Fuzzy C-Means Clustering
Clustering of numerical data forms the basis of many classification and system-modeling algorithms. The purpose of clustering is to identify natural groupings of data from a large data set to produce a concise representation of system behavior. Fuzzy Logic Toolbox™ tools allow you to find clusters in input-output training data using fuzzy c-means clustering.
Fuzzy c-means (FCM) is a data clustering technique where each data point belongs to a cluster to a degree that is specified by a membership grade. [1]
The FCM algorithm starts with an initial guess for the cluster centers, which represent the mean location of each cluster. The initial guess for these cluster centers is most likely incorrect. Additionally, FCM assigns every data point a membership grade for each cluster using a partition matrix. By iteratively updating the cluster centers and the membership grades for each data point, the algorithm moves the cluster centers to the optimal location within a data set. This iteration is based on minimizing an objective function that represents the distance from any given data point to a cluster center weighted by the data point membership grade.
To cluster data using FCM clustering, use the fcm function. To specify the clustering algorithm options, use an
fcmOptions
object. The fcm function outputs a list of cluster centers and
cluster membership grades for each data point.
To interactively cluster data without writing code, use the FCM Data Clustering task in the Live Editor. (since R2025a)
You can use cluster information to generate a fuzzy inference system that best models
the data behavior using a minimum number of rules. The rules partition themselves
according to the fuzzy qualities associated with each of the data clusters. To
automatically generate this type of FIS, use the genfis function. You can generate an initial fuzzy system using
clustering results from either FCM or subtractive clustering.
FCM Algorithm
To cluster data, specify an N-by-d array of data points. Each row xj contains one data point and the number of columns is equal to the data dimensionality.
The FCM algorithm computes the cluster centers, ci. This array contains one row for each cluster center and the number of columns is equal to the data dimensionality, d.
To specify the number of clusters C, use the
NumClusters option. If you do not know the number of
clusters in your data, you can set NumClusters to
"auto". When you do so, the fcm function
clusters the data ten times (C = 2 through 11) and returns the
results for the optimal cluster count. Alternatively, you can estimate the number of
clusters in your data using the subclust function.
In the following FCM algorithm description:
m is the fuzzy partition matrix exponent for controlling the degree of fuzzy overlap, with m > 1. Fuzzy overlap refers to how fuzzy the boundaries between clusters are, that is, the number of data points that have significant membership in more than one cluster. To specify the fuzzy partition matrix exponent, use the
Exponentoption.μij is the degree of membership of the jth data point in the ith cluster. You can select one of two supported cluster membership types using the
ClusterMembershipTypeoption. For more information, see Membership Type.Dij is the distance from the jth data point to the ith cluster. You can select one of three supported distance metrics using the
DistanceMetricoption. For more information, see Distance Metric.
FCM clustering performs these steps:
Set the initial fuzzy partition matrix, which defines the cluster membership values μij. By default, the initial membership values are random. You can specify initial membership values using the
PartitionMatrixoption.Calculate the cluster centers ci.
If you specify initial cluster centers using the
ClusterCentersoption, the software uses your specified cluster centers for the first clustering iteration and skips the preceding calculation.Compute the distance Dij to each cluster center for each data point based on the specified distance metric.
Calculate the objective function Jm, which depends on the cluster membership type.
Update the cluster membership values μij for each data point based on the specified cluster membership type.
Repeat steps 2–5 until one of these conditions is met:
Jm improves by less than a specified minimum threshold, which you specify using the
MinImprovementoption.The algorithm performs the specified maximum number of iterations, which you specify using the
MaxNumIterationoption.
Once clustering is complete, you can view the clustering results using the
plotFuzzyClusters function.
