trainNetwork
(Not recommended) Train neural network
trainNetwork is not recommended. Use the trainnet
function instead. For more information, see Version
History.
Syntax
Description
Examples
Train a deep learning LSTM network for sequence-to-label classification.
Load the example data from WaveformData.mat. The data
is a numObservations-by-1 cell array of sequences, where
numObservations is the number of sequences. Each
sequence is a
numChannels-by-numTimeSteps
numeric array, where numChannels is the number of
channels of the sequence and numTimeSteps is the number
of time steps of the sequence.
load WaveformDataVisualize some of the sequences in a plot.
numChannels = size(data{1},1);
idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4
nexttile
stackedplot(data{idx(i)}', ...
DisplayLabels="Channel " + string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))
end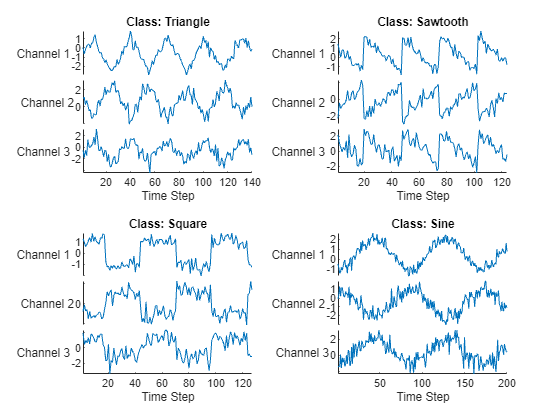
Set aside data for testing. Partition the data into a training set
containing 90% of the data and a test set containing the remaining 10% of
the data. To partition the data, use the
trainingPartitions function, attached to this example
as a supporting file. To access this file, open the example as a live
script.
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations, [0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain); XTest = data(idxTest); TTest = labels(idxTest);
Define the LSTM network architecture. Specify the input size as the number of channels of the input data. Specify an LSTM layer to have 120 hidden units and to output the last element of the sequence. Finally, include a fully connected with an output size that matches the number of classes, followed by a softmax layer and a classification layer.
numHiddenUnits = 120; numClasses = numel(categories(TTrain)); layers = [ ... sequenceInputLayer(numChannels) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' LSTM LSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
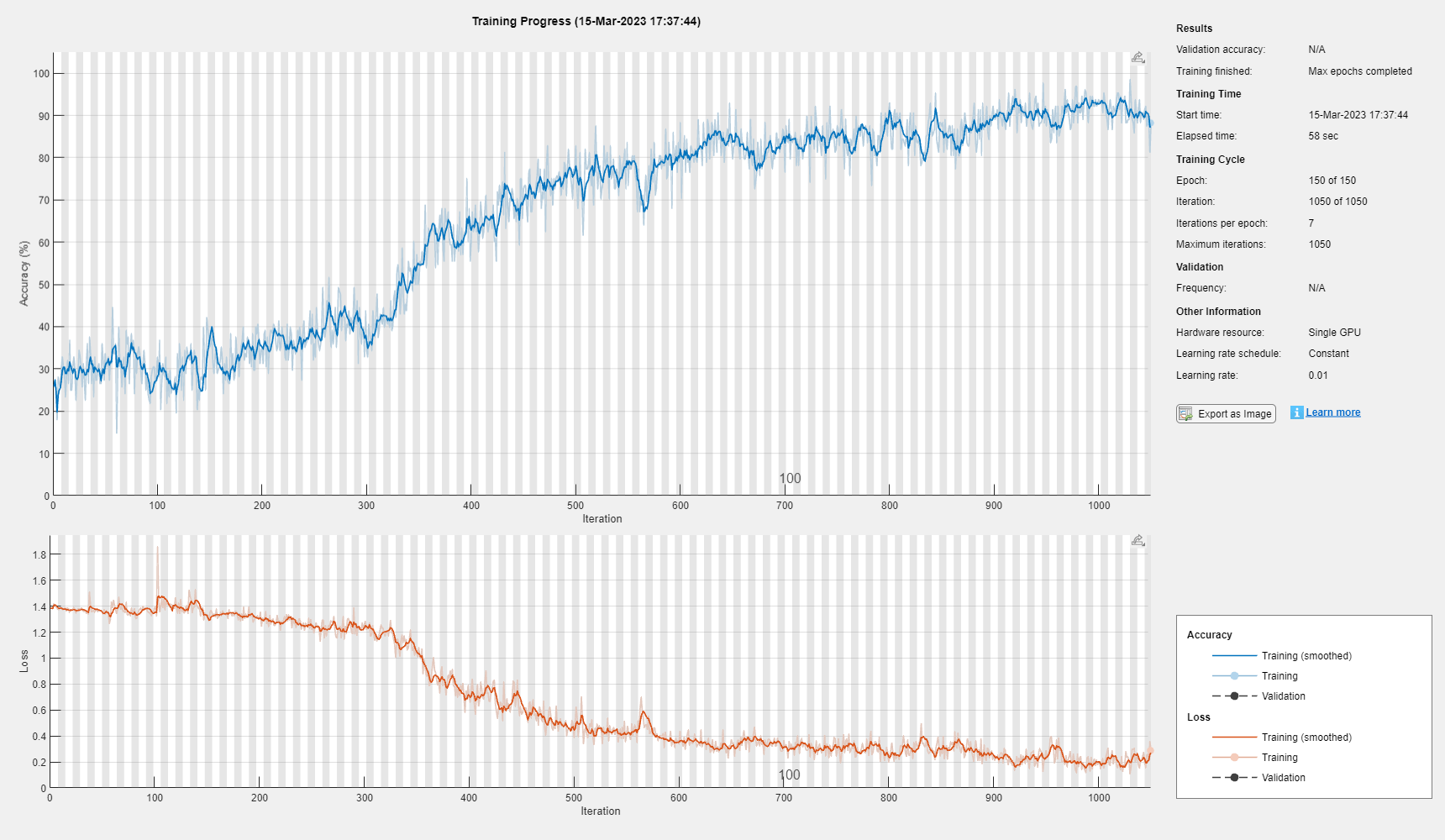
Specify the training options. Train using the Adam solver with a learn rate of 0.01 and a gradient threshold of 1. Set the maximum number of epochs to 150 and shuffle every epoch. The software, by default, trains on a GPU if one is available. Using a GPU requires Parallel Computing Toolbox™ and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox).
options = trainingOptions("adam", ... MaxEpochs=150, ... InitialLearnRate=0.01,... Shuffle="every-epoch", ... GradientThreshold=1, ... Verbose=false, ... Plots="training-progress");
