Pretrained Deep Neural Networks
You can take a pretrained image classification neural network that has already learned to extract powerful and informative features from natural images and use it as a starting point to learn a new task. The majority of the pretrained neural networks are trained on a subset of the ImageNet database [1], which is used in the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) [17]. These neural networks have been trained on more than a million images and can classify images into 1000 object categories, such as keyboard, coffee mug, pencil, and many animals. Using a pretrained neural network with transfer learning is typically much faster and easier than training a neural network from scratch.
You can use previously trained neural networks for the following tasks:
| Purpose | Description |
|---|---|
| Classification | Apply pretrained neural networks directly to classification
problems. To classify a new images, use |
| Feature Extraction | Use a pretrained neural network as a feature extractor by using the layer activations as features. You can use these activations as features to train another machine learning model, such as a support vector machine (SVM). For more information, see Feature Extraction. For an example, see Extract Image Features Using Pretrained Network. |
| Transfer Learning | Take layers from a neural network trained on a large data set and fine-tune on a new data set. For more information, see Transfer Learning. For a simple example, see Get Started with Transfer Learning. To try more pretrained neural networks, see Retrain Neural Network to Classify New Images. |
Compare Pretrained Neural Networks
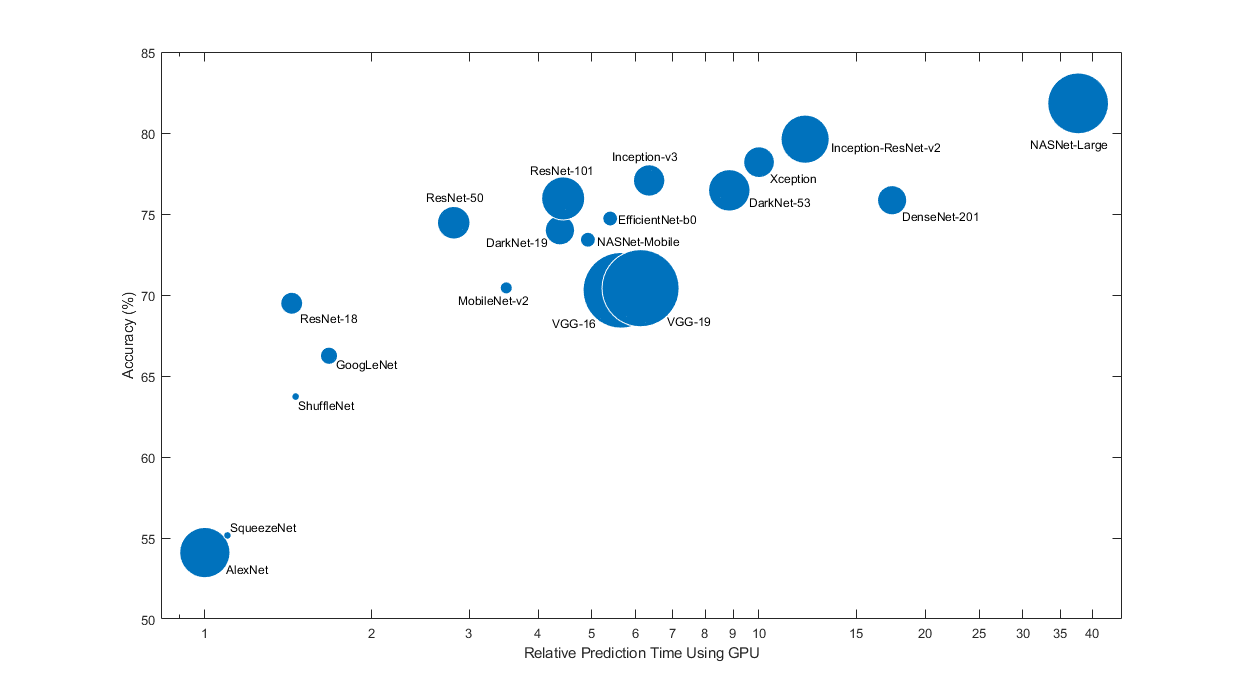
Pretrained neural networks have different characteristics that matter when choosing a neural network to apply to your problem. The most important characteristics are neural network accuracy, speed, and size. Choosing a neural network is generally a tradeoff between these characteristics. Use the plot below to compare the ImageNet validation accuracy with the time required to make a prediction using the neural network.
