Incremental Learning Overview
What Is Incremental Learning?
Incremental learning, or online learning, is a branch of machine learning that involves processing incoming data from a data stream—continuously and in real time—possibly given little to no knowledge of the distribution of the predictor variables, sample size, aspects of the prediction or objective function (including adequate tuning parameter values), and whether the observations have labels. Other types of incremental learning involve:
Training a model and detecting anomalies in an incoming data stream (see Incremental Anomaly Detection Overview)
Centering and scaling data in an incoming data stream (see
incrementalNormalizer)Computing principal component coefficients for data in an incoming stream (see
incrementalPCA)
Incremental learning algorithms are flexible, efficient, and adaptive. The following characteristics distinguish incremental learning from traditional machine learning:
An incremental model is fit to data quickly and efficiently, which means it can adapt, in real time, to changes (or drifts) in the data distribution.
Because observation labels can be missing when corresponding predictor data is available, the algorithm must be able to generate predictions from the latest version of the model quickly, and defer training the model.
Little information might be known about the population before incremental learning starts. Therefore, the algorithm can be run with a cold start. For example, for classification problems, the class names might not be known until after the model processes observations. When enough information is known before learning begins (for example, you have good estimates of linear model coefficients), you can specify such information to provide the model with a warm start.
Because observations can arrive in a stream, the sample size is likely unknown and possibly large, which makes data storage inefficient or impossible. Therefore, the algorithm must process observations when they are available and before the system discards them. This incremental learning characteristic makes hyperparameter tuning difficult or impossible.
In traditional machine learning, a batch of labeled data is available to perform cross-validation to estimate the generalization error and tune hyperparameters, infer the predictor variable distribution, and fit the model. However, the resulting model must be retrained from the beginning if underlying distributions drift or the model degrades. Although performing cross-validation to tune hyperparameters is difficult in an incremental learning environment, incremental learning methods are flexible because they can adapt to distribution drift in real time, with predictive accuracy approaching that of a traditionally trained model as the model trains more data.
Suppose an incremental model is prepared to generate predictions and have its predictive performance measured. Given incoming chunks of observations, an incremental learning scheme processes data in real time and in any of the following ways, but usually in the specified order:
Evaluate model: Track the predictive performance of the model when true labels are available, either on the incoming data only, over a sliding window of observations, or over the entire history of the model used for incremental learning.
Detect drift: Check for structural breaks or distribution drift. For example, determine whether the distribution of any predictor variable has sufficiently changed.
Train model: Update the model by training it on the incoming observations, when true labels are available or when the current model has sufficiently degraded.
Generate predictions: Predict labels from the latest model.
This procedure is a special case of incremental learning, in which all incoming chunks are treated as test (holdout) sets. The procedure is called interleaved test-then-train or prequential evaluation [1].
If insufficient information exists for an incremental model to generate predictions, or you do not want to track the predictive performance of the model because it has not been trained enough, you can include an optional initial step to find adequate values for hyperparameters, for models that support one (estimation period), or an initial training period before model evaluation (metrics warm-up period).
As an example of an incremental learning problem, consider a smart thermostat that automatically sets a temperature given the ambient temperature, relative humidity, time of day, and other measurements, and can learn the user's indoor temperature preferences. Suppose the manufacturer prepared the device by embedding a known model that describes the average person's preferences given the measurements. After installation, the device collects data every minute, and adjusts the temperature to its presets. The thermostat adjusts the embedded model, or retrains itself, based on the user's actions or inactions with the device. This cycle can continue indefinitely. If the thermostat has limited disk space to store historical data, it needs to retrain itself in real time. If the manufacturer did not prepare the device with a known model, the device retrains itself more often.