Train the LSTM network with the specified training options.
net = trainNetwork(XTrain,TTrain,layers,options);
Classify the test data. Specify the same mini-batch size used for training.
YTest = classify(net,XTest);
Calculate the classification accuracy of the predictions.
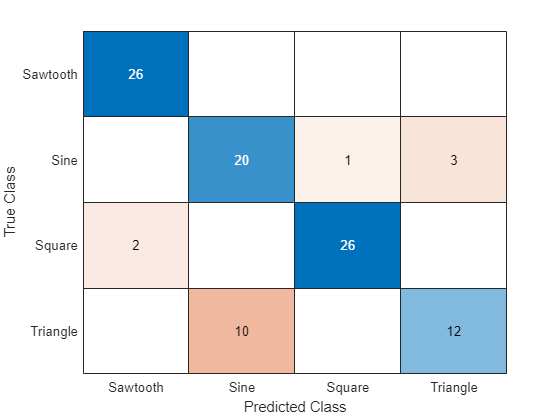
acc = mean(YTest == TTest)
acc = 0.8400
Display the classification results in a confusion chart.
figure confusionchart(TTest,YTest)
Input Arguments
Image data, specified as one of the following:
| Data Type | Description | Example Usage | |
|---|---|---|---|
| Datastore | ImageDatastore | Datastore of images saved on disk. | Train image classification neural network with images saved on disk, where the images are the same size. When the images are different
sizes, use an
|
AugmentedImageDatastore | Datastore that applies random affine geometric transformations, including resizing, rotation, reflection, shear, and translation. |
| |
TransformedDatastore | Datastore that transforms batches of data read from an underlying datastore using a custom transformation function. |
| |
CombinedDatastore | Datastore that reads from two or more underlying datastores. |
| |
RandomPatchExtractionDatastore (Image Processing Toolbox) | Datastore that extracts pairs of random patches from images or pixel label images and optionally applies identical random affine geometric transformations to the pairs. | Train neural network for object detection. | |
DenoisingImageDatastore (Image Processing Toolbox) | Datastore that applies randomly generated Gaussian noise. | Train neural network for image denoising. | |
| Custom mini-batch datastore | Custom datastore that returns mini-batches of data. | Train neural network using data in a format that other datastores do not support. For details, see Develop Custom Mini-Batch Datastore. | |
| Numeric array | Images specified as numeric array. If you specify
images as a numeric array, then you must also specify
the responses argument. | Train neural network using data that fits in memory and does not require additional processing like augmentation. | |
| Table | Images specified as a table. If you specify images as
a table, then you can also specify which columns contain
the responses using the responses
argument. | Train neural network using data stored in a table. | |
For neural networks with multiple inputs, the datastore must be a TransformedDatastore or CombinedDatastore object.