Tip
To get started with transfer learning, try choosing one of the faster neural networks, such as SqueezeNet or GoogLeNet. You can then iterate quickly and try out different settings such as data preprocessing steps and training options. Once you have a feeling of which settings work well, try a more accurate neural network such as Inception-v3 or a ResNet and see if that improves your results.
Note
The plot above only shows an indication of the relative speeds of the different neural networks. The exact prediction and training iteration times depend on the hardware and mini-batch size that you use.
A good neural network has a high accuracy and is fast. The plot displays the classification accuracy versus the prediction time when using a modern GPU (an NVIDIA® Tesla® P100) and a mini-batch size of 128. The prediction time is measured relative to the fastest neural network. The area of each marker is proportional to the size of the neural network on disk.
The classification accuracy on the ImageNet validation set is the most common way to measure the accuracy of neural networks trained on ImageNet. Neural networks that are accurate on ImageNet are also often accurate when you apply them to other natural image data sets using transfer learning or feature extraction. This generalization is possible because the neural networks have learned to extract powerful and informative features from natural images that generalize to other similar data sets. However, high accuracy on ImageNet does not always transfer directly to other tasks, so it is a good idea to try multiple neural networks.
If you want to perform prediction using constrained hardware or distribute neural networks over the Internet, then also consider the size of the neural network on disk and in memory.
Neural Network Accuracy
There are multiple ways to calculate the classification accuracy on the ImageNet validation set and different sources use different methods. Sometimes an ensemble of multiple models is used and sometimes each image is evaluated multiple times using multiple crops. Sometimes the top-5 accuracy instead of the standard (top-1) accuracy is quoted. Because of these differences, it is often not possible to directly compare the accuracies from different sources. The accuracies of pretrained neural networks in Deep Learning Toolbox™ are standard (top-1) accuracies using a single model and single central image crop.
Load Pretrained Neural Networks
To load the SqueezeNet neural network, use the imagePretrainedNetwork function.
[net,classNames] = imagePretrainedNetwork;