Membership Type
You can select one of two supported cluster membership definitions by setting the
ClusterMembershipType option.
| Membership Type | ClusterMembershipType Value | Description |
|---|---|---|
Probabilistic membership (default) | "probabilistic" | For a given data point, the sum of membership values across all clusters is equal to 1, reflecting a degree of probability. This method is suitable for situations where data points are expected to belong to clusters in a probabilistic manner. |
Possibilistic membership (since R2026a) | "possibilistic" | For a given data point, each cluster membership value is independent, reflecting the degree of possibility rather than probability. This method is more suitable for handling noise and outliers. [2] |
Probabilistic Membership
When you select the probabilistic cluster membership type, the sum of membership values across all clusters for each data point is equal to one. As a result, the membership values are interpreted as probabilities, indicating the likelihood that a data point belongs to each cluster.
When using the probabilistic membership type, the FCM algorithm updates membership values μij in the partition matrix using the following formula.
The probabilistic FCM algorithm minimizes the following objective function, which is the weighted sum of squared distances from the data points to the cluster centers.
Possibilistic Membership
Since R2026a
When you select the possibilistic cluster membership type, the sum of membership values across all clusters for each data point is not constrained to be one. Instead, each membership value is independent, reflecting the degree of possibility rather than probability. This method is more suitable for handling noise and outliers, as it allows for more flexible membership assignments and can better represent the inherent vagueness and uncertainty in data.
During the first clustering iteration, after computing the cluster centers, the possibilistic FCM algorithm estimates normalization factor ηij, which is proportional to the average fuzzy intra-cluster distance.
The possibilistic FCM algorithm updates membership values μij in the partition matrix using the following formula.
For possibilistic membership values, the FCM algorithm minimizes the following objective function. The first term of the objective function minimizes the distance from the data points to the cluster centers and matches the objective function for probabilistic membership. The second term forces the membership values to be as large as possible.
Distance Metric
You can select one of three supported algorithms for computing the distance from
each data point to each cluster center by setting the
DistanceMetric option.
| FCM Algorithm | DistanceMetric Value | Description |
|---|---|---|
Classical FCM (default) | "euclidean" | Compute distances using the Euclidean distance norm, which assumes a spherical shape for all clusters. [1] |
Gustafson-Kessel FCM (since R2023a) | "mahalanobis" | Compute distances using a Mahalanobis distance norm, where cluster covariance is weighted by cluster membership values. This method is useful for detecting nonspherical clusters. [3] |
Gath-Geva FCM (since R2023b) | "fmle" | Compute distances using an exponential distance measure based on fuzzy maximum likelihood estimation. This method is useful for detecting nonshperical clusters in the presence of variable cluster densities and unequal numbers of data points in each cluster. [4] |
Classical FCM Distance Calculation
The classical FCM algorithm computes the Euclidean distance from each data point to each cluster center, as shown in the following equation.
Gustafson-Kessel Distance Calculation
Since R2023a
The Gustafson-Kessel FCM algorithm first computes covariance matrices Fi for each cluster center.
Then, it computes the Mahalanobis distance from each data point to each cluster using the covariance matrices.
Gath-Geva Distance Calculation
Since R2023b
The Gath-Geva FCM algorithm first computes covariance matrices Fi for each cluster center.
Then, it computes the prior probability for selecting each cluster [6].
Finally, it computes the distance from each data point to each cluster using an exponential distance measure.
Cluster Data Using FCM
This example shows how to perform fuzzy c-means clustering on 2-dimensional data using the fcm function. For an example that clusters higher-dimensional data, see Fuzzy C-Means Clustering for Iris Data.
To interactively cluster data using FCM clustering, use the FCM Data Clustering task.
Load Data
Load the five sample data sets, and select a data set to cluster. These data sets have different numbers of clusters and data distributions.
load fcmdata dataset =fcmdata3;
Each data set contains two columns, which represent the two features for each data point.
Specify FCM Settings
Configure the clustering algorithm settings. For more information on these settings, see fcmOptions. To obtain accurate clustering results for each data set, try different clustering options.
Specify the number of clusters to compute, which must be greater than 1. When Nc is auto, the fcm function clusters the data for multiple cluster counts (2 through 11) and returns the results for the optimal number of clusters.