Tip
For sequences of images, for example video data, use the
sequences input argument.
Datastore
Datastores read mini-batches of images and responses. Datastores are best suited when you have data that does not fit in memory or when you want to apply augmentations or transformations to the data.
The list below lists the datastores that are directly compatible with
trainNetwork for image data.
RandomPatchExtractionDatastore(Image Processing Toolbox)DenoisingImageDatastore(Image Processing Toolbox)Custom mini-batch datastore. For details, see Develop Custom Mini-Batch Datastore.
For example, you can create an image datastore using the imageDatastore function
and use the names of the folders containing the images as labels by
setting the 'LabelSource' option to
'foldernames'. Alternatively, you can specify the
labels manually using the Labels property of the image datastore.
Tip
Use augmentedImageDatastore for efficient
preprocessing of images for deep learning, including image
resizing. Do not use the ReadFcn option of
ImageDatastore objects.
ImageDatastore allows batch reading of JPG
or PNG image files using prefetching. If you set the
ReadFcn option to a custom function, then
ImageDatastore does not prefetch and is
usually significantly slower.
You can use other built-in datastores for training deep learning
neural networks by using the transform and combine functions. These functions can convert the data
read from datastores to the format required by
trainNetwork.
For neural networks with multiple inputs, the datastore must be a
TransformedDatastore or CombinedDatastore object.
The required format of the datastore output depends on the neural network architecture.
| Neural Network Architecture | Datastore Output | Example Output |
|---|---|---|
| Single input layer | Table or cell array with two columns. The first and second columns specify the predictors and targets, respectively. Table elements must be scalars, row vectors, or 1-by-1 cell arrays containing a numeric array. Custom mini-batch datastores must output tables. | Table for neural network with one input and one output: data = read(ds) data =
4×2 table
Predictors Response
__________________ ________
{224×224×3 double} 2
{224×224×3 double} 7
{224×224×3 double} 9
{224×224×3 double} 9
|
Cell array for neural network with one input and one output: data = read(ds) data =
4×2 cell array
{224×224×3 double} {[2]}
{224×224×3 double} {[7]}
{224×224×3 double} {[9]}
{224×224×3 double} {[9]} | ||
| Multiple input layers | Cell array with ( The
first The order of
inputs is given by the | Cell array for neural network with two inputs and one output. data = read(ds) data =
4×3 cell array
{224×224×3 double} {128×128×3 double} {[2]}
{224×224×3 double} {128×128×3 double} {[2]}
{224×224×3 double} {128×128×3 double} {[9]}
{224×224×3 double} {128×128×3 double} {[9]} |
The format of the predictors depends on the type of data.
| Data | Format |
|---|---|
| 2-D images | h-by-w-by-c numeric array, where h, w, and c are the height, width, and number of channels of the images, respectively. |
| 3-D images | h-by-w-by-d-by-c numeric array, where h, w, d, and c are the height, width, depth, and number of channels of the images, respectively. |
For predictors returned in tables, the elements must contain a numeric scalar, a numeric row vector, or a 1-by-1 cell array containing the numeric array.
The format of the responses depends on the type of task.
| Task | Response Format |
|---|---|
| Image classification | Categorical scalar |
| Image regression |
|
For responses returned in tables, the elements must be a categorical scalar, a numeric scalar, a numeric row vector, or a 1-by-1 cell array containing a numeric array.
For more information, see Datastores for Deep Learning.
Numeric Array
For data that fits in memory and does not require additional
processing like augmentation, you can specify a data set of images as a
numeric array. If you specify images as a numeric array, then you must
also specify the responses argument.
The size and shape of the numeric array depends on the type of image data.
| Data | Format |
|---|---|
| 2-D images | h-by-w-by-c-by-N numeric array, where h, w, and c are the height, width, and number of channels of the images, respectively, and N is the number of images. |
| 3-D images | h-by-w-by-d-by-c-by-N numeric array, where h, w, d, and c are the height, width, depth, and number of channels of the images, respectively, and N is the number of images. |
Table
As an alternative to datastores or numeric arrays, you can also
specify images and responses in a table. If you specify images as a
table, then you can also specify which columns contain the responses
using the responses argument.