For other neural networks, specify the model using the first argument of the
imagePretrainedNetwork function. If you do not have the
required support package for the network, the function provides a link to download it.
Alternatively, you can download the pretrained neural networks from the Add-On Explorer.
This table lists the available pretrained neural networks trained on ImageNet and some of their properties. The neural network depth is defined as the largest number of sequential convolutional or fully connected layers on a path from the network input to the network output. The inputs to all neural networks are RGB images.
imagePretrainedNetwork Model
Name Argument | Neural Network Name | Depth | Parameter Memory | Parameters (Millions) | Image Input Size | Input Value Range | Input Layer Normalization | Required Support Package |
|---|---|---|---|---|---|---|---|---|
"squeezenet" | SqueezeNet [2] | 18 | 4.7 MB | 1.24 | 227-by-227 | [0, 255] | "zerocenter" | None |
"googlenet" | GoogLeNet [3][4] | 22 | 27 MB | 7.0 | 224-by-224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for GoogLeNet Network |
"googlenet-places365" | 24 MB | 6.3 | 224-by-224 | [0, 255] | "zerocenter" | |||
"inceptionv3" | Inception-v3 [5] | 48 | 91 MB | 23.9 | 299-by-299 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for Inception-v3 Network |
"densenet201" | DenseNet-201 [6] | 201 | 77 MB | 20.0 | 224-by-224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for DenseNet-201 Network |
"mobilenetv2" | MobileNet-v2 [7] | 53 | 14 MB | 3.5 | 224-by-224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for MobileNet-v2 Network |
"resnet18" | ResNet-18 [8] | 18 | 45 MB | 11.7 | 224-by-224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for ResNet-18 Network |
"resnet50" | ResNet-50 [8] | 50 | 98 MB | 25.6 | 224-by-224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for ResNet-50 Network |
"resnet101" | ResNet-101 [8] | 101 | 171 MB | 44.6 | 224-by-224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for ResNet-101 Network |
"xception" | Xception [9] | 71 | 88 MB | 22.9 | 299-by-299 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for Xception Network |
"inceptionresnetv2" | Inception-ResNet-v2 [10] | 164 | 213 MB | 55.9 | 299-by-299 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for Inception-ResNet-v2 Network |
"shufflenet" | ShuffleNet [11] | 50 | 5.5 MB | 1.4 | 224-by-224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for ShuffleNet Network |
"nasnetmobile" | NASNet-Mobile [12] | * | 20 MB | 5.3 | 224-by-224 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for NASNet-Mobile Network |