Incremental Learning with MATLAB
Statistics and Machine Learning Toolbox™ functionalities enable you to implement incremental learning for classification or regression. Like other Statistics and Machine Learning Toolbox machine learning functionalities, the entry point into incremental learning is an incremental learning object, which you pass to functions with data to implement incremental learning. Unlike other machine learning functions, data is not required to create an incremental learning object. However, the incremental learning object specifies how to process incoming data, such as when to fit the model, measure performance metrics, or perform both actions, in addition to the parametric form of the model and problem-specific options.
Incremental Learning Model Objects
This table contains the available entry-point model objects for incremental learning with their supported machine learning objective, model type, and information required to create the model object.
| Model Object | Objective | Model Type | Required Information |
|---|---|---|---|
incrementalClassificationECOC | Multiclass classification | Error-correcting output codes (ECOC) model with binary learners | Maximum number of classes expected in the data during incremental learning or the names of all expected classes |
incrementalClassificationKernel | Binary classification | Binary Gaussian kernel classifier | None |
incrementalClassificationLinear | Binary classification | Linear SVM and logistic regression | None |
incrementalClassificationNaiveBayes | Multiclass classification | Naive Bayes with normal, multinomial, or multivariate multinomial predictor conditional distributions | Maximum number of classes expected in the data during incremental learning or the names of all expected classes |
incrementalRegressionKernel | Regression | SVM and least-squares regression with Gaussian kernels | None |
incrementalRegressionLinear | Regression | Linear SVM and least-squares regression | None |
Properties of an incremental learning model object specify:
Data characteristics, such as the number of predictor variables
NumPredictorsand their first and second momentsModel characteristics, such as, for linear models, the learner type
Learner, linear coefficientsBeta, and interceptBiasTraining options, such as, for linear models, the objective solver
Solverand solver-specific hyperparameters such as the ridge penaltyLambdafor standard and average stochastic gradient descent (SGD and ASGD)Model performance evaluation characteristics and options, such as whether the model is warm
IsWarm, which performance metrics to trackMetrics, and the latest values of the performance metrics
Unlike when working with other machine learning model objects, you can create an incremental learning model by directly calling the object and specifying property values of options using name-value arguments; you do not need to fit a model to data to create one. This feature is convenient when you have little information about the data or model before training it. Depending on your specifications, the software can enforce estimation and metrics warm-up periods, during which incremental fitting functions infer data characteristics and then train the model for performance evaluation. By default, for linear models, the software solves the objective function using the adaptive scale-invariant solver, which does not require tuning and is insensitive to the predictor variable scales [2].
Alternatively, you can convert a traditionally trained model to a model for
incremental learning by using the incrementalLearner function. For
example, incrementalLearner converts a trained linear classification model of type
ClassificationLinear to an incrementalClassificationLinear
object. This table lists the convertible models and their conversion
functions.
By default, the software considers converted models to be prepared for all aspects of
incremental learning (converted models are warm). incrementalLearner
carries over data characteristics (such as class names), fitted parameters, and options
available for incremental learning from the traditionally trained model being converted.
For example:
For naive Bayes classification,
incrementalLearnercarries over all class names in the data expected during incremental learning, and the fitted moments of the conditional predictor distributions (DistributionParameters).For linear models, if the objective solver of the traditionally trained model is SGD,
incrementalLearnersets the incremental learning solver to SGD.
For more details, see the output argument description of each
incrementalLearner function page.
Incremental Learning Functions
The incremental learning model object specifies all aspects of the incremental learning algorithm, from training and model evaluation preparation through training and model evaluation. To implement incremental learning, you pass the configured incremental learning model to an incremental fitting function or model evaluation function. You can find the list of supported incremental learning functions in the Object Functions section of each incremental learning model object page.
Statistics and Machine Learning Toolbox incremental learning functions offer two workflows that are well suited for prequential learning. For simplicity, the following workflow descriptions assume that the model is prepared to evaluate the model performance (in other words, the model is warm).
Flexible workflow — When a data chunk is available:
Compute cumulative and window model performance metrics by passing the data and current model to the
updateMetricsfunction. The data is treated as test (holdout) data because the model has not been trained on it yet.updateMetricsoverwrites the model performance stored in the model with the new values.Optionally detect distribution drift or whether the model has degraded.