When specifying images and responses in a table, each row in the table corresponds to an observation.
For image input, the predictors must be in the first column of the table, specified as one of the following:
Absolute or relative file path to an image, specified as a character vector
1-by-1 cell array containing a h-by-w-by-c numeric array representing a 2-D image, where h, w, and c correspond to the height, width, and number of channels of the image, respectively.
The format of the responses depends on the type of task.
| Task | Response Format |
|---|---|
| Image classification | Categorical scalar |
| Image regression |
|
For neural networks with image input, if you do not specify
responses, then the function, by default, uses
the first column of tbl for the predictors and the
subsequent columns as responses.
Tip
If the predictors or the responses contains
NaNs, then they are propagated through the neural network during training. In these cases, the training usually fails to converge.For regression tasks, normalizing the responses often helps to stabilize and speed up training of neural networks for regression.
This argument supports complex-valued predictors. To train a network with complex-valued predictors using the
trainNetworkfunction, theSplitComplexInputsoption of the input layer must be1(true).
Sequence or time series data, specified as one of the following:
| Data Type | Description | Example Usage | |
|---|---|---|---|
| Datastore | TransformedDatastore | Datastore that transforms batches of data read from an underlying datastore using a custom transformation function. |
|
CombinedDatastore | Datastore that reads from two or more underlying datastores. | Combine predictors and responses from different data sources. | |
| Custom mini-batch datastore | Custom datastore that returns mini-batches of data. | Train neural network using data in a format that other datastores do not support. For details, see Develop Custom Mini-Batch Datastore. | |
| Numeric or cell array | A single sequence specified as a numeric array or a
data set of sequences specified as cell array of numeric
arrays. If you specify sequences as a numeric or cell
array, then you must also specify the
responses argument. | Train neural network using data that fits in memory and does not require additional processing like custom transformations. | |
Datastore
Datastores read mini-batches of sequences and responses. Datastores are best suited when you have data that does not fit in memory or when you want to apply transformations to the data.
The list below lists the datastores that are directly compatible with
trainNetwork for sequence data.
Custom mini-batch datastore. For details, see Develop Custom Mini-Batch Datastore.
You can use other built-in datastores for training deep learning
neural networks by using the transform and combine functions. These functions can convert the data
read from datastores to the table or cell array format required by
trainNetwork. For example, you can transform and
combine data read from in-memory arrays and CSV files using
ArrayDatastore and
TabularTextDatastore objects, respectively.
The datastore must return data in a table or cell array. Custom mini-batch datastores must output tables.
| Datastore Output | Example Output |
|---|---|
| Table |
data = read(ds) data =
4×2 table
Predictors Response
__________________ ________
{12×50 double} 2
{12×50 double} 7
{12×50 double} 9
{12×50 double} 9
|
| Cell array |
data = read(ds) data =
4×2 cell array
{12×50 double} {[2]}
{12×50 double} {[7]}
{12×50 double} {[9]}
{12×50 double} {[9]} |
The format of the predictors depend on the type of data.
| Data | Format of Predictors |
|---|---|
| Vector sequence | c-by-s matrix, where c is the number of features of the sequence and s is the sequence length. |
| 1-D image sequence | h-by-c-by-s array, where h and c correspond to the height and number of channels of the image, respectively, and s is the sequence length. Each sequence in the mini-batch must have the same sequence length. |
| 2-D image sequence | h-by-w-by-c-by-s array, where h, w, and c correspond to the height, width, and number of channels of the image, respectively, and s is the sequence length. Each sequence in the mini-batch must have the same sequence length. |
| 3-D image sequence | h-by-w-by-d-by-c-by-s array, where h, w, d, and c correspond to the height, width, depth, and number of channels of the image, respectively, and s is the sequence length. Each sequence in the mini-batch must have the same sequence length. |
For predictors returned in tables, the elements must contain a numeric scalar, a numeric row vector, or a 1-by-1 cell array containing a numeric array.
The format of the responses depends on the type of task.
| Task | Format of Responses |
|---|---|
| Sequence-to-label classification | Categorical scalar |
| Sequence-to-one regression | Scalar |
| Sequence-to-vector regression | Numeric row vector |
| Sequence-to-sequence classification |
Each sequence in the mini-batch must have the same sequence length. |
| Sequence-to-sequence regression |
Each sequence in the mini-batch must have the same sequence length. |
For responses returned in tables, the elements must be a categorical scalar, a numeric scalar, a numeric row vector, or a 1-by-1 cell array containing a numeric array.