"nasnetlarge" | NASNet-Large [12] | * | 340 MB | 88.9 | 331-by-331 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for NASNet-Large Network |
"darknet19" | DarkNet-19 [13] | 19 | 80 MB | 20.8 | 256-by-256 | [0, 255] | "rescale-zero-one" | Deep Learning Toolbox Model for DarkNet-19 Network |
"darknet53" | DarkNet-53 [13] | 53 | 159 MB | 41.6 | 256-by-256 | [0, 255] | "rescale-zero-one" | Deep Learning Toolbox Model for DarkNet-53 Network |
"efficientnetb0" | EfficientNet-b0 [14] | 82 | 20 MB | 5.3 | 224-by-224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for EfficientNet-b0 Network |
"alexnet" | AlexNet [15] | 8 | 233 MB | 61.0 | 227-by-227 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for AlexNet Network |
"vgg16" | VGG-16 [16] | 16 | 528 MB | 138 | 224-by-224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for VGG-16 Network |
"vgg19" | VGG-19 [16] | 19 | 548 MB | 144 | 224-by-224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for VGG-19 Network |
*The NASNet-Mobile and NASNet-Large neural networks do not consist of a linear sequence of modules.
GoogLeNet Trained on Places365
The standard GoogLeNet neural network is trained on the ImageNet data set but you
can also load a neural network trained on the Places365 data set [18]
[4]. The neural network
trained on Places365 classifies images into 365 different place categories, such as
field, park, runway, and lobby. To load a pretrained GoogLeNet neural network
trained on the Places365 data set, use
imagePretrainedNetwork("googlenet-places365"). When you
perform transfer learning for a new task, the most common approach is to use neural
networks pretrained on ImageNet. If the new task is similar to classifying scenes,
then using the neural network trained on Places365 can give higher
accuracies.
For information about pretrained neural networks suitable for audio tasks, see Pretrained Neural Networks for Audio Applications.
Visualize Pretrained Neural Networks
You can load and visualize pretrained neural networks using Deep Network Designer.
[net,classNames] = imagePretrainedNetwork; deepNetworkDesigner(net)
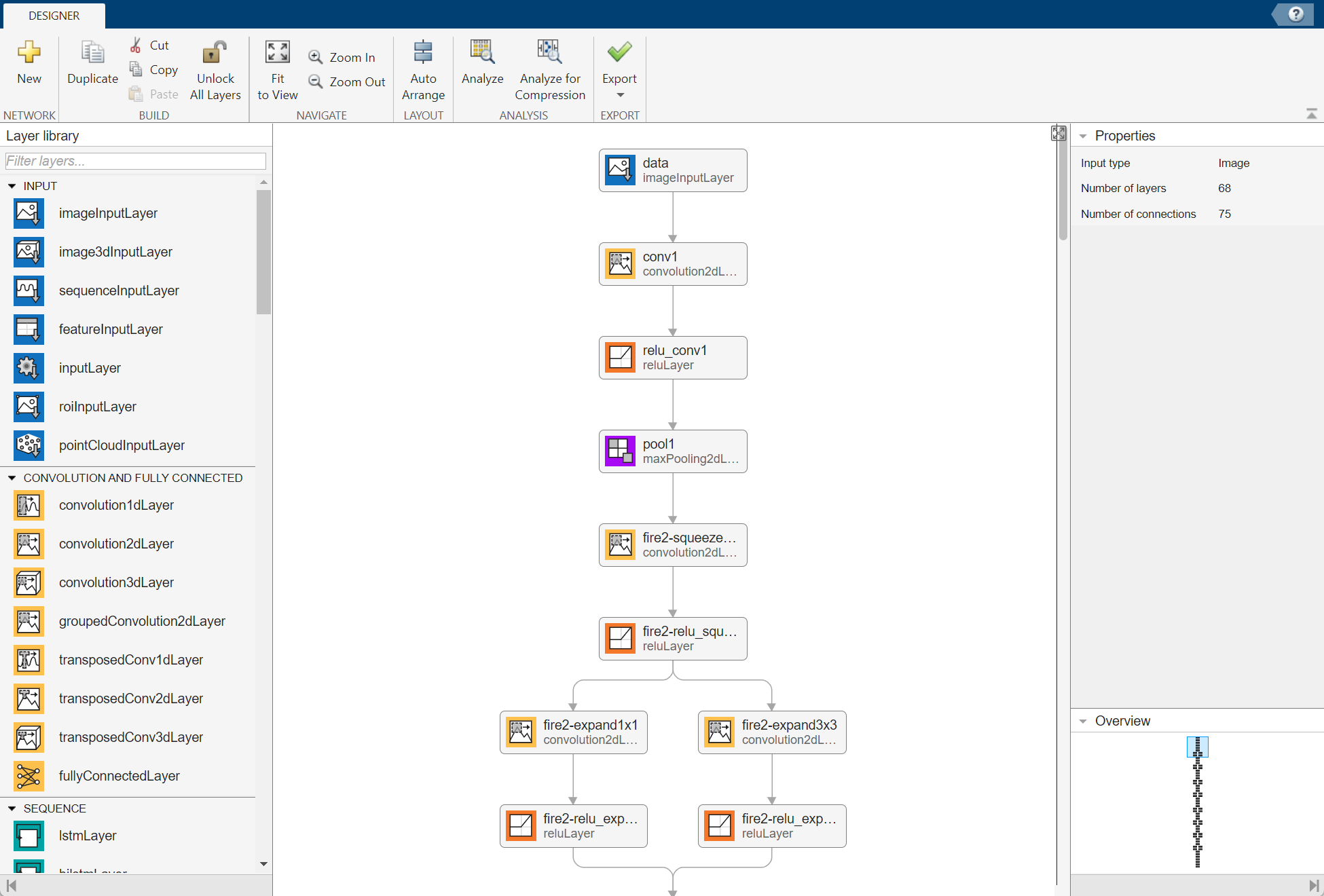
To view and edit layer properties, select a layer. Click the help icon next to the layer name for information on the layer properties.
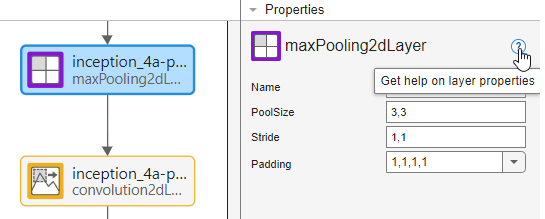
Explore other pretrained neural networks in Deep Network Designer by clicking New.
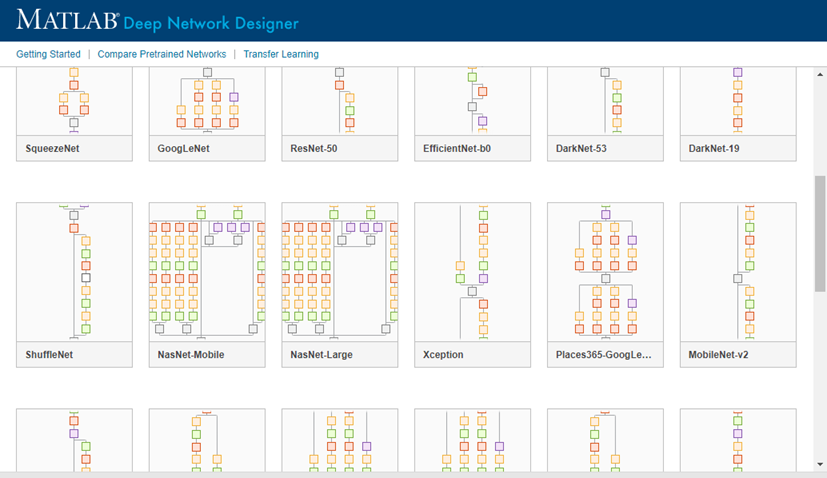
If you need to download a neural network, pause on the desired neural network and click Install to open the Add-On Explorer.