Nc =  "auto";
"auto";Specify the exponent of the fuzzy partition matrix, which controls the degree of fuzzy overlap between clusters. This value must be greater than 1, with smaller values creating more crisp cluster boundaries. For more information, see Adjust Fuzzy Overlap in Fuzzy C-Means Clustering.
exponent =  2;
2;Specify the maximum number of optimization iterations.
maxIter =  100;
100;Specify the minimum improvement in the objective function between successive iterations. When the objective function improves by a value below this threshold, the optimization stops. A smaller value produces more accurate clustering results, but the clustering can take longer to converge.
minImprove =  0.00001;
0.00001;Specify whether to display the objective function value after each iteration.
displayObjective =  false;
false;Specify the distance metric to use during computation. You can select either a Euclidean, Mahalanobis, or fuzzy maximum likelihood estimate distance metric.
distMetric =  "euclidean";
"euclidean";Create an fcmOptions object using these settings.
options = fcmOptions( ... NumClusters=Nc, ... Exponent=exponent, ... MaxNumIteration=maxIter ,... MinImprovement=minImprove ,... Verbose=displayObjective, ... DistanceMetric=distMetric);
Cluster Data
Cluster the data into the specified number of clusters.
[C,U,objFun,info] = fcm(dataset,options);
C contains the computed centers for each cluster. U contains the computed fuzzy partition matrix, which indicates the degree of membership of each data point within each cluster.
If Nc is auto, then C and U contain the clustering results for the optimal number of clusters. The full clustering results are returned in info.
Plot Clustering Results
Specify whether to plot the cluster membership profiles on diagonal axes in the plot. When you decrease the exponent value, the transition from maximum full cluster membership to zero cluster membership becomes more steep; that is, the cluster boundary becomes more crisp.
plotMembership =  true;
true;Select the type of plot. You can select either a scatter plot or a surface plot.
plotType =  "scatter";
"scatter";Plot the clustered data along with the cluster centers.
figure plotFuzzyClusters(dataset,U, ... ClusterCenters=C, ... ShowMembershipPlot=plotMembership, ... PlotType=plotType)
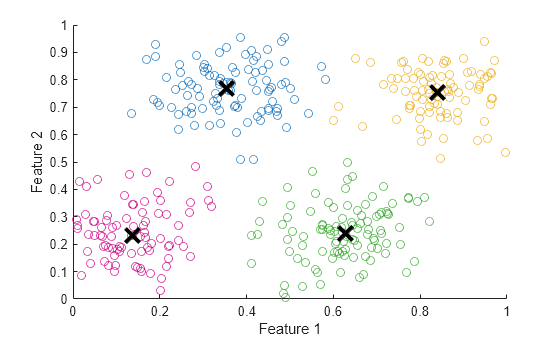
The data points in each cluster are shown in different colors in the nondiagonal plot. The center for each cluster is shown as a diamond.
The diagonal plots show the cluster membership profile for each feature.
References
[1] Bezdek, James C. Pattern Recognition with Fuzzy Objective Function Algorithms. Boston, MA: Springer US, 1981. https://doi.org/10.1007/978-1-4757-0450-1.
[2] Krishnapuram, R., and J.M. Keller. “A Possibilistic Approach to Clustering.” IEEE Transactions on Fuzzy Systems 1, no. 2 (May 1993): 98–110. https://doi.org/10.1109/91.227387.
[3] Gustafson, Donald, and William Kessel. “Fuzzy Clustering with a Fuzzy Covariance Matrix.” In 1978 IEEE Conference on Decision and Control Including the 17th Symposium on Adaptive Processes, 761–66. San Diego, CA, USA: IEEE, 1978. https://doi.org/10.1109/CDC.1978.268028.
[4] Gath, I., and A.B. Geva. “Unsupervised Optimal Fuzzy Clustering.” IEEE Transactions on Pattern Analysis and Machine Intelligence 11, no. 7 (July 1989): 773–80. https://doi.org/10.1109/34.192473.
[5] Höppner, Frank, ed. Fuzzy Cluster Analysis: Methods for Classification, Data Analysis, and Image Recognition. Chichester ; New York: J. Wiley, 1999: 49–53.
See Also
Functions
fcm|fcmOptions|subclust|genfis