For more information, see Datastores for Deep Learning.
Numeric or Cell Array
For data that fits in memory and does not require additional
processing like custom transformations, you can specify a single
sequence as a numeric array or a data set of sequences as a cell array
of numeric arrays. If you specify sequences as a cell or numeric array,
then you must also specify the responses
argument.
For cell array input, the cell array must be an N-by-1 cell array of numeric arrays, where N is the number of observations. The size and shape of the numeric array representing a sequence depends on the type of sequence data.
| Input | Description |
|---|---|
| Vector sequences | c-by-s matrices, where c is the number of features of the sequences and s is the sequence length. |
| 1-D image sequences | h-by-c-by-s arrays, where h and c correspond to the height and number of channels of the images, respectively, and s is the sequence length. |
| 2-D image sequences | h-by-w-by-c-by-s arrays, where h, w, and c correspond to the height, width, and number of channels of the images, respectively, and s is the sequence length. |
| 3-D image sequences | h-by-w-by-d-by-c-by-s, where h, w, d, and c correspond to the height, width, depth, and number of channels of the 3-D images, respectively, and s is the sequence length. |
The trainNetwork function supports neural networks with at most one
sequence input layer.
Tip
If the predictors or the responses contains
NaNs, then they are propagated through the neural network during training. In these cases, the training usually fails to converge.For regression tasks, normalizing the responses often helps to stabilize and speed up training.
This argument supports complex-valued predictors. To train a network with complex-valued predictors using the
trainNetworkfunction, theSplitComplexInputsoption of the input layer must be1(true).
Feature data, specified as one of the following:
| Data Type | Description | Example Usage | |
|---|---|---|---|
| Datastore | TransformedDatastore | Datastore that transforms batches of data read from an underlying datastore using a custom transformation function. |
|
CombinedDatastore | Datastore that reads from two or more underlying datastores. |
| |
| Custom mini-batch datastore | Custom datastore that returns mini-batches of data. | Train neural network using data in a format that other datastores do not support. For details, see Develop Custom Mini-Batch Datastore. | |
| Table | Feature data specified as a table. If you specify
features as a table, then you can also specify which
columns contain the responses using the
responses argument. | Train neural network using data stored in a table. | |
| Numeric array | Feature data specified as numeric array. If you
specify features as a numeric array, then you must also
specify the responses
argument. | Train neural network using data that fits in memory and does not require additional processing like custom transformations. | |
Datastore
Datastores read mini-batches of feature data and responses. Datastores are best suited when you have data that does not fit in memory or when you want to apply transformations to the data.
The list below lists the datastores that are directly compatible with
trainNetwork for feature data.
Custom mini-batch datastore. For details, see Develop Custom Mini-Batch Datastore.
You can use other built-in datastores for training deep learning
neural networks by using the transform and combine functions. These functions can convert the data
read from datastores to the table or cell array format required by
trainNetwork. For more information, see Datastores for Deep Learning.
For neural networks with multiple inputs, the datastore must be a
TransformedDatastore or CombinedDatastore object.
The datastore must return data in a table or a cell array. Custom mini-batch datastores must output tables. The format of the datastore output depends on the neural network architecture.
| Neural Network Architecture | Datastore Output | Example Output |
|---|---|---|
| Single input layer | Table or cell array with two columns. The first and second columns specify the predictors and responses, respectively. Table elements must be scalars, row vectors, or 1-by-1 cell arrays containing a numeric array. Custom mini-batch datastores must output tables. | Table for neural network with one input and one output: data = read(ds) data =
4×2 table
Predictors Response
__________________ ________
{24×1 double} 2
{24×1 double} 7
{24×1 double} 9
{24×1 double} 9
|
Cell array for neural network with one input and one output:
data = read(ds) data =
4×2 cell array
{24×1 double} {[2]}
{24×1 double} {[7]}
{24×1 double} {[9]}
{24×1 double} {[9]} | ||
| Multiple input layers | Cell array with ( The
first The order of
inputs is given by the | Cell array for neural network with two inputs and one output: data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double} {[2]}
{24×1 double} {28×1 double} {[2]}
{24×1 double} {28×1 double} {[9]}
{24×1 double} {28×1 double} {[9]} |
The predictors must be c-by-1 column vectors, where c is the number of features.