Feature Extraction
Feature extraction is an easy and fast way to use the power of deep learning without
investing time and effort into training a full neural network. Because it only requires
a single pass over the training images, it is especially useful if you do not have a
GPU. You extract learned image features using a pretrained neural network, and then use
those features to train a classifier, such as a support vector machine using fitcsvm (Statistics and Machine Learning Toolbox).
Try feature extraction when your new data set is very small. Since you only train a simple classifier on the extracted features, training is fast. It is also unlikely that fine-tuning deeper layers of the neural network improves the accuracy since there is little data to learn from.
If your data is very similar to the original data, then the more specific features extracted deeper in the neural network are likely to be useful for the new task.
If your data is very different from the original data, then the features extracted deeper in the neural network might be less useful for your task. Try training the final classifier on more general features extracted from an earlier neural network layer. If the new data set is large, then you can also try training a neural network from scratch.
ResNet neural networks are often good feature extractors. For an example showing how to use a pretrained neural network for feature extraction, see Extract Image Features Using Pretrained Network.
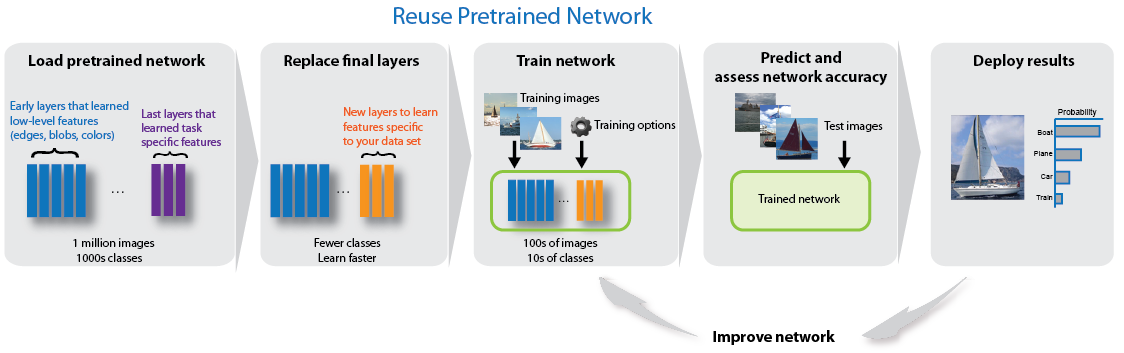
Transfer Learning
You can fine-tune deeper layers in the neural network by training the neural network on your new data set with the pretrained neural network as a starting point. Fine-tuning a neural network with transfer learning is often faster and easier than constructing and training a new neural network. The neural network has already learned a rich set of image features, but when you fine-tune the neural network it can learn features specific to your new data set. If you have a very large data set, then transfer learning might not be faster than training from scratch.
Tip
Fine-tuning a neural network often gives the highest accuracy. For very small data sets (fewer than about 20 images per class), try feature extraction instead.
Fine-tuning a neural network is slower and requires more effort than simple feature extraction, but since the neural network can learn to extract a different set of features, the final neural network is often more accurate. Fine-tuning usually works better than feature extraction as long as the new data set is not very small, because then the neural network has data to learn new features from. For examples showing how to perform transfer learning, see Prepare Network for Transfer Learning Using Deep Network Designer and Retrain Neural Network to Classify New Images.
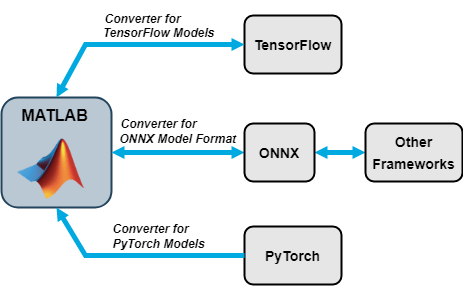
Import and Export Neural Networks
You can import neural networks from TensorFlow™ 2, TensorFlow-Keras, Keras 3, PyTorch®, and the ONNX™ (Open Neural Network Exchange) model format. You can also export Deep Learning Toolbox neural networks to TensorFlow 2 and the ONNX model format.
Tip
You can import models from external platforms using the Deep Network Designer app. On import, the app shows an import report with details about any issues that require attention.