Train the model by passing the incoming data chunk and current model to the
fitfunction. Thefitfunction uses the specified solver to fit the model to the incoming data chunk, and overwrites the current coefficients and bias with the new estimates.
The flexible workflow enables you to perform custom model and data quality assessments before deciding whether to train the model. All steps are optional, but call
updateMetricsbeforefitwhen you plan to call both functions.Succinct workflow — When a data chunk is available, supply the incoming chunk and a configured incremental model to the
updateMetricsAndFitfunction.updateMetricsAndFitcallsupdateMetricsimmediately followed byfit. The succinct workflow enables you to implement incremental learning with prequential evaluation easily when you plan to track the model performance and train the model on all incoming data chunks.
Once you create an incremental model object and choose a workflow to use, write a loop that implements incremental learning:
Read a chunk of observations from a data stream, when the chunk is available.
Implement the flexible or succinct workflow. To perform incremental learning properly, overwrite the input model with the output model. For example:
Flexible workflow
Mdl = updateMetrics(Mdl,X,Y); % % Insert optional code % Mdl = fit(Mdl,X,Y);
Succinct workflow
Mdl = updateMetricsAndFit(Mdl,X,Y);
The model tracks its performance on incoming data incrementally using metrics measured since the beginning of training (cumulative) and over a specified window of consecutive observations (window). However, you can optionally compute the model loss on the incoming chunk, and then pass the incoming chunk and current model to the
lossfunction.lossreturns the scalar loss; it does not adjust the model.Model configurations determine whether incremental learning functions train or evaluate model performance during each iteration. Configurations can change as the functions process data. For more details, see Incremental Learning Periods.
Optionally:
Generate predictions by passing the chunk and latest model to
predict.If the model was fit to data, compute the resubstitution loss by passing the chunk and latest model to
loss.For naive Bayes classification models, the
logpfunction enables you to detect outliers in real-time. The function returns the log unconditional probability density of the predictor variables at each observation in the chunk.
Incremental Learning Periods
Given incoming chunks of data, the actions performed by incremental learning functions depend on the current configuration or state of the model. This figure shows the periods (consecutive groups of observations) during which incremental learning functions perform particular actions.
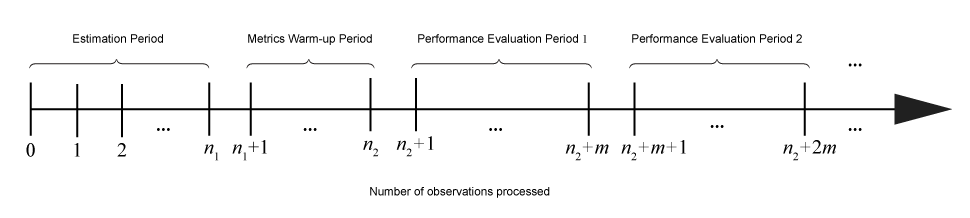
This table describes the actions performed by incremental learning functions during each period.
| Period | Associated Model Properties | Size (Number of Observations) | Actions |
|---|---|---|---|
| Estimation | EstimationPeriod, applies to linear classification, kernel
classification, linear regression, and kernel regression models only | n1 | When required, fitting functions choose values for hyperparameters based on estimation period observations. Actions can include the following:
For more details, see the Algorithms section of each object and
|
| Metrics Warm-up | MetricsWarmupPeriod | n2 – n1 | When the property
|
| Performance Evaluation | Metrics and MetricsWindowSize | m | Functions store information buffers required for computing model performance. At the end of each Performance Evaluation Period:
|
References
See Also
Objects
incrementalClassificationLinear|incrementalRegressionLinear|incrementalClassificationNaiveBayes|incrementalClassificationKernel|incrementalRegressionKernel|incrementalClassificationECOC