The format of the responses depends on the type of task.
| Task | Format of Responses |
|---|---|
| Classification | Categorical scalar |
| Regression |
|
For more information, see Datastores for Deep Learning.
Table
For feature data that fits in memory and does not require additional processing like custom transformations, you can specify feature data and responses as a table.
Each row in the table corresponds to an observation. The arrangement of predictors and responses in the table columns depends on the type of task.
| Task | Predictors | Responses |
|---|---|---|
| Feature classification | Features specified in one or more columns as scalars. If you do not
specify the | Categorical label |
| Feature regression | One or more columns of scalar values |
For classification neural networks with feature input, if you do not
specify the responses argument, then the function,
by default, uses the first (numColumns - 1) columns
of tbl for the predictors and the last column for
the labels, where numFeatures is the number of
features in the input data.
For regression neural networks with feature input, if you do not
specify the responseNames argument, then the
function, by default, uses the first numFeatures
columns for the predictors and the subsequent columns for the responses,
where numFeatures is the number of features in the
input data.
Numeric Array
For feature data that fits in memory and does not require additional
processing like custom transformations, you can specify feature data as
a numeric array. If you specify feature data as a numeric array, then
you must also specify the responses
argument.
The numeric array must be an
N-by-numFeatures numeric
array, where N is the number of observations and
numFeatures is the number of features of the
input data.
Tip
Normalizing the responses often helps to stabilize and speed up training of neural networks for regression.
Responses must not contain
NaNs. If the predictor data containsNaNs, then they are propagated through the training. However, in most cases, the training fails to converge.This argument supports complex-valued predictors. To train a network with complex-valued predictors using the
trainNetworkfunction, theSplitComplexInputsoption of the input layer must be1(true).
Mixed data and responses, specified as one of the following:
| Data Type | Description | Example Usage |
|---|---|---|
TransformedDatastore | Datastore that transforms batches of data read from an underlying datastore using a custom transformation function. |
|
CombinedDatastore | Datastore that reads from two or more underlying datastores. |
|
| Custom mini-batch datastore | Custom datastore that returns mini-batches of data. | Train neural network using data in a format that other datastores do not support. For details, see Develop Custom Mini-Batch Datastore. |
You can use other built-in datastores for training deep learning neural
networks by using the transform and combine functions. These functions can convert the data read
from datastores to the table or cell array format required by
trainNetwork. For more information, see Datastores for Deep Learning.
The datastore must return data in a table or a cell array. Custom mini-batch datastores must output tables. The format of the datastore output depends on the neural network architecture.
| Datastore Output | Example Output |
|---|---|
Cell array with ( The first
The order of inputs is given
by the |
data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double} {[2]}
{24×1 double} {28×1 double} {[2]}
{24×1 double} {28×1 double} {[9]}
{24×1 double} {28×1 double} {[9]} |
For image, sequence, and feature predictor input, the format of the
predictors must match the formats described in the
images, sequences, or
features argument descriptions, respectively.
Similarly, the format of the responses must match the formats described in
the images, sequences, or
features argument descriptions that corresponds to
the type of task.
The trainNetwork function supports neural networks with at most one
sequence input layer.
For an example showing how to train a neural network with multiple inputs, see Train Network on Image and Feature Data.
Tip
To convert a numeric array to a datastore, use
ArrayDatastore.When combining layers in a neural network with mixed types of data, you may need to reformat the data before passing it to a combination layer (such as a concatenation or an addition layer). To reformat the data, you can use a flatten layer to flatten the spatial dimensions into the channel dimension, or create a
FunctionLayerobject or custom layer that reformats and reshapes.This argument supports complex-valued predictors. To train a network with complex-valued predictors using the
trainNetworkfunction, theSplitComplexInputsoption of the input layer must be1(true).
Responses.
When the input data is a numeric array or a cell array, specify the responses as one of the following.
categorical vector of labels
numeric array of numeric responses
cell array of categorical or numeric sequences
When the input data is a table, you can optionally specify which columns of the table contains the responses as one of the following:
character vector
cell array of character vectors
string array
When the input data is a numeric array or a cell array, then the format of the responses depends on the type of task.
| Task | Format | |
|---|---|---|
| Classification | Image classification | N-by-1 categorical vector of labels, where N is the number of observations. |
| Feature classification | ||
| Sequence-to-label classification | ||
| Sequence-to-sequence classification | N-by-1 cell array of categorical sequences of labels, where N is the number of observations. Each sequence must have the same number of time steps as the corresponding predictor sequence. For sequence-to-sequence
classification tasks with one observation,
| |
| Regression | 2-D image regression |
|
| 3-D image regression |
| |
| Feature regression | N-by-R matrix, where N is the number of observations and R is the number of responses. | |
| Sequence-to-one regression | N-by-R matrix, where N is the number of sequences and R is the number of responses. | |
| Sequence-to-sequence regression | N-by-1 cell array of numeric sequences, where N is the number of sequences, with sequences given by one of the following:
For sequence-to-sequence
regression tasks with one observation,
| |
Tip
Normalizing the responses often helps to stabilize and speed up training of neural networks for regression.
