icdf
Inverse cumulative distribution function
Syntax
Description
Examples
Compute the icdf values for a normal distribution by specifying the distribution name 'Normal' and the distribution parameters.
Define the input vector p to contain the probability values at which to calculate the icdf.
p = [0.1,0.25,0.5,0.75,0.9];
Compute the icdf values for the normal distribution with the mean equal to 1 and the standard deviation equal to 5.
mu = 1;
sigma = 5;
y = icdf('Normal',p,mu,sigma)y = 1×5
-5.4078 -2.3724 1.0000 4.3724 7.4078
Each value in y corresponds to a value in the input vector x. For example, at the value x equal to 1, the corresponding icdf value y is equal to 7.4078.
Create a normal distribution object and compute the icdf values of the normal distribution using the object.
Create a normal distribution object with the mean equal to 1 and the standard deviation equal to 5.
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
Define the input vector p to contain the probability values at which to calculate the icdf.
p = [0.1,0.25,0.5,0.75,0.9];
Compute the icdf values for the normal distribution at the values in p.
x = icdf(pd,p)
x = 1×5
-5.4078 -2.3724 1.0000 4.3724 7.4078
Each value in x corresponds to a value in the input vector p. For example, at the value p equal to 0.9, the corresponding icdf value x is equal to 7.4078.
Create a Poisson distribution object with the rate parameter, , equal to 2.
lambda = 2; pd = makedist('Poisson','lambda',lambda);
Define the input vector p to contain the probability values at which to calculate the icdf.
p = [0.1,0.25,0.5,0.75,0.9];
Compute the icdf values for the Poisson distribution at the values in p.
x = icdf(pd,p)
x = 1×5
0 1 2 3 4
Each value in x corresponds to a value in the input vector p. For example, at the value p equal to 0.9, the corresponding icdf value x is equal to 4.
Alternatively, you can compute the same icdf values without creating a probability distribution object. Use the icdf function and specify a Poisson distribution using the same value for the rate parameter .
x2 = icdf('Poisson',p,lambda)x2 = 1×5
0 1 2 3 4
The icdf values are the same as those computed using the probability distribution object.
Create a standard normal distribution object.
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
Determine the critical values at the 5% significance level for a test statistic with a standard normal distribution, by computing the upper and lower 2.5% values.
x = icdf(pd,[.025,.975])
x = 1×2
-1.9600 1.9600
Plot the cdf and shade the critical regions.
p = normspec(x,0,1,'outside')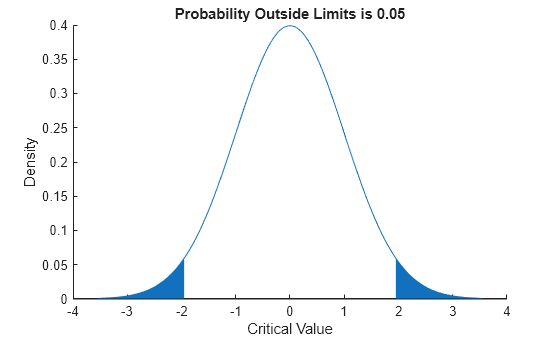
p = 0.0500
Input Arguments
Output Arguments
Alternative Functionality
icdf is a generic function that accepts either a distribution by
its name name or a probability distribution object
pd. It is faster to use a distribution-specific function, such
as norminv for the normal distribution and
binoinv for the binomial distribution.
For a list of distribution-specific functions, see Supported Distributions.
Extended Capabilities
Version History
Introduced before R2006a
See Also
cdf | mle | pdf | random | makedist | fitdist | Distribution Fitter | paretotails