input data.
Create a network with loops, for example, a network with sections that feed the output back into itself.
Implement weight sharing, for example, in networks where different data needs to pass through the same layers such as twin neural networks or generative adversarial networks (GANs).
For nested networks that have both learnable and state parameters, for example, networks
with batch normalization or LSTM layers, declare the network in the properties
(Learnable, State) section of the layer definition.
Check Validity of Layer
If you create a custom deep learning layer, then you can use
the checkLayer function
to check that the layer is valid. The function checks layers for validity, GPU compatibility,
correctly defined gradients, and code generation compatibility. To check that a layer is valid,
run the following
command:
checkLayer(layer,layout)
layer is
an instance of the layer and layout is a networkDataLayout
object specifying the valid sizes and data formats for inputs to the layer. To check with
multiple observations, use the ObservationDimension option. To run the check for code generation compatibility,
set the CheckCodegenCompatibility option to 1
(true). For large input sizes, the gradient checks take longer to run.
To speed up the check, specify a smaller valid input size.For more information, see Check Custom Layer Validity.
Check Validity of Custom Layer Using checkLayer
Check the layer validity of the custom layer sreluLayer.
The custom layer sreluLayer, attached to this example as a supporting file, applies the SReLU operation to the input data. To access this layer, open this example as a live script.
Create an instance of the layer.
layer = sreluLayer;
Create a networkDataLayout object that specifies the expected input size and format of typical input to the layer. Specify a valid input size of [24 24 20 128], where the dimensions correspond to the height, width, number of channels, and number of observations of the previous layer output. Specify the format as "SSCB" (spatial, spatial, channel, batch).
validInputSize = [24 24 20 128];
layout = networkDataLayout(validInputSize,"SSCB");Check the layer validity using checkLayer.
checkLayer(layer,layout)
Skipping GPU tests. No compatible GPU device found. Skipping code generation compatibility tests. To check validity of the layer for code generation, specify the CheckCodegenCompatibility and ObservationDimension options. Running nnet.checklayer.TestLayerWithoutBackward .......... .......... Done nnet.checklayer.TestLayerWithoutBackward __________ Test Summary: 20 Passed, 0 Failed, 0 Incomplete, 14 Skipped. Time elapsed: 0.14174 seconds.
The function does not detect any issues with the layer.
See Also
trainnet | trainingOptions | dlnetwork | functionLayer | checkLayer | setLearnRateFactor | setL2Factor | getLearnRateFactor | getL2Factor | findPlaceholderLayers | replaceLayer | PlaceholderLayer | networkDataLayout
Topics
- Define Custom Deep Learning Layer with Learnable Parameters
- Define Custom Deep Learning Layer with Multiple Inputs
- Define Custom Deep Learning Layer with Formatted Inputs
- Define Custom Recurrent Deep Learning Layer
- Specify Custom Layer Backward Function
- Define Custom Deep Learning Layer for Code Generation
- Deep Learning Network Composition
- Define Nested Deep Learning Layer Using Network Composition
- Check Custom Layer Validity