Tip
Responses must not contain NaNs. If the predictor
data contains NaNs, then they are propagated through
the training. However, in most cases, the training fails to
converge.
Neural network layers, specified as a Layer array
or a LayerGraph
object.
To create a neural network with all layers connected sequentially, you can use a
Layer array as the input argument. In this case, the returned
neural network is a SeriesNetwork
object.
A directed acyclic graph (DAG) neural network has a complex structure in which layers
can have multiple inputs and outputs. To create a DAG neural network, specify the neural
network architecture as a LayerGraph
object and then use that layer graph as the input argument to
trainNetwork.
The trainNetwork function supports neural networks with at most one
sequence input layer.
For a list of built-in layers, see List of Deep Learning Layers.
Training options, specified as a TrainingOptionsSGDM,
TrainingOptionsRMSProp, or
TrainingOptionsADAM object returned by the trainingOptions
function.
Output Arguments
Trained neural network, returned as a SeriesNetwork object or a DAGNetwork object.
If you train the neural network using a Layer array, then
net is a SeriesNetwork object. If
you train the neural network using a LayerGraph object, then net is a
DAGNetwork object.
Training information, returned as a structure, where each field is a scalar or a numeric vector with one element per training iteration.
For classification tasks, info contains the following fields:
TrainingLoss— Loss function valuesTrainingAccuracy— Training accuraciesValidationLoss— Loss function valuesValidationAccuracy— Validation accuraciesBaseLearnRate— Learning ratesFinalValidationLoss— Validation loss of returned neural networkFinalValidationAccuracy— Validation accuracy of returned neural networkOutputNetworkIteration— Iteration number of returned neural network
For regression tasks, info contains the following fields:
TrainingLoss— Loss function valuesTrainingRMSE— Training RMSE valuesValidationLoss— Loss function valuesValidationRMSE— Validation RMSE valuesBaseLearnRate— Learning ratesFinalValidationLoss— Validation loss of returned neural networkFinalValidationRMSE— Validation RMSE of returned neural networkOutputNetworkIteration— Iteration number of returned neural network
The structure only contains the fields ValidationLoss,
ValidationAccuracy, ValidationRMSE
, FinalValidationLoss ,
FinalValidationAccuracy, and
FinalValidationRMSE when options
specifies validation data. The ValidationFrequency
training option determines which iterations the software calculates
validation metrics. The final validation metrics are scalar. The other
fields of the structure are row vectors, where each element corresponds to a
training iteration. For iterations when the software does not calculate
validation metrics, the corresponding values in the structure are
NaN.
For neural networks containing batch normalization layers, if the
BatchNormalizationStatistics training option is
'population' then the final validation metrics are
often different from the validation metrics evaluated during training. This
is because batch normalization layers in the final neural network perform
different operations than during training. For more information, see batchNormalizationLayer.
More About
Deep Learning Toolbox™ enables you to save neural networks as .mat files during training.
This periodic saving is especially useful when you have a large neural network or a
large data set, and training takes a long time. If the training is interrupted for
some reason, you can resume training from the last saved checkpoint neural network.
If you want the trainNetwork function to save checkpoint neural
networks, then you must specify the name of the path by using the
CheckpointPath option of
trainingOptions. If the path that you specify does not
exist, then trainingOptions returns an error.
The software automatically assigns unique names to checkpoint neural network
files. In the example name,
net_checkpoint__351__2018_04_12__18_09_52.mat, 351 is the
iteration number, 2018_04_12 is the date, and
18_09_52 is the time at which the software saves the neural
network. You can load a checkpoint neural network file by double-clicking it or
using the load command at the command line. For example:
load net_checkpoint__351__2018_04_12__18_09_52.mat
trainNetwork. For example:trainNetwork(XTrain,TTrain,net.Layers,options)
When you train a neural network using the trainnet or trainNetwork functions, or when you use prediction or validation functions with DAGNetwork and SeriesNetwork objects, the software performs these computations using single-precision, floating-point arithmetic. Functions for prediction and validation include predict, classify, and activations. The software uses single-precision arithmetic when you train neural networks using both CPUs and GPUs.