Import Functions
| External Deep Learning Platform and Model Format | Import Model as dlnetwork |
|---|---|
TensorFlow neural network, TensorFlow-Keras neural network in SavedModel format,
or Keras 3 neural network | Deep
Network Designer or importNetworkFromTensorFlow or importNetworkFromKeras |
Traced PyTorch model in a .pt file | Deep
Network Designer or importNetworkFromPyTorch |
| Neural network in ONNX model format | importNetworkFromONNX |
When importing a network, the software automatically generates custom layers when you import a model with TensorFlow layers, PyTorch layers, or ONNX operators that the software cannot convert to built-in MATLAB® layers. The software saves the automatically generated custom layers to a package in the current folder. For more information, see Autogenerated Custom Layers.
Export Functions
| External Deep Learning Platform and Model Format | Export Neural Network or Layer Graph |
|---|---|
| TensorFlow 2 model in Python® package | exportNetworkToTensorFlow |
| ONNX model format | exportONNXNetwork |
The exportNetworkToTensorFlow function saves a Deep Learning Toolbox neural network as a TensorFlow model in a Python package. For more information on how to load the exported model and save it in
SavedModel format, see Load Exported TensorFlow Model and Save TensorFlow Model.
By using ONNX as an intermediate format, you can interoperate with other deep learning frameworks that support ONNX model export or import.
Pretrained Neural Networks for Audio Applications
Audio Toolbox™ provides MATLAB and Simulink® support for pretrained audio deep learning networks. Use pretrained networks to classify sounds with YAMNet, estimate pitch with CREPE, extract feature embeddings with VGGish or OpenL3, and perform voice activity detection (VAD) with VADNet. You can also import and visualize audio pretrained neural networks using Deep Network Designer.
Use the audioPretrainedNetwork (Audio Toolbox) function to load a pretrained audio network. You can
also use one of the end-to-end functions that handle the preprocessing the audio, network
inference, and postprocessing the network output. This table lists the available pretrained
audio neural networks.
audioPretrainedNetwork Model Name
Argument | Neural Network Name | Preprocessing and Postprocessing Functions | End-to-End Function | Simulink Blocks |
|---|---|---|---|---|
"yamnet" | YAMNet | yamnetPreprocess (Audio Toolbox) | classifySound (Audio Toolbox) | YAMNet (Audio Toolbox), Sound Classifier (Audio Toolbox) |
"vggish" | VGGish | vggishPreprocess (Audio Toolbox) | vggishEmbeddings (Audio Toolbox) | VGGish (Audio Toolbox), VGGish Embeddings (Audio Toolbox) |
"openl3" | OpenL3 | openl3Preprocess (Audio Toolbox) | openl3Embeddings (Audio Toolbox) | OpenL3 (Audio Toolbox), OpenL3 Embeddings (Audio Toolbox) |
"crepe" | CREPE | crepePreprocess (Audio Toolbox), crepePostprocess (Audio Toolbox) | pitchnn (Audio Toolbox) | CREPE (Audio Toolbox), Deep Pitch Estimator (Audio Toolbox) |
"vadnet" | VADNet | vadnetPreprocess (Audio Toolbox), vadnetPostprocess (Audio Toolbox) | detectspeechnn (Audio Toolbox) | None |
For examples showing how to adapt pretrained audio neural networks for a new task, see Transfer Learning with Pretrained Audio Networks (Audio Toolbox) and Adapt Pretrained Audio Network for New Data Using Deep Network Designer.
For more information on using deep learning for audio applications, see Deep Learning for Audio Applications (Audio Toolbox).
Pretrained Neural Networks for Computer Vision Applications
Computer Vision Toolbox™ provides MATLAB support for pretrained deep learning networks for object detection. Use pretrained networks to perform out-of-the-box inference on a test image or transfer learning on a custom data set. You can also import and visualize pretrained neural networks for object detection using the Deep Network Designer app.
To use a pretrained object detection network, download and install the required support package. You can download and install a pretrained model support package using the Add-On Explorer. For more information about installing Add-Ons, see Get and Manage Add-Ons.