To provide the best performance, deep learning using a GPU in MATLAB® is not guaranteed to be deterministic. Depending on your network architecture, under some conditions you might get different results when using a GPU to train two identical networks or make two predictions using the same network and data.
Extended Capabilities
To run computation in parallel, set the ExecutionEnvironment
training option to "multi-gpu" or "parallel".
Use trainingOptions to set the
ExecutionEnvironment training option and supply the options
to trainNetwork. If you do not set
ExecutionEnvironment, then trainNetwork
runs on a GPU if available.
For details, see Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud.
To prevent out-of-memory errors, recommended practice is not to move large sets of training data onto the GPU. Instead, train your neural network on a GPU by using
trainingOptionsto set theExecutionEnvironmentto"auto"or"gpu"and supply the options totrainNetwork.The
ExecutionEnvironmentoption must be"auto"or"gpu"when the input data is:A
gpuArrayA cell array containing
gpuArrayobjectsA table containing
gpuArrayobjectsA datastore that outputs cell arrays containing
gpuArrayobjectsA datastore that outputs tables containing
gpuArrayobjects
For more information, see Run MATLAB Functions on a GPU (Parallel Computing Toolbox).
Version History
Introduced in R2016aStarting in R2024a, the trainNetwork function is not
recommended, use the trainnet function instead.
There are no plans to remove support for the trainNetwork
function. However, the trainnet function has these advantages
and is recommended instead:
trainnetsupportsdlnetworkobjects, which support a wider range of network architectures that you can create or import from external platforms.trainnetenables you to easily specify loss functions. You can select from built-in loss functions or specify a custom loss function.trainnetoutputs adlnetworkobject, which is a unified data type that supports network building, prediction, built-in training, visualization, compression, verification, and custom training loops.trainnetis typically faster thantrainNetwork.
This table shows some typical usages of the trainNetwork
function and how to update your code to use the trainnet
function instead.
| Not Recommended | Recommended |
|---|---|
net =
trainNetwork(data,layers,options); | net =
trainnet(data,layers,lossFcn,options); |
net =
trainNetwork(X,T,layers,options); | net =
trainnet(X,T,layers,lossFcn,options); |
Instead of using an output layer, specify a loss function using
lossFcn.
Starting in R2022b, when you train a neural network with sequence data using the trainNetwork function and the SequenceLength option is an integer, the software pads sequences to the
length of the longest sequence in each mini-batch and then splits the sequences into
mini-batches with the specified sequence length. If SequenceLength does
not evenly divide the sequence length of the mini-batch, then the last split mini-batch has
a length shorter than SequenceLength. This behavior prevents the neural
network training on time steps that contain only padding values.
In previous releases, the software pads mini-batches of sequences to have a length matching the nearest multiple of SequenceLength that is greater than or equal to the mini-batch length and then splits the data. To reproduce this behavior, use a custom training loop and implement this behavior when you preprocess mini-batches of data.
When you train a neural network using the trainNetwork
function, training automatically stops when the loss is NaN.
Usually, a loss value of NaN introduces NaN
values to the neural network learnable parameters, which in turn can cause the
neural network to fail to train or to make valid predictions. This change helps
identify issues with the neural network before training completes.
In previous releases, the neural network continues to train when the loss is
NaN.
When specifying sequence data for the trainNetwork function,
support for specifying tables of MAT file paths will be removed in a future
release.
To train neural networks with sequences that do not fit in memory, use a
datastore. You can use any datastore to read your data and then use the
transform function to transform the datastore output to the
format the trainNetwork function requires. For example, you can
read data using a FileDatastore or
TabularTextDatastore object then transform the output using the
transform function.
See Also
trainnet | trainingOptions | dlnetwork | minibatchpredict | scores2label | predict | analyzeNetwork | Deep Network
Designer
Topics
- Create Simple Deep Learning Neural Network for Classification
- Retrain Neural Network to Classify New Images
- Train Convolutional Neural Network for Regression
- Sequence Classification Using Deep Learning
- Train Network on Image and Feature Data
- Deep Learning in MATLAB
- Define Custom Deep Learning Layers
- List of Deep Learning Layers
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: .
You can also select a web site from the following list
How to Get Best Site Performance
Select the China site (in Chinese or English) for best site performance. Other MathWorks country sites are not optimized for visits from your location.
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)