Use an object detection model, such as yoloxObjectDetector (Computer Vision Toolbox), to specify the corresponding pretrained network to
use for object detection. To select an object detection model, see Choose an Object Detector (Computer Vision Toolbox). To learn more
about object detection, see Get Started with Object Detection Using Deep Learning (Computer Vision Toolbox).
| Pretrained Object Detection Network Name Arguments | Object Detection Model | Required Support Package |
|---|---|---|
| YOLO v2 – | Computer Vision Toolbox Model for YOLO v2 Object Detection |
| YOLO v3 – | Computer Vision Toolbox Model for YOLO v3 Object Detection |
| YOLO v4 – | Computer Vision Toolbox Model for YOLO v4 Object Detection |
| YOLOX – | Automated Visual Inspection Library for Computer Vision Toolbox |
| RTMDet – | Computer Vision Toolbox Model for RTMDet Object Detection |
Pretrained Models on GitHub
To find the latest pretrained models, see MATLAB Deep Learning Model Hub.
For example:
For text-based transformer models, such as GPT-2, BERT, and FinBERT, see the Transformer Models for MATLAB GitHub® repository.
For a pretrained EfficientDet-D0 object detection model, see the Pretrained EfficientDet Network For Object Detection GitHub repository.
References
[1] ImageNet. http://www.image-net.org.
[2] Iandola, Forrest N., Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. “SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size.” Preprint, submitted November 4, 2016. https://arxiv.org/abs/1602.07360.
[3] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. “Going Deeper with Convolutions.” In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9. Boston, MA, USA: IEEE, 2015. https://doi.org/10.1109/CVPR.2015.7298594.
[4] Places. http://places2.csail.mit.edu/
[5] Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. “Rethinking the Inception Architecture for Computer Vision.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2818–26. Las Vegas, NV, USA: IEEE, 2016. https://doi.org/10.1109/CVPR.2016.308.
[6] Huang, Gao, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. “Densely Connected Convolutional Networks.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2261–69. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.243.
[7] Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–20. Salt Lake City, UT: IEEE, 2018. https://doi.org/10.1109/CVPR.2018.00474.
[8] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep Residual Learning for Image Recognition.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–78. Las Vegas, NV, USA: IEEE, 2016. https://doi.org/10.1109/CVPR.2016.90.
[9] Chollet, François. “Xception: Deep Learning with Depthwise Separable Convolutions.” Preprint, submitted in 2016. https://doi.org/10.48550/ARXIV.1610.02357.
[10] Szegedy, Christian, Sergey Ioffe, Vincent Vanhoucke, and Alexander Alemi. “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.” Proceedings of the AAAI Conference on Artificial Intelligence 31, no. 1 (February 12, 2017). https://doi.org/10.1609/aaai.v31i1.11231.
[11] Zhang, Xiangyu, Xinyu Zhou, Mengxiao Lin, and Jian Sun. “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices.” Preprint, submitted July 4, 2017. http://arxiv.org/abs/1707.01083.
[12] Zoph, Barret, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. “Learning Transferable Architectures for Scalable Image Recognition.” Preprint, submitted in 2017. https://doi.org/10.48550/ARXIV.1707.07012.
[13] Redmon, Joseph. “Darknet: Open Source Neural Networks in C.” https://pjreddie.com/darknet.
[14] Tan, Mingxing, and Quoc V. Le. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” Preprint, submitted in 2019. https://doi.org/10.48550/ARXIV.1905.11946.
[15] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "ImageNet Classification with Deep Convolutional Neural Networks." Communications of the ACM 60, no. 6 (May 24, 2017): 84–90. https://doi.org/10.1145/3065386.
[16] Simonyan, Karen, and Andrew Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” Preprint, submitted in 2014. https://doi.org/10.48550/ARXIV.1409.1556.
[17] Russakovsky, O., Deng, J., Su, H., et al. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision (IJCV). Vol 115, Issue 3, 2015, pp. 211–252
[18] Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Antonio Torralba, and Aude Oliva. "Places: An image database for deep scene understanding." arXiv preprint arXiv:1610.02055 (2016).
See Also
Deep Network
Designer | imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | importNetworkFromTensorFlow | importNetworkFromPyTorch | importNetworkFromONNX | exportNetworkToTensorFlow | exportONNXNetwork
Topics
- Deep Learning in MATLAB
- Prepare Network for Transfer Learning Using Deep Network Designer
- Extract Image Features Using Pretrained Network
- Classify Image Using GoogLeNet
- Retrain Neural Network to Classify New Images
- Visualize Features of a Convolutional Neural Network
- Visualize Activations of a Convolutional Neural Network
- Deep Dream Images Using GoogLeNet